 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Aware World Model Predictive Control for Generalizable End-to-End Autonomous Driving
Feb 26, 2026With advances in imitation learning (IL) and large-scale driving datasets, end-to-end autonomous driving (E2E-AD) has made great progress recently. Currently, IL-based methods have become a mainstream paradigm: models rely on standard driving behaviors given by experts, and learn to minimize the discrepancy between their actions and expert actions. However, this objective of "only driving like the expert" suffers from limited generalization: when encountering rare or unseen long-tail scenarios outside the distribution of expert demonstrations, models tend to produce unsafe decisions in the absence of prior experience. This raises a fundamental question: Can an E2E-AD system make reliable decisions without any expert action supervision? Motivated by this, we propose a unified framework named Risk-aware World Model Predictive Control (RaWMPC) to address this generalization dilemma through robust control, without reliance on expert demonstrations. Practically, RaWMPC leverages a world model to predict the consequences of multiple candidate actions and selects low-risk actions through explicit risk evaluation. To endow the world model with the ability to predict the outcomes of risky driving behaviors, we design a risk-aware interaction strategy that systematically exposes the world model to hazardous behaviors, making catastrophic outcomes predictable and thus avoidable. Furthermore, to generate low-risk candidate actions at test time, we introduce a self-evaluation distillation method to distill riskavoidance capabilities from the well-trained world model into a generative action proposal network without any expert demonstration. Extensive experiments show that RaWMPC outperforms state-of-the-art methods in both in-distribution and out-of-distribution scenarios, while providing superior decision interpretability.
Information-Theoretic Multi-Model Fusion for Target-Oriented Adaptive Sampling in Materials Design
Feb 03, 2026Target-oriented discovery under limited evaluation budgets requires making reliable progress in high-dimensional, heterogeneous design spaces where each new measurement is costly, whether experimental or high-fidelity simulation. We present an information-theoretic framework for target-oriented adaptive sampling that reframes optimization as trajectory discovery: instead of approximating the full response surface, the method maintains and refines a low-entropy information state that concentrates search on target-relevant directions. The approach couples data, model beliefs, and physics/structure priors through dimension-aware information budgeting, adaptive bootstrapped distillation over a heterogeneous surrogate reservoir, and structure-aware candidate manifold analysis with Kalman-inspired multi-model fusion to balance consensus-driven exploitation and disagreement-driven exploration. Evaluated under a single unified protocol without dataset-specific tuning, the framework improves sample efficiency and reliability across 14 single- and multi-objective materials design tasks spanning candidate pools from $600$ to $4 \times 10^6$ and feature dimensions from $10$ to $10^3$, typically reaching top-performing regions within 100 evaluations. Complementary 20-dimensional synthetic benchmarks (Ackley, Rastrigin, Schwefel) further demonstrate robustness to rugged and multimodal landscapes.
Open-World Deepfake Attribution via Confidence-Aware Asymmetric Learning
Dec 14, 2025The proliferation of synthetic facial imagery has intensified the need for robust Open-World DeepFake Attribution (OW-DFA), which aims to attribute both known and unknown forgeries using labeled data for known types and unlabeled data containing a mixture of known and novel types. However, existing OW-DFA methods face two critical limitations: 1) A confidence skew that leads to unreliable pseudo-labels for novel forgeries, resulting in biased training. 2) An unrealistic assumption that the number of unknown forgery types is known *a priori*. To address these challenges, we propose a Confidence-Aware Asymmetric Learning (CAL) framework, which adaptively balances model confidence across known and novel forgery types. CAL mainly consists of two components: Confidence-Aware Consistency Regularization (CCR) and Asymmetric Confidence Reinforcement (ACR). CCR mitigates pseudo-label bias by dynamically scaling sample losses based on normalized confidence, gradually shifting the training focus from high- to low-confidence samples. ACR complements this by separately calibrating confidence for known and novel classes through selective learning on high-confidence samples, guided by their confidence gap. Together, CCR and ACR form a mutually reinforcing loop that significantly improves the model's OW-DFA performance. Moreover, we introduce a Dynamic Prototype Pruning (DPP) strategy that automatically estimates the number of novel forgery types in a coarse-to-fine manner, removing the need for unrealistic prior assumptions and enhancing the scalability of our methods to real-world OW-DFA scenarios. Extensive experiments on the standard OW-DFA benchmark and a newly extended benchmark incorporating advanced manipulations demonstrate that CAL consistently outperforms previous methods, achieving new state-of-the-art performance on both known and novel forgery attribution.
TRUST-Planner: Topology-guided Robust Trajectory Planner for AAVs with Uncertain Obstacle Spatial-temporal Avoidance
Aug 20, 2025

