 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSc-SQL: Multi-Sample Critiquing Small Language Models For Text-To-SQL Translation
Oct 16, 2024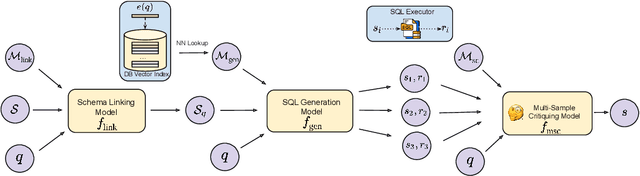
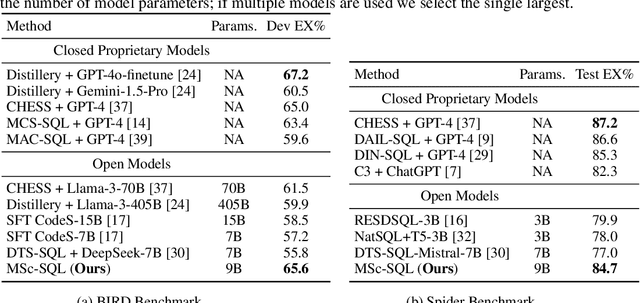


Text-to-SQL generation enables non-experts to interact with databases via natural language. Recent advances rely on large closed-source models like GPT-4 that present challenges in accessibility, privacy, and latency. To address these issues, we focus on developing small, efficient, and open-source text-to-SQL models. We demonstrate the benefits of sampling multiple candidate SQL generations and propose our method, MSc-SQL, to critique them using associated metadata. Our sample critiquing model evaluates multiple outputs simultaneously, achieving state-of-the-art performance compared to other open-source models while remaining competitive with larger models at a much lower cost. Full code can be found at github.com/layer6ai-labs/msc-sql.
Benchmarking Robust Self-Supervised Learning Across Diverse Downstream Tasks
Jul 18, 2024



Large-scale vision models have become integral in many applications due to their unprecedented performance and versatility across downstream tasks. However, the robustness of these foundation models has primarily been explored for a single task, namely image classification. The vulnerability of other common vision tasks, such as semantic segmentation and depth estimation, remains largely unknown. We present a comprehensive empirical evaluation of the adversarial robustness of self-supervised vision encoders across multiple downstream tasks. Our attacks operate in the encoder embedding space and at the downstream task output level. In both cases, current state-of-the-art adversarial fine-tuning techniques tested only for classification significantly degrade clean and robust performance on other tasks. Since the purpose of a foundation model is to cater to multiple applications at once, our findings reveal the need to enhance encoder robustness more broadly. Our code is available at ${github.com/layer6ai-labs/ssl-robustness}$.
