 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing on Language: Revealing and Exploiting Language Attention Heads in Multilingual Large Language Models
Nov 10, 2025Large language models (LLMs) increasingly support multilingual understanding and generation. Meanwhile, efforts to interpret their internal mechanisms have emerged, offering insights to enhance multilingual performance. While multi-head self-attention (MHA) has proven critical in many areas, its role in multilingual capabilities remains underexplored. In this work, we study the contribution of MHA in supporting multilingual processing in LLMs. We propose Language Attention Head Importance Scores (LAHIS), an effective and efficient method that identifies attention head importance for multilingual capabilities via a single forward and backward pass through the LLM. Applying LAHIS to Aya-23-8B, Llama-3.2-3B, and Mistral-7B-v0.1, we reveal the existence of both language-specific and language-general heads. Language-specific heads enable cross-lingual attention transfer to guide the model toward target language contexts and mitigate off-target language generation issue, contributing to addressing challenges in multilingual LLMs. We also introduce a lightweight adaptation that learns a soft head mask to modulate attention outputs over language heads, requiring only 20 tunable parameters to improve XQuAD accuracy. Overall, our work enhances both the interpretability and multilingual capabilities of LLMs from the perspective of MHA.
PointAD+: Learning Hierarchical Representations for Zero-shot 3D Anomaly Detection
Sep 03, 2025In this paper, we aim to transfer CLIP's robust 2D generalization capabilities to identify 3D anomalies across unseen objects of highly diverse class semantics. To this end, we propose a unified framework to comprehensively detect and segment 3D anomalies by leveraging both point- and pixel-level information. We first design PointAD, which leverages point-pixel correspondence to represent 3D anomalies through their associated rendering pixel representations. This approach is referred to as implicit 3D representation, as it focuses solely on rendering pixel anomalies but neglects the inherent spatial relationships within point clouds. Then, we propose PointAD+ to further broaden the interpretation of 3D anomalies by introducing explicit 3D representation, emphasizing spatial abnormality to uncover abnormal spatial relationships. Hence, we propose G-aggregation to involve geometry information to enable the aggregated point representations spatially aware. To simultaneously capture rendering and spatial abnormality, PointAD+ proposes hierarchical representation learning, incorporating implicit and explicit anomaly semantics into hierarchical text prompts: rendering prompts for the rendering layer and geometry prompts for the geometry layer. A cross-hierarchy contrastive alignment is further introduced to promote the interaction between the rendering and geometry layers, facilitating mutual anomaly learning. Finally, PointAD+ integrates anomaly semantics from both layers to capture the generalized anomaly semantics. During the test, PointAD+ can integrate RGB information in a plug-and-play manner and further improve its detection performance. Extensive experiments demonstrate the superiority of PointAD+ in ZS 3D anomaly detection across unseen objects with highly diverse class semantics, achieving a holistic understanding of abnormality.
KunLunBaizeRAG: Reinforcement Learning Driven Inference Performance Leap for Large Language Models
Jun 24, 2025This paper introduces KunLunBaizeRAG, a reinforcement learning-driven reasoning framework designed to enhance the reasoning capabilities of large language models (LLMs) in complex multi-hop question-answering tasks. The framework addresses key limitations of traditional RAG, such as retrieval drift, information redundancy, and strategy rigidity. Key innovations include the RAG-driven Reasoning Alignment (RDRA) mechanism, the Search-Think Iterative Enhancement (STIE) mechanism, the Network-Local Intelligent Routing (NLR) mechanism, and a progressive hybrid training strategy. Experimental results demonstrate significant improvements in exact match (EM) and LLM-judged score (LJ) across four benchmarks, highlighting the framework's robustness and effectiveness in complex reasoning scenarios.
Prefill-Based Jailbreak: A Novel Approach of Bypassing LLM Safety Boundary
Apr 28, 2025Large Language Models (LLMs) are designed to generate helpful and safe content. However, adversarial attacks, commonly referred to as jailbreak, can bypass their safety protocols, prompting LLMs to generate harmful content or reveal sensitive data. Consequently, investigating jailbreak methodologies is crucial for exposing systemic vulnerabilities within LLMs, ultimately guiding the continuous implementation of security enhancements by developers. In this paper, we introduce a novel jailbreak attack method that leverages the prefilling feature of LLMs, a feature designed to enhance model output constraints. Unlike traditional jailbreak methods, the proposed attack circumvents LLMs' safety mechanisms by directly manipulating the probability distribution of subsequent tokens, thereby exerting control over the model's output. We propose two attack variants: Static Prefilling (SP), which employs a universal prefill text, and Optimized Prefilling (OP), which iteratively optimizes the prefill text to maximize the attack success rate. Experiments on six state-of-the-art LLMs using the AdvBench benchmark validate the effectiveness of our method and demonstrate its capability to substantially enhance attack success rates when combined with existing jailbreak approaches. The OP method achieved attack success rates of up to 99.82% on certain models, significantly outperforming baseline methods. This work introduces a new jailbreak attack method in LLMs, emphasizing the need for robust content validation mechanisms to mitigate the adversarial exploitation of prefilling features. All code and data used in this paper are publicly available.
