 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident in a Confidence Score: Investigating the Sensitivity of Confidence Scores to Supervised Fine-Tuning
Apr 10, 2026Uncertainty quantification is a set of techniques that measure confidence in language models. They can be used, for example, to detect hallucinations or alert users to review uncertain predictions. To be useful, these confidence scores must be correlated with the quality of the output. However, recent work found that fine-tuning can affect the correlation between confidence scores and quality. Hence, we investigate the underlying behavior of confidence scores to understand its sensitivity to supervised fine-tuning (SFT). We find that post-SFT, the correlation of various confidence scores degrades, which can stem from changes in confidence scores due to factors other than the output quality, such as the output's similarity to the training distribution. We demonstrate via a case study how failing to address this miscorrelation reduces the usefulness of the confidence scores on a downstream task. Our findings show how confidence metrics cannot be used off-the-shelf without testing, and motivate the need for developing metrics which are more robust to fine-tuning.
Testing the Assumptions of Active Learning for Translation Tasks with Few Samples
Apr 10, 2026Active learning (AL) is a training paradigm for selecting unlabeled samples for annotation to improve model performance on a test set, which is useful when only a limited number of samples can be annotated. These algorithms often work by optimizing for the informativeness and diversity of the training data to be annotated. Recent work found that AL strategies fail to outperform random sampling on various language generation tasks when using 100-500 samples. To understand AL's poor performance when only using few samples, we investigate whether the core assumptions underlying AL strategies hold. We find that neither the informativeness nor diversity of the training data, which AL strategies optimize for, are correlated with test set performance. Instead, factors like the ordering of the training samples and interactions with pre-training data have a larger impact on performance. This suggests that future AL methods must take these factors into account in order to work with very few samples.
Neither Valid nor Reliable? Investigating the Use of LLMs as Judges
Aug 25, 2025
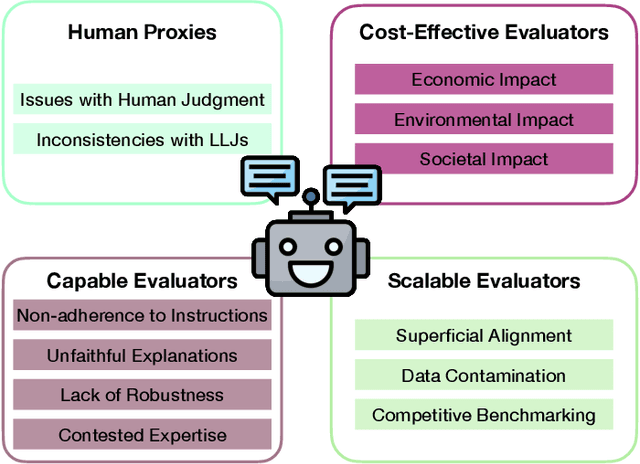


Evaluating natural language generation (NLG) systems remains a core challenge of natural language processing (NLP), further complicated by the rise of large language models (LLMs) that aims to be general-purpose. Recently, large language models as judges (LLJs) have emerged as a promising alternative to traditional metrics, but their validity remains underexplored. This position paper argues that the current enthusiasm around LLJs may be premature, as their adoption has outpaced rigorous scrutiny of their reliability and validity as evaluators. Drawing on measurement theory from the social sciences, we identify and critically assess four core assumptions underlying the use of LLJs: their ability to act as proxies for human judgment, their capabilities as evaluators, their scalability, and their cost-effectiveness. We examine how each of these assumptions may be challenged by the inherent limitations of LLMs, LLJs, or current practices in NLG evaluation. To ground our analysis, we explore three applications of LLJs: text summarization, data annotation, and safety alignment. Finally, we highlight the need for more responsible evaluation practices in LLJs evaluation, to ensure that their growing role in the field supports, rather than undermines, progress in NLG.
$(RSA)^2$: A Rhetorical-Strategy-Aware Rational Speech Act Framework for Figurative Language Understanding
Jun 10, 2025Figurative language (e.g., irony, hyperbole, understatement) is ubiquitous in human communication, resulting in utterances where the literal and the intended meanings do not match. The Rational Speech Act (RSA) framework, which explicitly models speaker intentions, is the most widespread theory of probabilistic pragmatics, but existing implementations are either unable to account for figurative expressions or require modeling the implicit motivations for using figurative language (e.g., to express joy or annoyance) in a setting-specific way. In this paper, we introduce the Rhetorical-Strategy-Aware RSA $(RSA)^2$ framework which models figurative language use by considering a speaker's employed rhetorical strategy. We show that $(RSA)^2$ enables human-compatible interpretations of non-literal utterances without modeling a speaker's motivations for being non-literal. Combined with LLMs, it achieves state-of-the-art performance on the ironic split of PragMega+, a new irony interpretation dataset introduced in this study.
