 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Active Learning for the Search of Small-molecule Protein Binders
May 02, 2024



Despite substantial progress in machine learning for scientific discovery in recent years, truly de novo design of small molecules which exhibit a property of interest remains a significant challenge. We introduce LambdaZero, a generative active learning approach to search for synthesizable molecules. Powered by deep reinforcement learning, LambdaZero learns to search over the vast space of molecules to discover candidates with a desired property. We apply LambdaZero with molecular docking to design novel small molecules that inhibit the enzyme soluble Epoxide Hydrolase 2 (sEH), while enforcing constraints on synthesizability and drug-likeliness. LambdaZero provides an exponential speedup in terms of the number of calls to the expensive molecular docking oracle, and LambdaZero de novo designed molecules reach docking scores that would otherwise require the virtual screening of a hundred billion molecules. Importantly, LambdaZero discovers novel scaffolds of synthesizable, drug-like inhibitors for sEH. In in vitro experimental validation, a series of ligands from a generated quinazoline-based scaffold were synthesized, and the lead inhibitor N-(4,6-di(pyrrolidin-1-yl)quinazolin-2-yl)-N-methylbenzamide (UM0152893) displayed sub-micromolar enzyme inhibition of sEH.
Edge-similarity-aware Graph Neural Networks
Sep 20, 2021
Graph are a ubiquitous data representation, as they represent a flexible and compact representation. For instance, the 3D structure of RNA can be efficiently represented as $\textit{2.5D graphs}$, graphs whose nodes are nucleotides and edges represent chemical interactions. In this setting, we have biological evidence of the similarity between the edge types, as some chemical interactions are more similar than others. Machine learning on graphs have recently experienced a breakthrough with the introduction of Graph Neural Networks. This algorithm can be framed as a message passing algorithm between graph nodes over graph edges. These messages can depend on the edge type they are transmitted through, but no method currently constrains how a message is altered when the edge type changes. Motivated by the RNA use case, in this project we introduce a graph neural network layer which can leverage prior information about similarities between edges. We show that despite the theoretical appeal of including this similarity prior, the empirical performance is not enhanced on the tasks and datasets we include here.
Ego-GNNs: Exploiting Ego Structures in Graph Neural Networks
Jul 22, 2021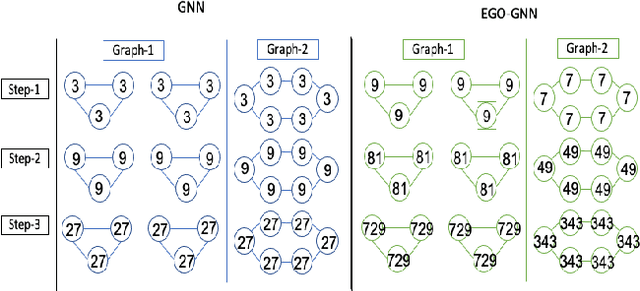

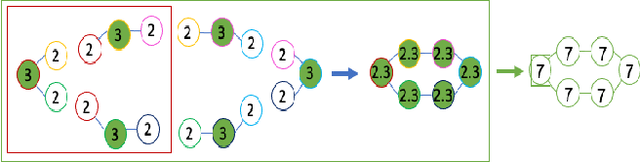
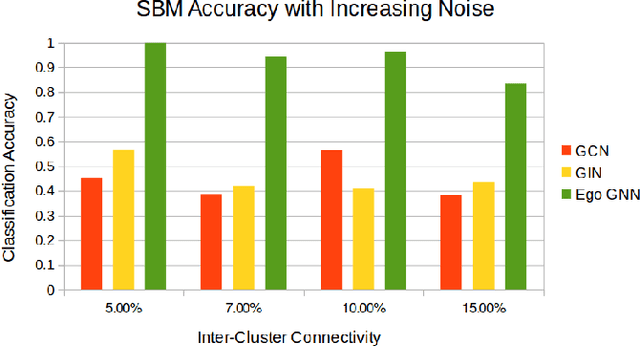
Graph neural networks (GNNs) have achieved remarkable success as a framework for deep learning on graph-structured data. However, GNNs are fundamentally limited by their tree-structured inductive bias: the WL-subtree kernel formulation bounds the representational capacity of GNNs, and polynomial-time GNNs are provably incapable of recognizing triangles in a graph. In this work, we propose to augment the GNN message-passing operations with information defined on ego graphs (i.e., the induced subgraph surrounding each node). We term these approaches Ego-GNNs and show that Ego-GNNs are provably more powerful than standard message-passing GNNs. In particular, we show that Ego-GNNs are capable of recognizing closed triangles, which is essential given the prominence of transitivity in real-world graphs. We also motivate our approach from the perspective of graph signal processing as a form of multiplex graph convolution. Experimental results on node classification using synthetic and real data highlight the achievable performance gains using this approach.