DepthMOT: Depth Cues Lead to a Strong Multi-Object Tracker
Apr 08, 2024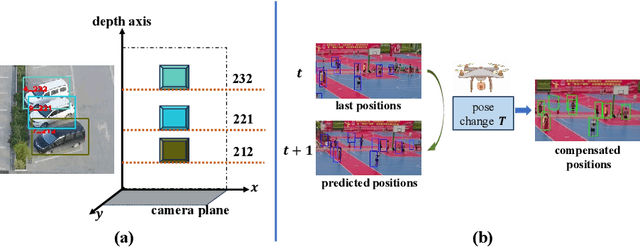
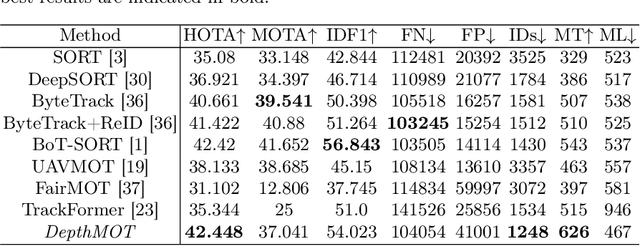
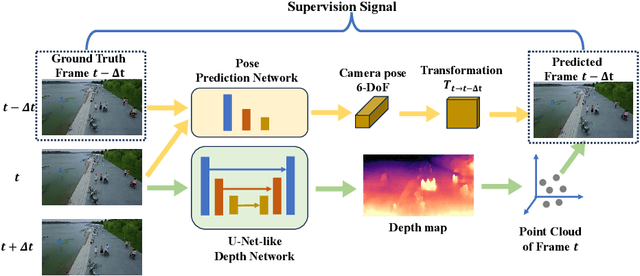
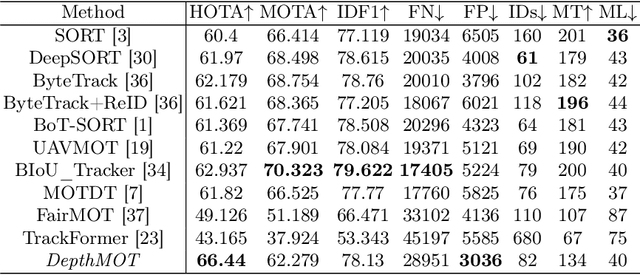
Accurately distinguishing each object is a fundamental goal of Multi-object tracking (MOT) algorithms. However, achieving this goal still remains challenging, primarily due to: (i) For crowded scenes with occluded objects, the high overlap of object bounding boxes leads to confusion among closely located objects. Nevertheless, humans naturally perceive the depth of elements in a scene when observing 2D videos. Inspired by this, even though the bounding boxes of objects are close on the camera plane, we can differentiate them in the depth dimension, thereby establishing a 3D perception of the objects. (ii) For videos with rapidly irregular camera motion, abrupt changes in object positions can result in ID switches. However, if the camera pose are known, we can compensate for the errors in linear motion models. In this paper, we propose \textit{DepthMOT}, which achieves: (i) detecting and estimating scene depth map \textit{end-to-end}, (ii) compensating the irregular camera motion by camera pose estimation. Extensive experiments demonstrate the superior performance of DepthMOT in VisDrone-MOT and UAVDT datasets. The code will be available at \url{https://github.com/JackWoo0831/DepthMOT}.
Augment then Smooth: Reconciling Differential Privacy with Certified Robustness
Jun 14, 2023
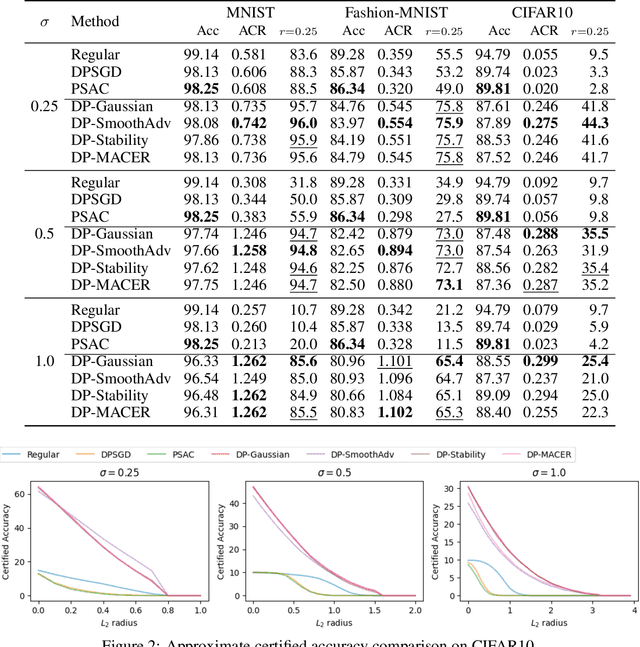
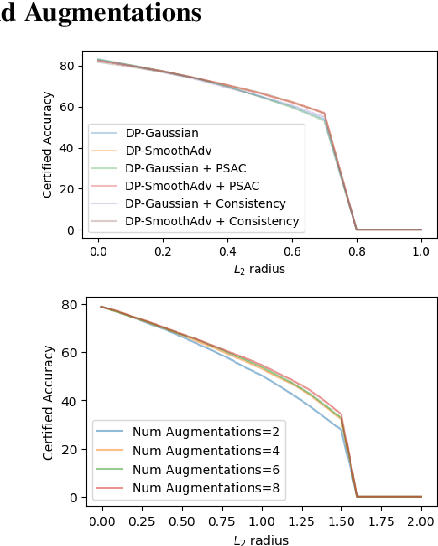
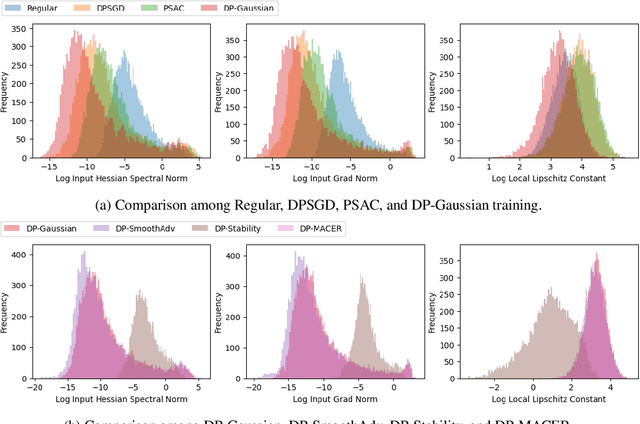
Machine learning models are susceptible to a variety of attacks that can erode trust in their deployment. These threats include attacks against the privacy of training data and adversarial examples that jeopardize model accuracy. Differential privacy and randomized smoothing are effective defenses that provide certifiable guarantees for each of these threats, however, it is not well understood how implementing either