 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisEdu-RAG: A Misconception-Aware Dual-Hypergraph RAG for Novice Math Teachers
Apr 05, 2026Novice math teachers often encounter students' mistakes that are difficult to diagnose and remediate. Misconceptions are especially challenging because teachers must explain what went wrong and how to solve them. Although many existing large language model (LLM) platforms can assist in generating instructional feedback, these LLMs loosely connect pedagogical knowledge and student mistakes, which might make the guidance less actionable for teachers. To address this gap, we propose MisEdu-RAG, a dual-hypergraph-based retrieval-augmented generation (RAG) framework that organizes pedagogical knowledge as a concept hypergraph and real student mistake cases as an instance hypergraph. Given a query, MisEdu-RAG performs a two-stage retrieval to gather connected evidence from both layers and generates a response grounded in the retrieved cases and pedagogical principles. We evaluate on \textit{MisstepMath}, a dataset of math mistakes paired with teacher solutions, as a benchmark for misconception-aware retrieval and response generation across topics and error types. Evaluation results on \textit{MisstepMath} show that, compared with baseline models, MisEdu-RAG improves token-F1 by 10.95\% and yields up to 15.3\% higher five-dimension response quality, with the largest gains on \textit{Diversity} and \textit{Empowerment}. To verify its applicability in practical use, we further conduct a pilot study through a questionnaire survey of 221 teachers and interviews with 6 novices. The findings suggest that MisEdu-RAG provides diagnosis results and concrete teaching moves for high-demand misconception scenarios. Overall, MisEdu-RAG demonstrates strong potential for scalable teacher training and AI-assisted instruction for misconception handling. Our code is available on GitHub: https://github.com/GEMLab-HKU/MisEdu-RAG.
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Multi-granularity Backprojection Transformer for Remote Sensing Image Super-Resolution
Oct 19, 2023Backprojection networks have achieved promising super-resolution performance for nature images but not well be explored in the remote sensing image super-resolution (RSISR) field due to the high computation costs. In this paper, we propose a Multi-granularity Backprojection Transformer termed MBT for RSISR. MBT incorporates the backprojection learning strategy into a Transformer framework. It consists of Scale-aware Backprojection-based Transformer Layers (SPTLs) for scale-aware low-resolution feature learning and Context-aware Backprojection-based Transformer Blocks (CPTBs) for hierarchical feature learning. A backprojection-based reconstruction module (PRM) is also introduced to enhance the hierarchical features for image reconstruction. MBT stands out by efficiently learning low-resolution features without excessive modules for high-resolution processing, resulting in lower computational resources. Experiment results on UCMerced and AID datasets demonstrate that MBT obtains state-of-the-art results compared to other leading methods.
Cross-Spatial Pixel Integration and Cross-Stage Feature Fusion Based Transformer Network for Remote Sensing Image Super-Resolution
Jul 06, 2023



Remote sensing image super-resolution (RSISR) plays a vital role in enhancing spatial detials and improving the quality of satellite imagery. Recently, Transformer-based models have shown competitive performance in RSISR. To mitigate the quadratic computational complexity resulting from global self-attention, various methods constrain attention to a local window, enhancing its efficiency. Consequently, the receptive fields in a single attention layer are inadequate, leading to insufficient context modeling. Furthermore, while most transform-based approaches reuse shallow features through skip connections, relying solely on these connections treats shallow and deep features equally, impeding the model's ability to characterize them. To address these issues, we propose a novel transformer architecture called Cross-Spatial Pixel Integration and Cross-Stage Feature Fusion Based Transformer Network (SPIFFNet) for RSISR. Our proposed model effectively enhances global cognition and understanding of the entire image, facilitating efficient integration of features cross-stages. The model incorporates cross-spatial pixel integration attention (CSPIA) to introduce contextual information into a local window, while cross-stage feature fusion attention (CSFFA) adaptively fuses features from the previous stage to improve feature expression in line with the requirements of the current stage. We conducted comprehensive experiments on multiple benchmark datasets, demonstrating the superior performance of our proposed SPIFFNet in terms of both quantitative metrics and visual quality when compared to state-of-the-art methods.
Stochastic Neural Networks with Infinite Width are Deterministic
Jan 30, 2022
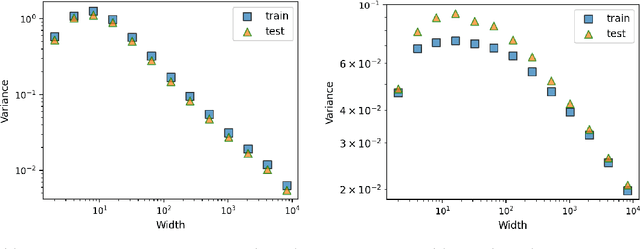