* Submitted to a special session of IEEE-ICASSP 2021
NodePiece: Compositional and Parameter-Efficient Representations of Large Knowledge Graphs
Jun 23, 2021
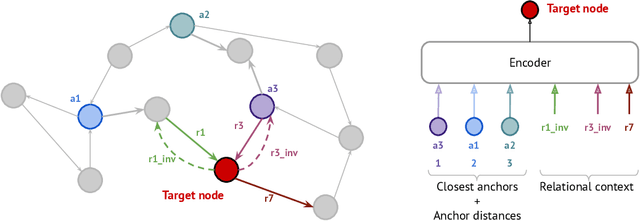
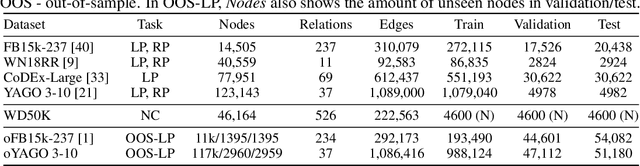
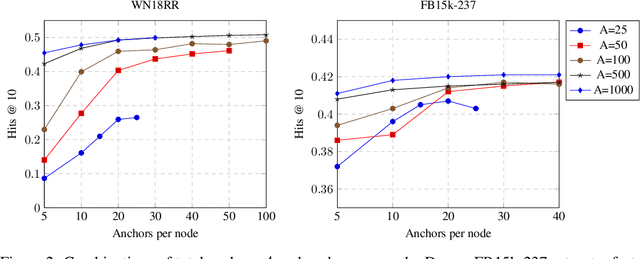
Conventional representation learning algorithms for knowledge graphs (KG) map each entity to a unique embedding vector. Such a shallow lookup results in a linear growth of memory consumption for storing the embedding matrix and incurs high computational costs when working with real-world KGs. Drawing parallels with subword tokenization commonly used in NLP, we explore the landscape of more parameter-efficient node embedding strategies with possibly sublinear memory requirements. To this end, we propose NodePiece, an anchor-based approach to learn a fixed-size entity vocabulary. In NodePiece, a vocabulary of subword/sub-entity units is constructed from anchor nodes in a graph with known relation types. Given such a fixed-size vocabulary, it is possible to bootstrap an encoding and embedding for any entity, including those unseen during training. Experiments show that NodePiece performs competitively in node classification, link prediction, and relation prediction tasks while retaining less than 10% of explicit nodes in a graph as anchors and often having 10x fewer parameters.
Rethinking Graph Transformers with Spectral Attention
Jun 09, 2021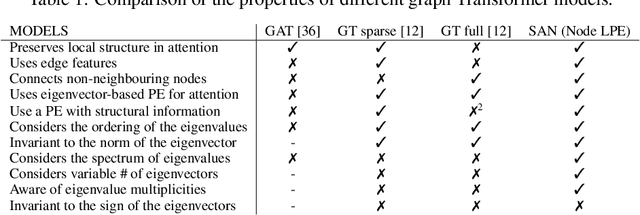
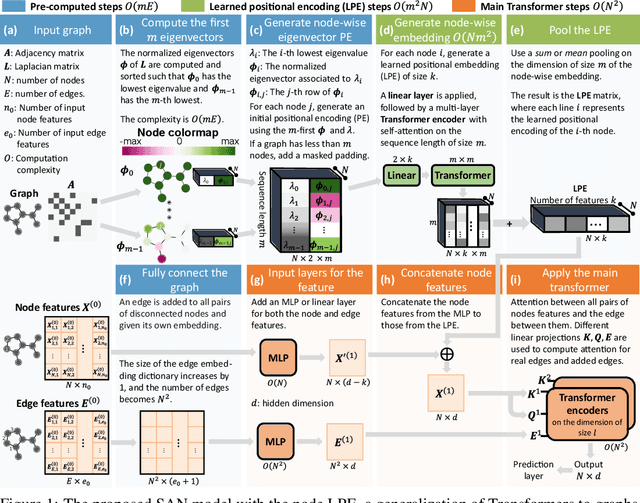

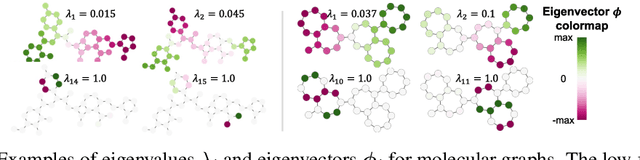
In recent years, the Transformer architecture has proven to be very successful in sequence processing, but its application to other data structures, such as graphs, has remained limited due to the difficulty of properly defining positions. Here, we present the $\textit{Spectral Attention Network}$ (SAN), which uses a learned positional encoding (LPE) that can take advantage of the full Laplacian spectrum to learn the position of each node in a given graph. This LPE is then added to the node features of the graph and passed to a fully-connected Transformer. By leveraging the full spectrum of the Laplacian, our model