defense impacts the other. In this work, we argue that it is possible to achieve both privacy guarantees and certified robustness simultaneously. We provide a framework called DP-CERT for integrating certified robustness through randomized smoothing into differentially private model training. For instance, compared to differentially private stochastic gradient descent on CIFAR10, DP-CERT leads to a 12-fold increase in certified accuracy and a 10-fold increase in the average certified radius at the expense of a drop in accuracy of 1.2%. Through in-depth per-sample metric analysis, we show that the certified radius correlates with the local Lipschitz constant and smoothness of the loss surface. This provides a new way to diagnose when private models will fail to be robust.
NodePiece: Compositional and Parameter-Efficient Representations of Large Knowledge Graphs
Jun 23, 2021
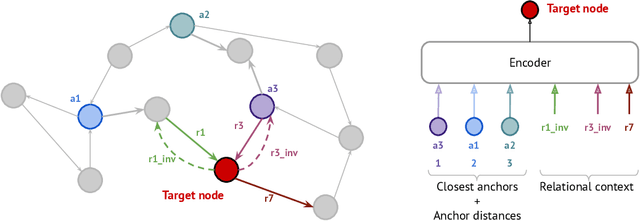
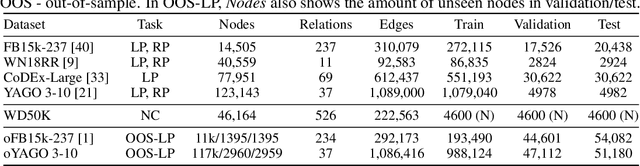
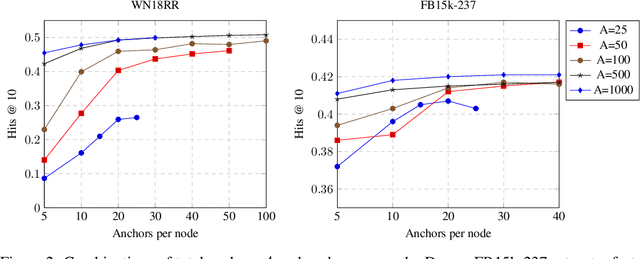
Conventional representation learning algorithms for knowledge graphs (KG) map each entity to a unique embedding vector. Such a shallow lookup results in a linear growth of memory consumption for storing the embedding matrix and incurs high computational costs when working with real-world KGs. Drawing parallels with subword tokenization commonly used in NLP, we explore the landscape of more parameter-efficient node embedding strategies with possibly sublinear memory requirements. To this end, we propose NodePiece, an anchor-based approach to learn a fixed-size entity vocabulary. In NodePiece, a vocabulary of subword/sub-entity units is constructed from anchor nodes in a graph with known relation types. Given such a fixed-size vocabulary, it is possible to bootstrap an encoding and embedding for any entity, including those unseen during training. Experiments show that NodePiece performs competitively in node classification, link prediction, and relation prediction tasks while retaining less than 10% of explicit nodes in a graph as anchors and often having 10x fewer parameters.