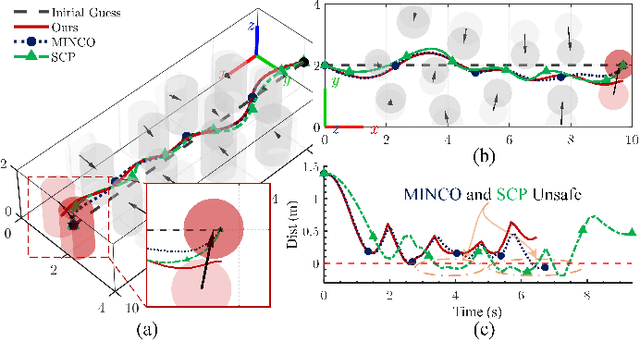

Despite extensive developments in motion planning of autonomous aerial vehicles (AAVs), existing frameworks faces the challenges of local minima and deadlock in complex dynamic environments, leading to increased collision risks. To address these challenges, we present TRUST-Planner, a topology-guided hierarchical planning framework for robust spatial-temporal obstacle avoidance. In the frontend, a dynamic enhanced visible probabilistic roadmap (DEV-PRM) is proposed to rapidly explore topological paths for global guidance. The backend utilizes a uniform terminal-free minimum control polynomial (UTF-MINCO) and dynamic distance field (DDF) to enable efficient predictive obstacle avoidance and fast parallel computation. Furthermore, an incremental multi-branch trajectory management framework is introduced to enable spatio-temporal topological decision-making, while efficiently leveraging historical information to reduce replanning time. Simulation results show that TRUST-Planner outperforms baseline competitors, achieving a 96\% success rate and millisecond-level computation efficiency in tested complex environments. Real-world experiments further validate the feasibility and practicality of the proposed method.
Differential Flatness-based Fast Trajectory Planning for Fixed-wing Unmanned Aerial Vehicles
Dec 02, 2024
Due to the strong nonlinearity and nonholonomic dynamics, despite that various general trajectory optimization methods have been presented, few of them can guarantee efficient compu-tation and physical feasibility for relatively complicated fixed-wing UAV dynamics. Aiming at this issue, this paper investigates a differential flatness-based trajectory optimization method for fixed-wing UAVs (DFTO-FW), which transcribes the trajectory optimization into a lightweight, unconstrained, gradient-analytical optimization with linear time complexity in each itera-tion to achieve fast trajectory generation. Through differential flat characteristics analysis and polynomial parameterization, the customized trajectory representation is presented, which implies the equality constraints to avoid the heavy computational burdens of solving complex dynamics. Through the design of integral performance costs and deduction of analytical gradients, the original trajectory optimization is transcribed into an uncon-strained, gradient-analytical optimization with linear time com-plexity to further improve efficiency. The simulation experi-ments illustrate the superior efficiency of the DFTO-FW, which takes sub-second CPU time against other competitors by orders of magnitude to generate fixed-wing UAV trajectories in ran-domly generated obstacle environments.
Deep Image Harmonization with Globally Guided Feature Transformation and Relation Distillation
Aug 01, 2023



Given a composite image, image harmonization aims to adjust the foreground illumination to be consistent with background. Previous methods have explored transforming foreground features to achieve competitive performance. In this work, we show that using global information to guide foreground feature transformation could achieve significant improvement. Besides, we propose to transfer the foreground-background relation from real images to composite images, which can provide intermediate supervision for the transformed encoder features. Additionally, considering the drawbacks of existing harmonization datasets, we also contribute a ccHarmony dataset which simulates the natural illumination variation. Extensive experiments on iHarmony4 and our contributed dataset demonstrate the superiority of our method. Our ccHarmony dataset is released at https://github.com/bcmi/Image-Harmonization-Dataset-ccHarmony.
Cross-Spatial Pixel Integration and Cross-Stage Feature Fusion Based Transformer Network for Remote Sensing Image Super-Resolution
Jul 06, 2023



Remote sensing image super-resolution (RSISR) plays a vital role in enhancing spatial detials and improving the quality of satellite imagery. Recently, Transformer-based models have shown competitive performance in RSISR. To mitigate the quadratic computational complexity resulting from global self-attention, various methods constrain attention to a local window, enhancing its efficiency. Consequently, the receptive fields in a single attention layer are inadequate, leading to insufficient context modeling. Furthermore, while most transform-based approaches reuse shallow features through skip connections, relying solely on these connections treats shallow and deep features equally, impeding the model's ability to characterize them. To address these issues, we propose a novel transformer architecture called Cross-Spatial Pixel Integration and Cross-Stage Feature Fusion Based Transformer Network (SPIFFNet) for RSISR. Our proposed model effectively enhances global cognition and understanding of the entire image, facilitating efficient integration of features cross-stages. The model incorporates cross-spatial pixel integration attention (CSPIA) to introduce contextual information into a local window, while cross-stage feature fusion attention (CSFFA) adaptively fuses features from the previous stage to improve feature expression in line with the requirements of the current stage. We conducted comprehensive experiments on multiple benchmark datasets, demonstrating the superior performance of our proposed SPIFFNet in terms of both quantitative metrics and visual quality when compared to state-of-the-art methods.
Hierarchical Explanations for Video Action Recognition
Jan 04, 2023