Can LLMs Reason Abstractly Over Math Word Problems Without CoT? Disentangling Abstract Formulation From Arithmetic Computation
May 29, 2025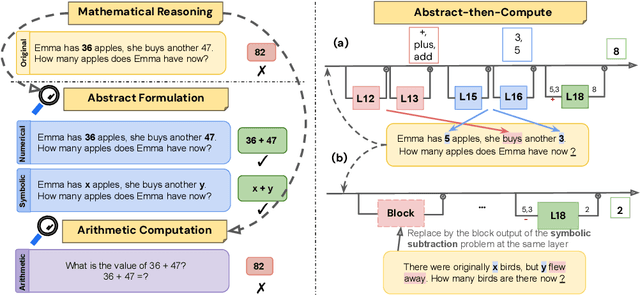

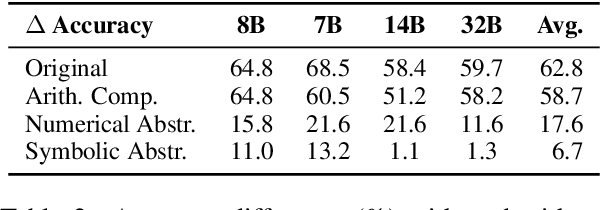
Final-answer-based metrics are commonly used for evaluating large language models (LLMs) on math word problems, often taken as proxies for reasoning ability. However, such metrics conflate two distinct sub-skills: abstract formulation (capturing mathematical relationships using expressions) and arithmetic computation (executing the calculations). Through a disentangled evaluation on GSM8K and SVAMP, we find that the final-answer accuracy of Llama-3 and Qwen2.5 (1B-32B) without CoT is overwhelmingly bottlenecked by the arithmetic computation step and not by the abstract formulation step. Contrary to the common belief, we show that CoT primarily aids in computation, with limited impact on abstract formulation. Mechanistically, we show that these two skills are composed conjunctively even in a single forward pass without any reasoning steps via an abstract-then-compute mechanism: models first capture problem abstractions, then handle computation. Causal patching confirms these abstractions are present, transferable, composable, and precede computation. These behavioural and mechanistic findings highlight the need for disentangled evaluation to accurately assess LLM reasoning and to guide future improvements.
Stochastic Chameleons: Irrelevant Context Hallucinations Reveal Class-Based (Mis)Generalization in LLMs
May 28, 2025The widespread success of large language models (LLMs) on NLP benchmarks has been accompanied by concerns that LLMs function primarily as stochastic parrots that reproduce texts similar to what they saw during pre-training, often erroneously. But what is the nature of their errors, and do these errors exhibit any regularities? In this work, we examine irrelevant context hallucinations, in which models integrate misleading contextual cues into their predictions. Through behavioral analysis, we show that these errors result from a structured yet flawed mechanism that we term class-based (mis)generalization, in which models combine abstract class cues with features extracted from the query or context to derive answers. Furthermore, mechanistic interpretability experiments on Llama-3, Mistral, and Pythia across 39 factual recall relation types reveal that this behavior is reflected in the model's internal computations: (i) abstract class representations are constructed in lower layers before being refined into specific answers in higher layers, (ii) feature selection is governed by two competing circuits -- one prioritizing direct query-based reasoning, the other incorporating contextual cues -- whose relative influences determine the final output. Our findings provide a more nuanced perspective on the stochastic parrot argument: through form-based training, LLMs can exhibit generalization leveraging abstractions, albeit in unreliable ways based on contextual cues -- what we term stochastic chameleons.