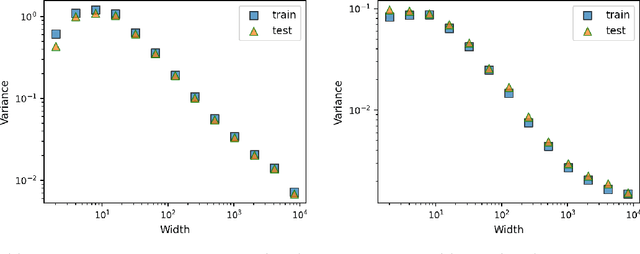
This work theoretically studies stochastic neural networks, a main type of neural network in use. Specifically, we prove that as the width of an optimized stochastic neural network tends to infinity, its predictive variance on the training set decreases to zero. Two common examples that our theory applies to are neural networks with dropout and variational autoencoders. Our result helps better understand how stochasticity affects the learning of neural networks and thus design better architectures for practical problems.
From Noise to Feature: Exploiting Intensity Distribution as a Novel Soft Biometric Trait for Finger Vein Recognition
Dec 15, 2021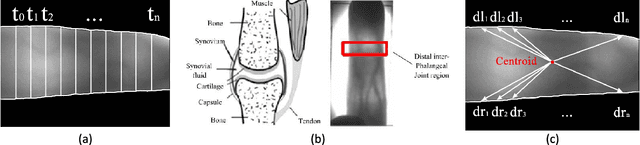
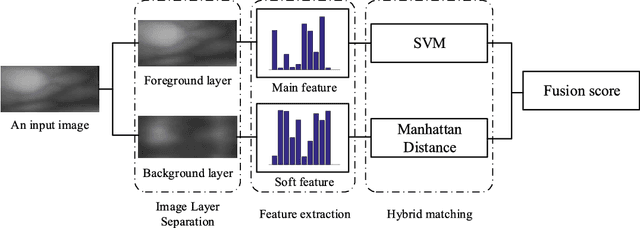
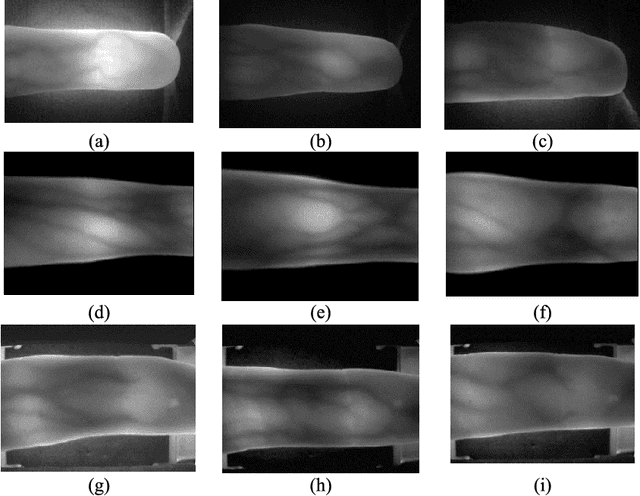

Most finger vein feature extraction algorithms achieve satisfactory performance due to their texture representation abilities, despite simultaneously ignoring the intensity distribution that is formed by the finger tissue, and in some cases, processing it as background noise. In this paper, we exploit this kind of noise as a novel soft biometric trait for achieving better finger vein recognition performance. First, a detailed analysis of the finger vein imaging principle and the characteristics of the image are presented to show that the intensity distribution that is formed by the finger tissue in the background can be extracted as a soft biometric trait for recognition. Then, two finger vein background layer extraction algorithms and three soft biometric trait extraction algorithms are proposed for intensity distribution feature extraction. Finally, a hybrid matching strategy is proposed to solve the issue of dimension difference between the primary and soft biometric traits on the score level. A series of rigorous contrast experiments on three open-access databases demonstrates that our proposed method is feasible and effective for finger vein recognition.
* 11 pages