 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamic Knowledge Graphs to Generalize on Text-Based Games
Feb 21, 2020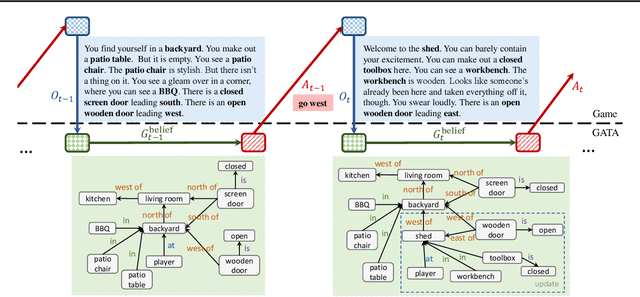

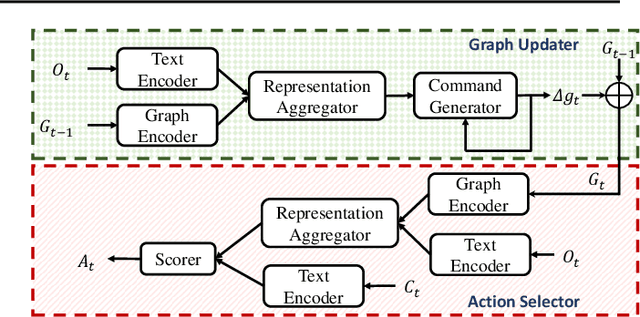
Playing text-based games requires skill in processing natural language and in planning. Although a key goal for agents solving this task is to generalize across multiple games, most previous work has either focused on solving a single game or has tackled generalization with rule-based heuristics. In this work, we investigate how structured information in the form of a knowledge graph (KG) can facilitate effective planning and generalization. We introduce a novel transformer-based sequence-to-sequence model that constructs a "belief" KG from raw text observations of the environment, dynamically updating this belief graph at every game step as it receives new observations. To train this model to build useful graph representations, we introduce and analyze a set of graph-related pre-training tasks. We demonstrate empirically that KG-based representations from our model help agents to converge faster to better policies for multiple text-based games, and further, enable stronger zero-shot performance on unseen games. Experiments on unseen games show that our best agent outperforms text-based baselines by 21.6%.
Baselines for Reinforcement Learning in Text Games
Nov 12, 2018


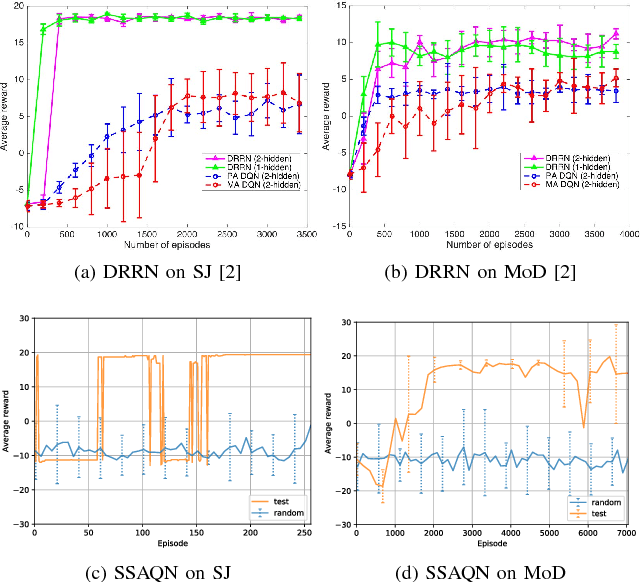
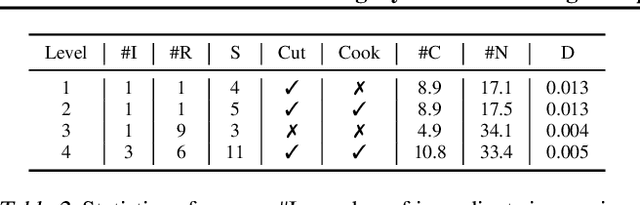
The ability to learn optimal control policies in systems where action space is defined by sentences in natural language would allow many interesting real-world applications such as automatic optimisation of dialogue systems. Text-based games with multiple endings and rewards are a promising platform for this task, since their feedback allows us to employ reinforcement learning techniques to jointly learn text representations and control policies. We argue that the key property of AI agents, especially in the text-games context, is their ability to generalise to previously unseen games. We present a minimalistic text-game playing agent, testing its generalisation and transfer learning performance and showing its ability to play multiple games at once. We also present pyfiction, an open-source library for universal access to different text games that could, together with our agent that implements its interface, serve as a baseline for future research.
Using reinforcement learning to learn how to play text-based games
Jan 06, 2018


The ability to learn optimal control policies in systems where action space is defined by sentences in natural language would allow many interesting real-world applications such as automatic optimisation of dialogue systems. Text-based games with multiple endings and rewards are a promising platform for this task, since their feedback allows us to employ reinforcement learning techniques to jointly learn text representations and control policies. We present a general text game playing agent, testing its generalisation and transfer learning performance and showing its ability to play multiple games at once. We also present pyfiction, an open-source library for universal access to different text games that could, together with our agent that implements its interface, serve as a baseline for future research.