 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom ChatGPT, DALL-E 3 to Sora: How has Generative AI Changed Digital Humanities Research and Services?
Apr 29, 2024Generative large-scale language models create the fifth paradigm of scientific research, organically combine data science and computational intelligence, transform the research paradigm of natural language processing and multimodal information processing, promote the new trend of AI-enabled social science research, and provide new ideas for digital humanities research and application. This article profoundly explores the application of large-scale language models in digital humanities research, revealing their significant potential in ancient book protection, intelligent processing, and academic innovation. The article first outlines the importance of ancient book resources and the necessity of digital preservation, followed by a detailed introduction to developing large-scale language models, such as ChatGPT, and their applications in document management, content understanding, and cross-cultural research. Through specific cases, the article demonstrates how AI can assist in the organization, classification, and content generation of ancient books. Then, it explores the prospects of AI applications in artistic innovation and cultural heritage preservation. Finally, the article explores the challenges and opportunities in the interaction of technology, information, and society in the digital humanities triggered by AI technologies.
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
SsciBERT: A Pre-trained Language Model for Social Science Texts
Jun 11, 2022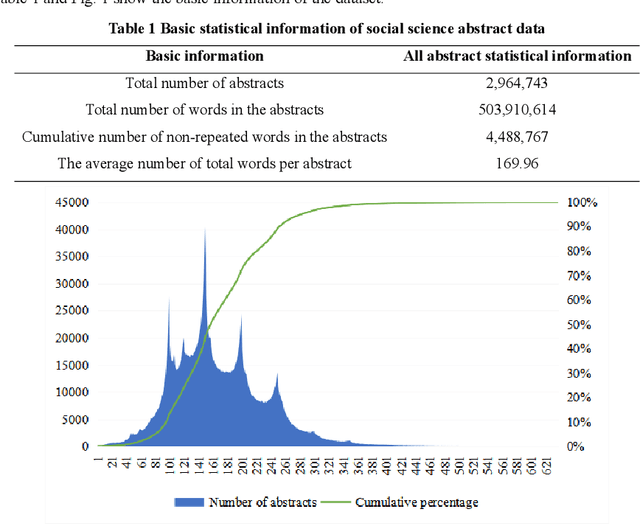
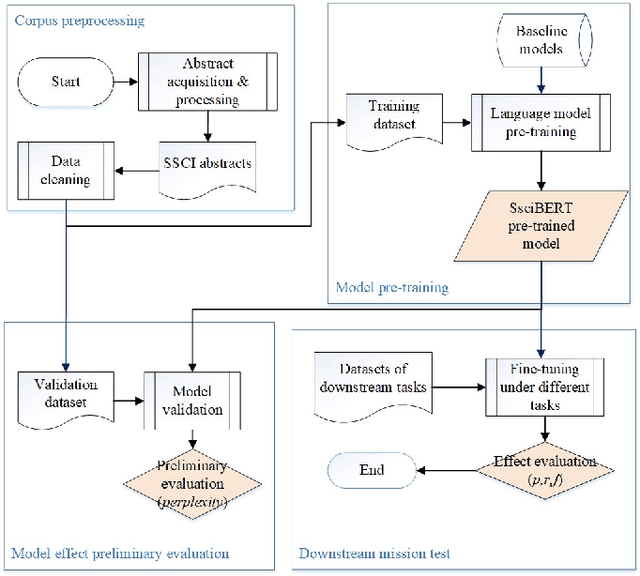


The academic literature of social sciences is the literature that records human civilization and studies human social problems. With the large-scale growth of this literature, ways to quickly find existing research on relevant issues have become an urgent demand for researchers. Previous studies, such as SciBERT, have shown that pre-training using domain-specific texts can improve the performance of natural language processing tasks in those fields. However, there is no pre-trained language model for social sciences, so this paper proposes a pre-trained model on many abstracts published in the Social Science Citation Index (SSCI) journals. The models, which are available on Github (https://github.com/S-T-Full-Text-Knowledge-Mining/SSCI-BERT), show excellent performance on discipline classification and abstract structure-function recognition tasks with the social sciences literature.