TIE: A Framework for Embedding-based Incremental Temporal Knowledge Graph Completion
May 09, 2021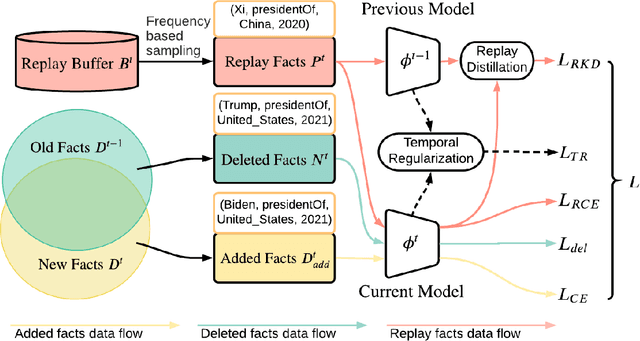

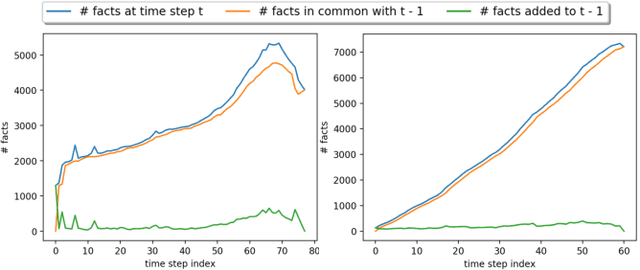
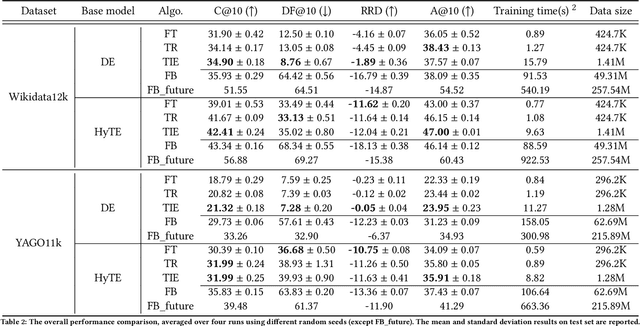
Reasoning in a temporal knowledge graph (TKG) is a critical task for information retrieval and semantic search. It is particularly challenging when the TKG is updated frequently. The model has to adapt to changes in the TKG for efficient training and inference while preserving its performance on historical knowledge. Recent work approaches TKG completion (TKGC) by augmenting the encoder-decoder framework with a time-aware encoding function. However, naively fine-tuning the model at every time step using these methods does not address the problems of 1) catastrophic forgetting, 2) the model's inability to identify the change of facts (e.g., the change of the political affiliation and end of a marriage), and 3) the lack of training efficiency. To address these challenges, we present the Time-aware Incremental Embedding (TIE) framework, which combines TKG representation learning, experience replay, and temporal regularization. We introduce a set of metrics that characterizes the intransigence of the model and propose a constraint that associates the deleted facts with negative labels. Experimental results on Wikidata12k and YAGO11k datasets demonstrate that the proposed TIE framework reduces training time by about ten times and improves on the proposed metrics compared to vanilla full-batch training. It comes without a significant loss in performance for any traditional measures. Extensive ablation studies reveal performance trade-offs among different evaluation metrics, which is essential for decision-making around real-world TKG applications.