is theoretically powerful in distinguishing graphs, and can better detect similar sub-structures from their resonance. Further, by fully connecting the graph, the Transformer does not suffer from over-squashing, an information bottleneck of most GNNs, and enables better modeling of physical phenomenons such as heat transfer and electric interaction. When tested empirically on a set of 4 standard datasets, our model performs on par or better than state-of-the-art GNNs, and outperforms any attention-based model by a wide margin, becoming the first fully-connected architecture to perform well on graph benchmarks.
Online Adversarial Attacks
Mar 02, 2021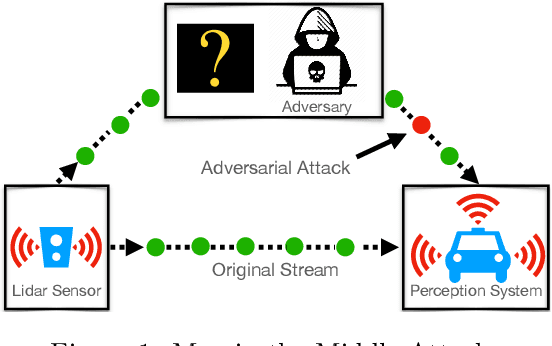
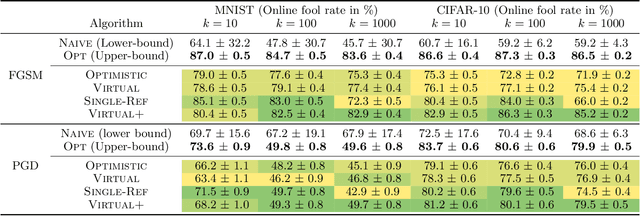
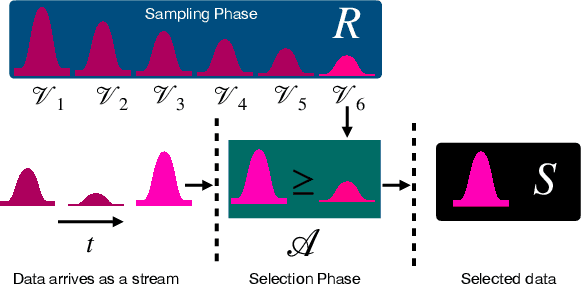
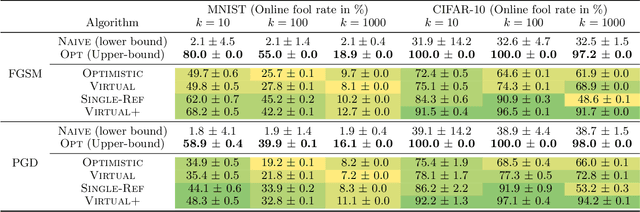
Adversarial attacks expose important vulnerabilities of deep learning models, yet little attention has been paid to settings where data arrives as a stream. In this paper, we formalize the online adversarial attack problem, emphasizing two key elements found in real-world use-cases: attackers must operate under partial knowledge of the target model, and the decisions made by the attacker are irrevocable since they operate on a transient data stream. We first rigorously analyze a deterministic variant of the online threat model by drawing parallels to the well-studied $k$-\textit{secretary problem} and propose \algoname, a simple yet practical algorithm yielding a provably better competitive ratio for $k=2$ over the current best single threshold algorithm. We also introduce the \textit{stochastic $k$-secretary} -- effectively reducing online blackbox attacks to a $k$-secretary problem under noise -- and prove theoretical bounds on the competitive ratios of \textit{any} online algorithms adapted to this setting. Finally, we complement our theoretical results by conducting a systematic suite of experiments on MNIST and CIFAR-10 with both vanilla and robust classifiers, revealing that, by leveraging online secretary algorithms, like \algoname, we can get an online attack success rate close to the one achieved by the optimal offline solution.