FairDD: Fair Dataset Distillation via Synchronized Matching
Nov 29, 2024



Condensing large datasets into smaller synthetic counterparts has demonstrated its promise for image classification. However, previous research has overlooked a crucial concern in image recognition: ensuring that models trained on condensed datasets are unbiased towards protected attributes (PA), such as gender and race. Our investigation reveals that dataset distillation (DD) fails to alleviate the unfairness towards minority groups within original datasets. Moreover, this bias typically worsens in the condensed datasets due to their smaller size. To bridge the research gap, we propose a novel fair dataset distillation (FDD) framework, namely FairDD, which can be seamlessly applied to diverse matching-based DD approaches, requiring no modifications to their original architectures. The key innovation of FairDD lies in synchronously matching synthetic datasets to PA-wise groups of original datasets, rather than indiscriminate alignment to the whole distributions in vanilla DDs, dominated by majority groups. This synchronized matching allows synthetic datasets to avoid collapsing into majority groups and bootstrap their balanced generation to all PA groups. Consequently, FairDD could effectively regularize vanilla DDs to favor biased generation toward minority groups while maintaining the accuracy of target attributes. Theoretical analyses and extensive experimental evaluations demonstrate that FairDD significantly improves fairness compared to vanilla DD methods, without sacrificing classification accuracy. Its consistent superiority across diverse DDs, spanning Distribution and Gradient Matching, establishes it as a versatile FDD approach.
Large Language Model Guided Knowledge Distillation for Time Series Anomaly Detection
Jan 26, 2024Self-supervised methods have gained prominence in time series anomaly detection due to the scarcity of available annotations. Nevertheless, they typically demand extensive training data to acquire a generalizable representation map, which conflicts with scenarios of a few available samples, thereby limiting their performance. To overcome the limitation, we propose \textbf{AnomalyLLM}, a knowledge distillation-based time series anomaly detection approach where the student network is trained to mimic the features of the large language model (LLM)-based teacher network that is pretrained on large-scale datasets. During the testing phase, anomalies are detected when the discrepancy between the features of the teacher and student networks is large. To circumvent the student network from learning the teacher network's feature of anomalous samples, we devise two key strategies. 1) Prototypical signals are incorporated into the student network to consolidate the normal feature extraction. 2) We use synthetic anomalies to enlarge the representation gap between the two networks. AnomalyLLM demonstrates state-of-the-art performance on 15 datasets, improving accuracy by at least 14.5\% in the UCR dataset.
Label-Free Multivariate Time Series Anomaly Detection
Dec 17, 2023Anomaly detection in multivariate time series (MTS) has been widely studied in one-class classification (OCC) setting. The training samples in OCC are assumed to be normal, which is difficult to guarantee in practical situations. Such a case may degrade the performance of OCC-based anomaly detection methods which fit the training distribution as the normal distribution. In this paper, we propose MTGFlow, an unsupervised anomaly detection approach for MTS anomaly detection via dynamic Graph and entity-aware normalizing Flow. MTGFlow first estimates the density of the entire training samples and then identifies anomalous instances based on the density of the test samples within the fitted distribution. This relies on a widely accepted assumption that anomalous instances exhibit more sparse densities than normal ones, with no reliance on the clean training dataset. However, it is intractable to directly estimate the density due to complex dependencies among entities and their diverse inherent characteristics. To mitigate this, we utilize the graph structure learning model to learn interdependent and evolving relations among entities, which effectively captures complex and accurate distribution patterns of MTS. In addition, our approach incorporates the unique characteristics of individual entities by employing an entity-aware normalizing flow. This enables us to represent each entity as a parameterized normal distribution. Furthermore, considering that some entities present similar characteristics, we propose a cluster strategy that capitalizes on the commonalities of entities with similar characteristics, resulting in more precise and detailed density estimation. We refer to this cluster-aware extension as MTGFlow_cluster. Extensive experiments are conducted on six widely used benchmark datasets, in which MTGFlow and MTGFlow cluster demonstrate their superior detection performance.
