 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Chameleons: Irrelevant Context Hallucinations Reveal Class-Based (Mis)Generalization in LLMs
May 28, 2025The widespread success of large language models (LLMs) on NLP benchmarks has been accompanied by concerns that LLMs function primarily as stochastic parrots that reproduce texts similar to what they saw during pre-training, often erroneously. But what is the nature of their errors, and do these errors exhibit any regularities? In this work, we examine irrelevant context hallucinations, in which models integrate misleading contextual cues into their predictions. Through behavioral analysis, we show that these errors result from a structured yet flawed mechanism that we term class-based (mis)generalization, in which models combine abstract class cues with features extracted from the query or context to derive answers. Furthermore, mechanistic interpretability experiments on Llama-3, Mistral, and Pythia across 39 factual recall relation types reveal that this behavior is reflected in the model's internal computations: (i) abstract class representations are constructed in lower layers before being refined into specific answers in higher layers, (ii) feature selection is governed by two competing circuits -- one prioritizing direct query-based reasoning, the other incorporating contextual cues -- whose relative influences determine the final output. Our findings provide a more nuanced perspective on the stochastic parrot argument: through form-based training, LLMs can exhibit generalization leveraging abstractions, albeit in unreliable ways based on contextual cues -- what we term stochastic chameleons.
Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?
Feb 21, 2025The leading AI companies are increasingly focused on building generalist AI agents -- systems that can autonomously plan, act, and pursue goals across almost all tasks that humans can perform. Despite how useful these systems might be, unchecked AI agency poses significant risks to public safety and security, ranging from misuse by malicious actors to a potentially irreversible loss of human control. We discuss how these risks arise from current AI training methods. Indeed, various scenarios and experiments have demonstrated the possibility of AI agents engaging in deception or pursuing goals that were not specified by human operators and that conflict with human interests, such as self-preservation. Following the precautionary principle, we see a strong need for safer, yet still useful, alternatives to the current agency-driven trajectory. Accordingly, we propose as a core building block for further advances the development of a non-agentic AI system that is trustworthy and safe by design, which we call Scientist AI. This system is designed to explain the world from observations, as opposed to taking actions in it to imitate or please humans. It comprises a world model that generates theories to explain data and a question-answering inference machine. Both components operate with an explicit notion of uncertainty to mitigate the risks of overconfident predictions. In light of these considerations, a Scientist AI could be used to assist human researchers in accelerating scientific progress, including in AI safety. In particular, our system can be employed as a guardrail against AI agents that might be created despite the risks involved. Ultimately, focusing on non-agentic AI may enable the benefits of AI innovation while avoiding the risks associated with the current trajectory. We hope these arguments will motivate researchers, developers, and policymakers to favor this safer path.
CItruS: Chunked Instruction-aware State Eviction for Long Sequence Modeling
Jun 17, 2024



Long sequence modeling has gained broad interest as large language models (LLMs) continue to advance. Recent research has identified that a large portion of hidden states within the key-value caches of Transformer models can be discarded (also termed evicted) without affecting the perplexity performance in generating long sequences. However, we show that these methods, despite preserving perplexity performance, often drop information that is important for solving downstream tasks, a problem which we call information neglect. To address this issue, we introduce Chunked Instruction-aware State Eviction (CItruS), a novel modeling technique that integrates the attention preferences useful for a downstream task into the eviction process of hidden states. In addition, we design a method for chunked sequence processing to further improve efficiency. Our training-free method exhibits superior performance on long sequence comprehension and retrieval tasks over several strong baselines under the same memory budget, while preserving language modeling perplexity.
Analyzing Task-Encoding Tokens in Large Language Models
Jan 20, 2024In-context learning (ICL) has become an effective solution for few-shot learning in natural language processing. Past work has found that, during this process, representations of the last prompt token are utilized to store task reasoning procedures, thereby explaining the working mechanism of in-context learning. In this paper, we seek to locate and analyze other task-encoding tokens whose representations store task reasoning procedures. Supported by experiments that ablate the representations of different token types, we find that template and stopword tokens are the most prone to be task-encoding tokens. In addition, we demonstrate experimentally that lexical cues, repetition, and text formats are the main distinguishing characteristics of these tokens. Our work provides additional insights into how large language models (LLMs) leverage task reasoning procedures in ICL and suggests that future work may involve using task-encoding tokens to improve the computational efficiency of LLMs at inference time and their ability to handle long sequences.
Learning Dynamic Knowledge Graphs to Generalize on Text-Based Games
Feb 21, 2020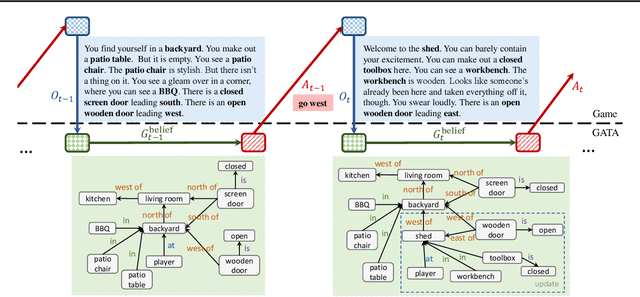

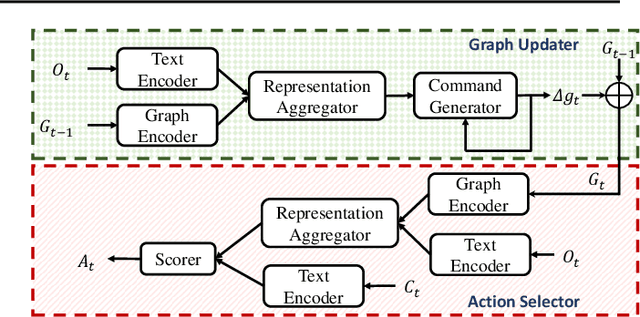
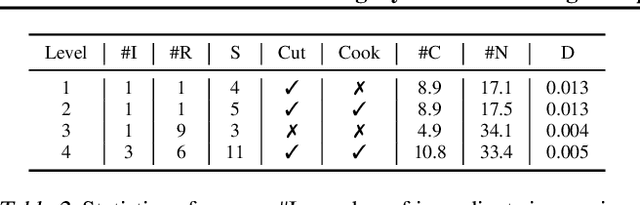
Playing text-based games requires skill in processing natural language and in planning. Although a key goal for agents solving this task is to generalize across multiple games, most previous work has either focused on solving a single game or has tackled generalization with rule-based heuristics. In this work, we investigate how structured information in the form of a knowledge graph (KG) can facilitate effective planning and generalization. We introduce a novel transformer-based sequence-to-sequence model that constructs a "belief" KG from raw text observations of the environment, dynamically updating this belief graph at every game step as it receives new observations. To train this model to build useful graph representations, we introduce and analyze a set of graph-related pre-training tasks. We demonstrate empirically that KG-based representations from our model help agents to converge faster to better policies for multiple text-based games, and further, enable stronger zero-shot performance on unseen games. Experiments on unseen games show that our best agent outperforms text-based baselines by 21.6%.