Exploring the Limits of Few-Shot Link Prediction in Knowledge Graphs
Feb 05, 2021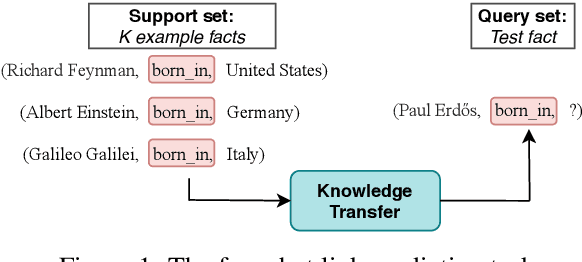
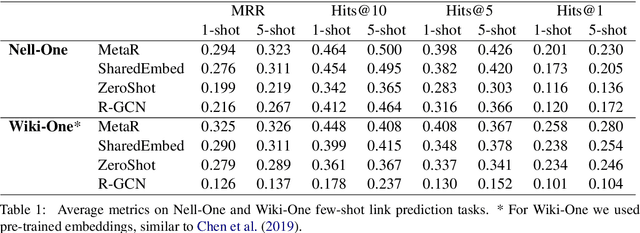

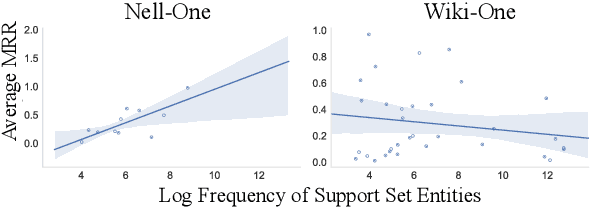
Real-world knowledge graphs are often characterized by low-frequency relations - a challenge that has prompted an increasing interest in few-shot link prediction methods. These methods perform link prediction for a set of new relations, unseen during training, given only a few example facts of each relation at test time. In this work, we perform a systematic study on a spectrum of models derived by generalizing the current state of the art for few-shot link prediction, with the goal of probing the limits of learning in this few-shot setting. We find that a simple zero-shot baseline - which ignores any relation-specific information - achieves surprisingly strong performance. Moreover, experiments on carefully crafted synthetic datasets show that having only a few examples of a relation fundamentally limits models from using fine-grained structural information and only allows for exploiting the coarse-grained positional information of entities. Together, our findings challenge the implicit assumptions and inductive biases of prior work and highlight new directions for research in this area.
* code available at https://github.com/dorajam/few-shot-link-prediction-paper
Neural representation and generation for RNA secondary structures
Feb 01, 2021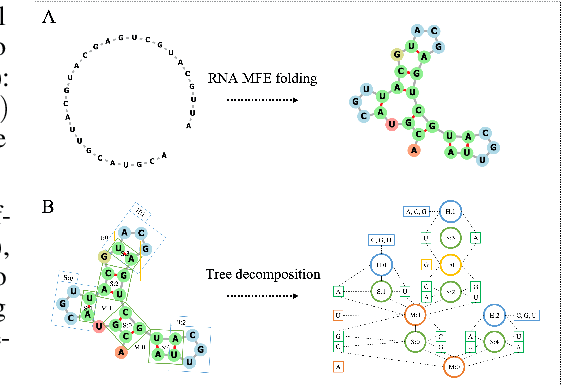
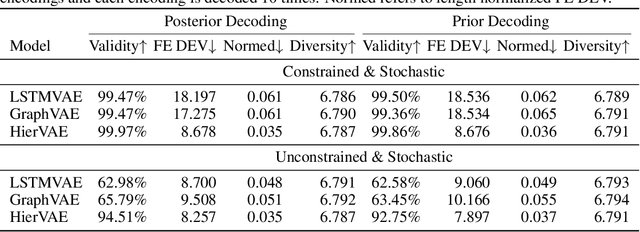
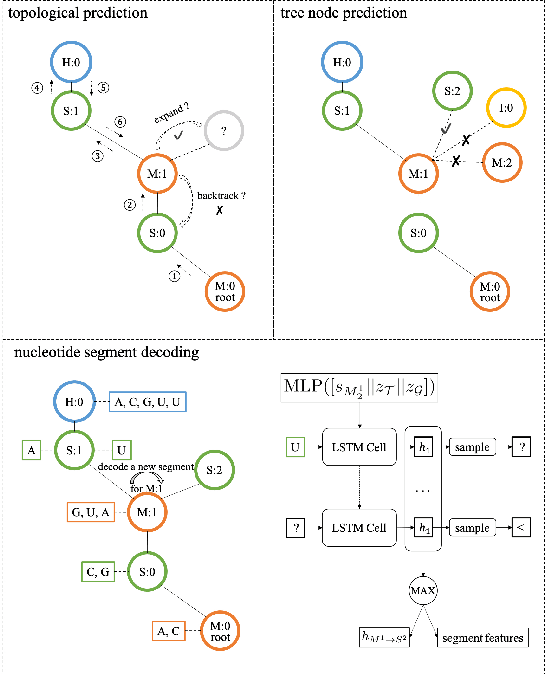
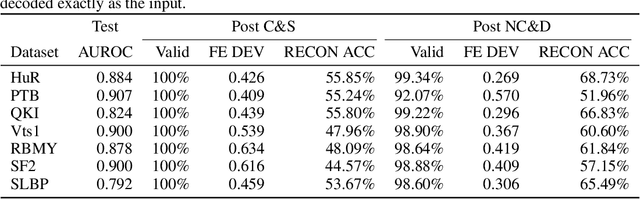
Our work is concerned with the generation and targeted design of RNA, a type of genetic macromolecule that can adopt complex structures which influence their cellular activities and functions. The design of large scale and complex biological structures spurs dedicated graph-based deep generative modeling techniques, which represents a key but underappreciated aspect of computational drug discovery. In this work, we investigate