AnomalyCLIP: Object-agnostic Prompt Learning for Zero-shot Anomaly Detection
Nov 03, 2023



Zero-shot anomaly detection (ZSAD) requires detection models trained using auxiliary data to detect anomalies without any training sample in a target dataset. It is a crucial task when training data is not accessible due to various concerns, \eg, data privacy, yet it is challenging since the models need to generalize to anomalies across different domains where the appearance of foreground objects, abnormal regions, and background features, such as defects/tumors on different products/organs, can vary significantly. Recently large pre-trained vision-language models (VLMs), such as CLIP, have demonstrated strong zero-shot recognition ability in various vision tasks, including anomaly detection. However, their ZSAD performance is weak since the VLMs focus more on modeling the class semantics of the foreground objects rather than the abnormality/normality in the images. In this paper we introduce a novel approach, namely AnomalyCLIP, to adapt CLIP for accurate ZSAD across different domains. The key insight of AnomalyCLIP is to learn object-agnostic text prompts that capture generic normality and abnormality in an image regardless of its foreground objects. This allows our model to focus on the abnormal image regions rather than the object semantics, enabling generalized normality and abnormality recognition on diverse types of objects. Large-scale experiments on 17 real-world anomaly detection datasets show that AnomalyCLIP achieves superior zero-shot performance of detecting and segmenting anomalies in datasets of highly diverse class semantics from various defect inspection and medical imaging domains. Code will be made available at https://github.com/zqhang/AnomalyCLIP.
MTGFlow: Unsupervised Multivariate Time Series Anomaly Detection via Dynamic Graph and Entity-aware Normalizing Flow
Aug 03, 2022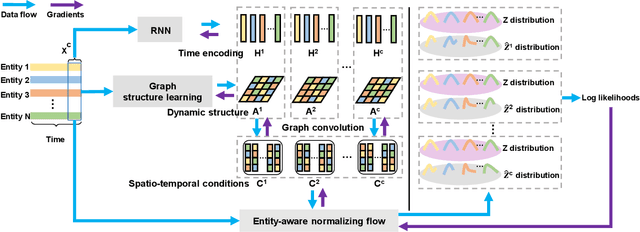

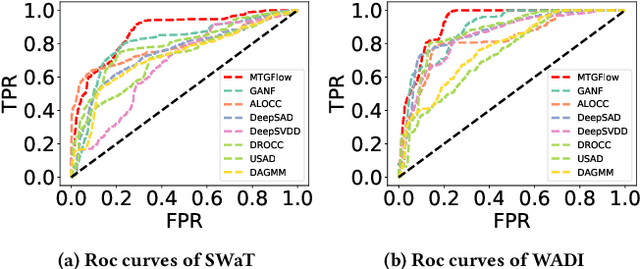

Multivariate time series anomaly detection has been extensively studied under the semi-supervised setting, where a training dataset with all normal instances is required. However, preparing such a dataset is very laborious since each single data instance should be fully guaranteed to be normal. It is, therefore, desired to explore multivariate time series anomaly detection methods based on the dataset without any label knowledge. In this paper, we propose MTGFlow, an unsupervised anomaly detection approach for Multivariate Time series anomaly detection via dynamic Graph and entity-aware normalizing Flow, leaning only on a widely accepted hypothesis that abnormal instances exhibit sparse densities than the normal. However, the complex interdependencies among entities and the diverse inherent characteristics of each entity pose significant challenges on the density estimation, let alone to detect anomalies based on the estimated possibility distribution. To tackle these problems, we propose to learn the mutual and dynamic relations among entities via a graph structure learning model, which helps to model accurate distribution of multivariate time series. Moreover, taking account of distinct characteristics of the individual entities, an entity-aware normalizing flow is developed to describe each entity into a parameterized normal distribution, thereby producing fine-grained density estimation. Incorporating these two strategies, MTGFlowachieves superior anomaly detection performance. Experiments on the real-world datasets are conducted, demonstrating that MTGFlow outperforms the state-of-the-art (SOTA) by 5.0% and 1.6% AUROC for SWaT and WADI datasets respectively. Also, through the anomaly scores contributed by individual entities, MTGFlow can provide explanation information for the detection results.