We propose Hierarchical ProtoPNet: an interpretable network that explains its reasoning process by considering the hierarchical relationship between classes. Different from previous methods that explain their reasoning process by dissecting the input image and finding the prototypical parts responsible for the classification, we propose to explain the reasoning process for video action classification by dissecting the input video frames on multiple levels of the class hierarchy. The explanations leverage the hierarchy to deal with uncertainty, akin to human reasoning: When we observe water and human activity, but no definitive action it can be recognized as the water sports parent class. Only after observing a person swimming can we definitively refine it to the swimming action. Experiments on ActivityNet and UCF-101 show performance improvements while providing multi-level explanations.
Inharmonious Region Localization by Magnifying Domain Discrepancy
Sep 30, 2022
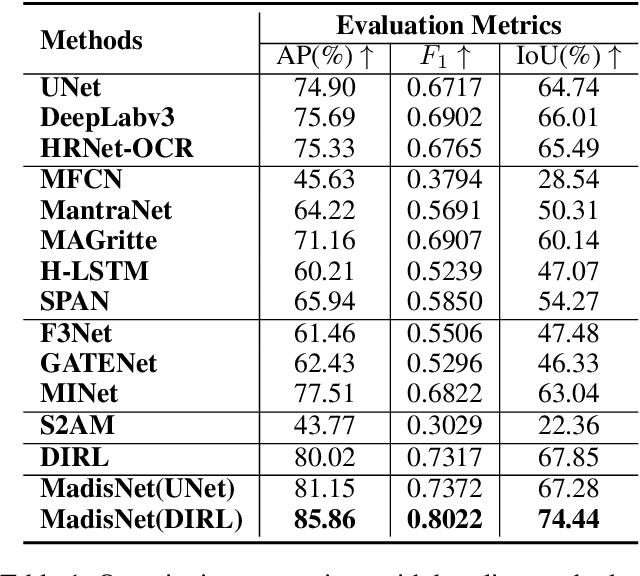
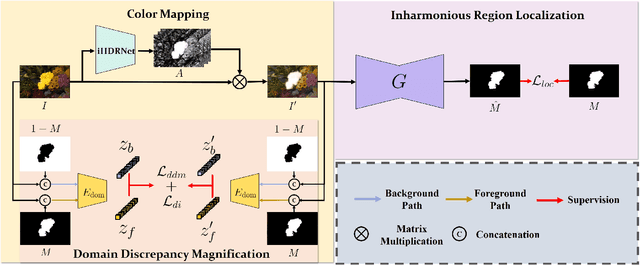
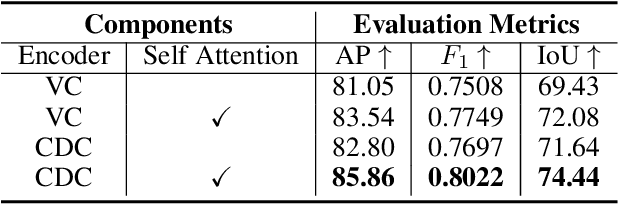
Inharmonious region localization aims to localize the region in a synthetic image which is incompatible with surrounding background. The inharmony issue is mainly attributed to the color and illumination inconsistency produced by image editing techniques. In this work, we tend to transform the input image to another color space to magnify the domain discrepancy between inharmonious region and background, so that the model can identify the inharmonious region more easily. To this end, we present a novel framework consisting of a color mapping module and an inharmonious region localization network, in which the former is equipped with a novel domain discrepancy magnification loss and the latter could be an arbitrary localization network. Extensive experiments on image harmonization dataset show the superiority of our designed framework. Our code is available at https://github.com/bcmi/MadisNet-Inharmonious-Region-Localization.
Visible Watermark Removal via Self-calibrated Localization and Background Refinement
Aug 08, 2021



Superimposing visible watermarks on images provides a powerful weapon to cope with the copyright issue. Watermark removal techniques, which can strengthen the robustness of visible watermarks in an adversarial way, have attracted increasing research interest. Modern watermark removal methods perform watermark localization and background restoration simultaneously, which could be viewed as a multi-task learning problem. However, existing approaches suffer from incomplete detected watermark and degraded texture quality of restored background. Therefore, we design a two-stage multi-task network to address the above issues. The coarse stage consists of a watermark branch and a background branch, in which the watermark branch self-calibrates the roughly estimated mask and passes the calibrated mask to background branch to reconstruct the watermarked area. In the refinement stage, we integrate multi-level features to improve the texture quality of watermarked area. Extensive experiments on two datasets demonstrate the effectiveness of our proposed method.