the principles behind representing and generating different RNA structural modalities, and propose a flexible framework to jointly embed and generate these molecular structures along with their sequence in a meaningful latent space. Equipped with a deep understanding of RNA molecular structures, our most sophisticated encoding and decoding methods operate on the molecular graph as well as the junction tree hierarchy, integrating strong inductive bias about RNA structural regularity and folding mechanism such that high structural validity, stability and diversity of generated RNAs are achieved. Also, we seek to adequately organize the latent space of RNA molecular embeddings with regard to the interaction with proteins, and targeted optimization is used to navigate in this latent space to search for desired novel RNA molecules.
Estimating the Impact of an Improvement to a Revenue Management System: An Airline Application
Jan 13, 2021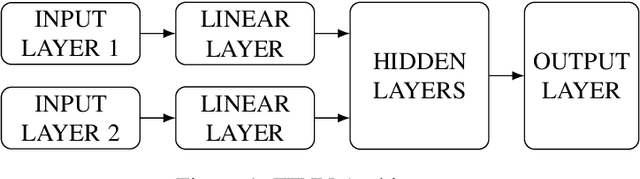

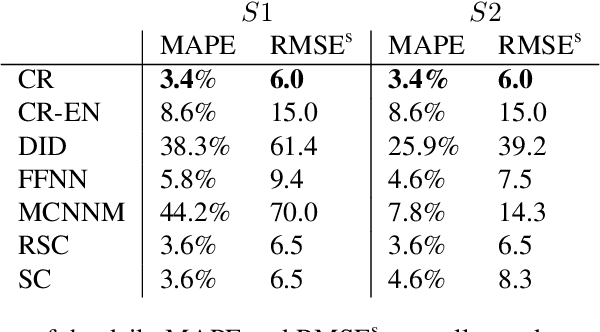
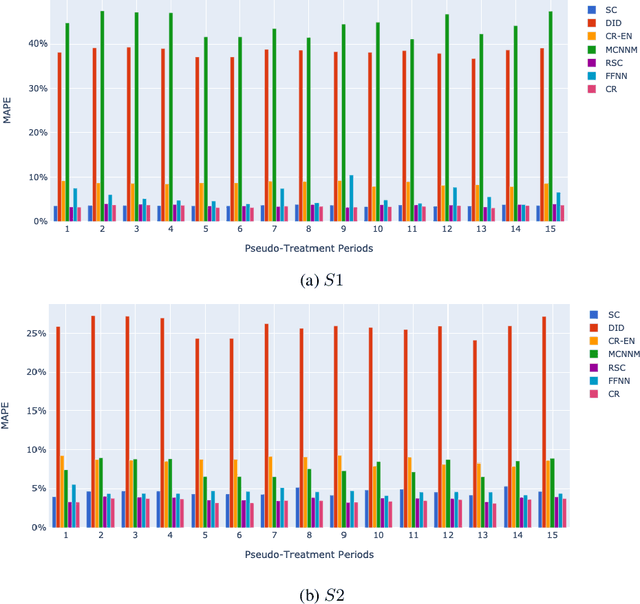
Airlines have been making use of highly complex Revenue Management Systems to maximize revenue for decades. Estimating the impact of changing one component of those systems on an important outcome such as revenue is crucial, yet very challenging. It is indeed the difference between the generated value and the value that would have been generated keeping business as usual, which is not observable. We provide a comprehensive overview of counterfactual prediction models and use them in an extensive computational study based on data from Air Canada to estimate such impact. We focus on predicting the counterfactual revenue and compare it to the observed revenue subject to the impact. Our microeconomic application and small expected treatment impact stand out from the usual synthetic control applications. We present accurate linear and deep-learning counterfactual prediction models which achieve respectively 1.1% and 1% of error and allow to estimate a simulated effect quite accurately.