PreSumm: Predicting Summarization Performance Without Summarizing
Apr 07, 2025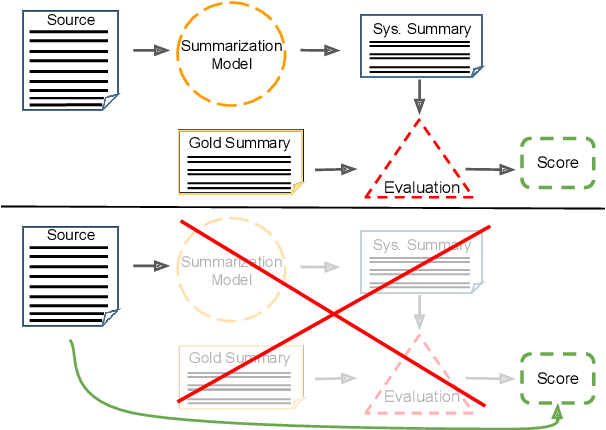
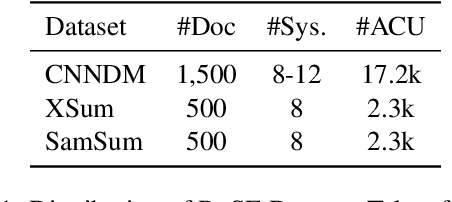
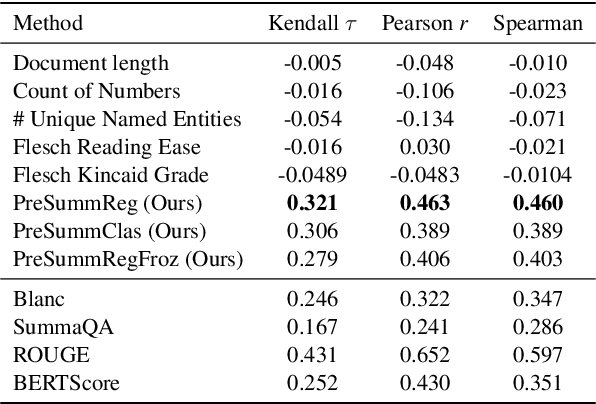
Despite recent advancements in automatic summarization, state-of-the-art models do not summarize all documents equally well, raising the question: why? While prior research has extensively analyzed summarization models, little attention has been given to the role of document characteristics in influencing summarization performance. In this work, we explore two key research questions. First, do documents exhibit consistent summarization quality across multiple systems? If so, can we predict a document's summarization performance without generating a summary? We answer both questions affirmatively and introduce PreSumm, a novel task in which a system predicts summarization performance based solely on the source document. Our analysis sheds light on common properties of documents with low PreSumm scores, revealing that they often suffer from coherence issues, complex content, or a lack of a clear main theme. In addition, we demonstrate PreSumm's practical utility in two key applications: improving hybrid summarization workflows by identifying documents that require manual summarization and enhancing dataset quality by filtering outliers and noisy documents. Overall, our findings highlight the critical role of document properties in summarization performance and offer insights into the limitations of current systems that could serve as the basis for future improvements.
Error Diversity Matters: An Error-Resistant Ensemble Method for Unsupervised Dependency Parsing
Dec 16, 2024We address unsupervised dependency parsing by building an ensemble of diverse existing models through post hoc aggregation of their output dependency parse structures. We observe that these ensembles often suffer from low robustness against weak ensemble components due to error accumulation. To tackle this problem, we propose an efficient ensemble-selection approach that avoids error accumulation. Results demonstrate that our approach outperforms each individual model as well as previous ensemble techniques. Additionally, our experiments show that the proposed ensemble-selection method significantly enhances the performance and robustness of our ensemble, surpassing previously proposed strategies, which have not accounted for error diversity.
Does This Summary Answer My Question? Modeling Query-Focused Summary Readers with Rational Speech Acts
Nov 10, 2024



Query-focused summarization (QFS) is the task of generating a summary in response to a user-written query. Despite its user-oriented nature, there has been limited work in QFS in explicitly considering a user's understanding of a generated summary, potentially causing QFS systems to underperform at inference time. In this paper, we adapt the Rational Speech Act (RSA) framework, a model of human communication, to explicitly model a reader's understanding of a query-focused summary and integrate it within the generation method of existing QFS systems. In particular, we introduce the answer reconstruction objective which approximates a reader's understanding of a summary by their ability to use it to reconstruct the answer to their initial query. Using this objective, we are able to re-rank candidate summaries generated by existing QFS systems and select summaries that better align with their corresponding query and reference summary. More generally, our study suggests that a simple and effective way of improving a language generation system designed for a user-centered task may be to explicitly incorporate its user requirements into the system's generation procedure.
Solving the Challenge Set without Solving the Task: On Winograd Schemas as a Test of Pronominal Coreference Resolution
Oct 12, 2024
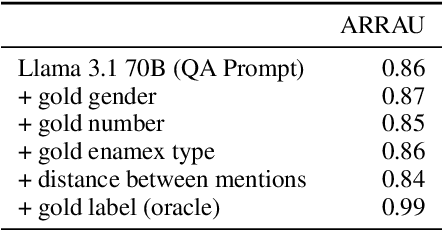


Challenge sets such as the Winograd Schema Challenge (WSC) are used to benchmark systems' ability to resolve ambiguities in natural language. If one assumes as in existing work that solving a given challenge set is at least as difficult as solving some more general task, then high performance on the challenge set should indicate high performance on the general task overall. However, we show empirically that this assumption of difficulty does not always hold. In particular, we demonstrate that despite the strong performance of prompted language models (LMs) on the WSC and its variants, these same modeling techniques perform relatively poorly at resolving certain pronominal ambiguities attested in OntoNotes and related datasets that are perceived to be easier. Motivated by these findings, we propose a method for ensembling a prompted LM with a supervised, task-specific system that is overall more accurate at resolving pronominal coreference across datasets. Finally, we emphasize that datasets involving the same linguistic phenomenon draw on distinct, but overlapping, capabilities, and evaluating on any one dataset alone does not provide a complete picture of a system's overall capability.