TeMP: Temporal Message Passing for Temporal Knowledge Graph Completion
Oct 07, 2020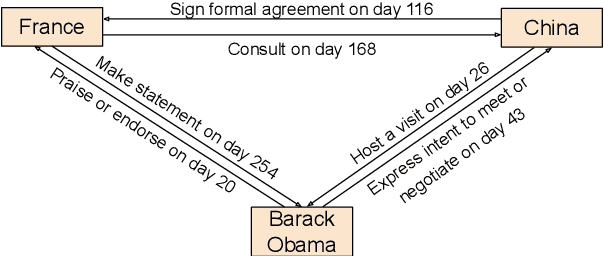
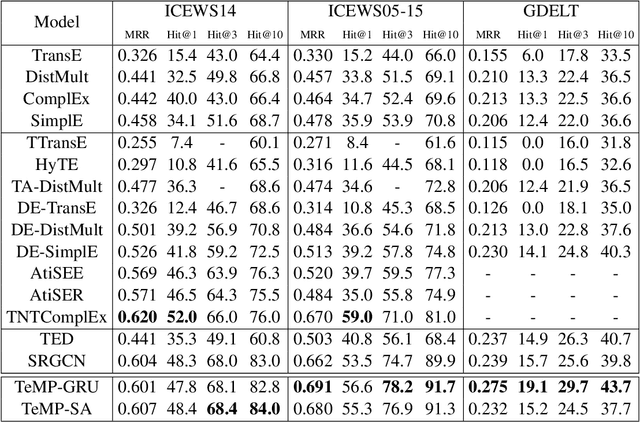
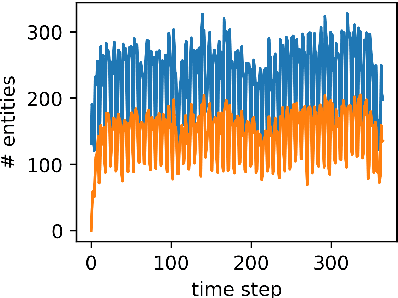
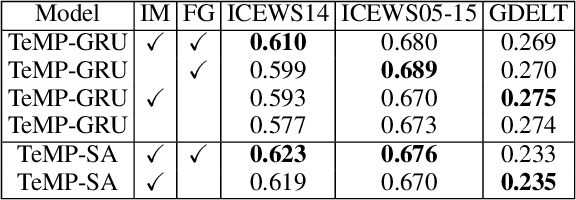
Inferring missing facts in temporal knowledge graphs (TKGs) is a fundamental and challenging task. Previous works have approached this problem by augmenting methods for static knowledge graphs to leverage time-dependent representations. However, these methods do not explicitly leverage multi-hop structural information and temporal facts from recent time steps to enhance their predictions. Additionally, prior work does not explicitly address the temporal sparsity and variability of entity distributions in TKGs. We propose the Temporal Message Passing (TeMP) framework to address these challenges by combining graph neural networks, temporal dynamics models, data imputation and frequency-based gating techniques. Experiments on standard TKG tasks show that our approach provides substantial gains compared to the previous state of the art, achieving a 10.7% average relative improvement in Hits@10 across three standard benchmarks. Our analysis also reveals important sources of variability both within and across TKG datasets, and we introduce several simple but strong baselines that outperform the prior state of the art in certain settings.