Factual Error Correction for Abstractive Summarization Models
Oct 17, 2020

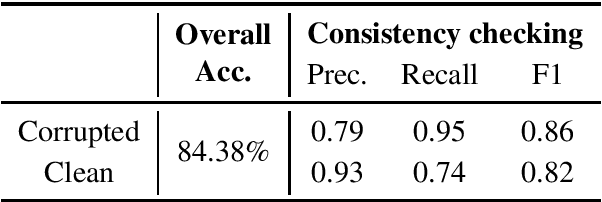
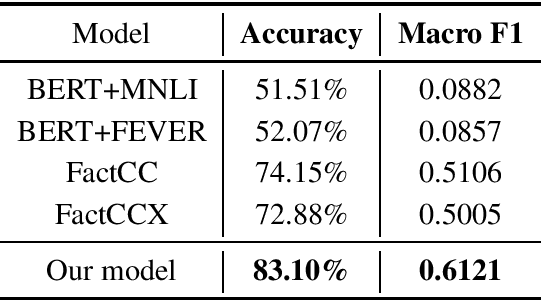
Neural abstractive summarization systems have achieved promising progress, thanks to the availability of large-scale datasets and models pre-trained with self-supervised methods. However, ensuring the factual consistency of the generated summaries for abstractive summarization systems is a challenge. We propose a post-editing corrector module to address this issue by identifying and correcting factual errors in generated summaries. The neural corrector model is pre-trained on artificial examples that are created by applying a series of heuristic transformations on reference summaries. These transformations are inspired by an error analysis of state-of-the-art summarization model outputs. Experimental results show that our model is able to correct factual errors in summaries generated by other neural summarization models and outperforms previous models on factual consistency evaluation on the CNN/DailyMail dataset. We also find that transferring from artificial error correction to downstream settings is still very challenging.
TeMP: Temporal Message Passing for Temporal Knowledge Graph Completion
Oct 07, 2020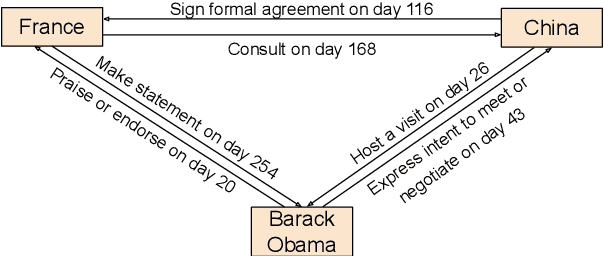
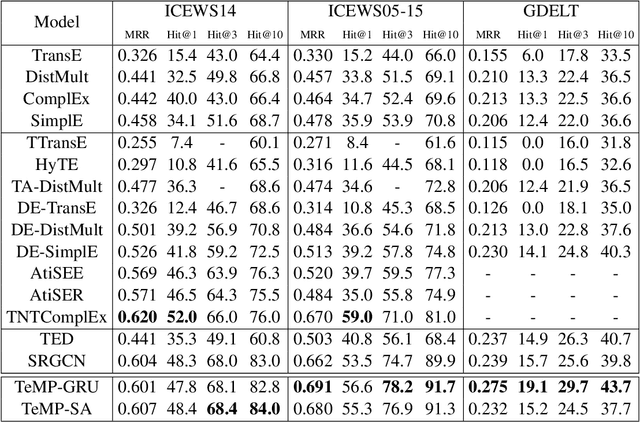
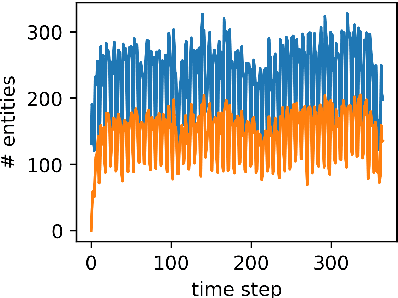
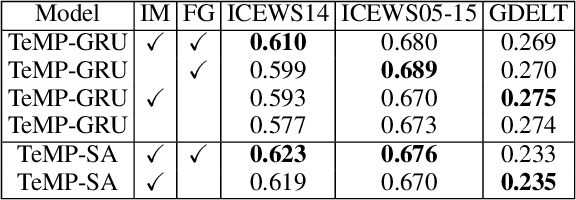
Inferring missing facts in temporal knowledge graphs (TKGs) is a fundamental and challenging task. Previous works have approached this problem by augmenting methods for static knowledge graphs to leverage time-dependent representations. However, these methods do not explicitly leverage multi-hop structural information and temporal facts from recent time steps to enhance their predictions. Additionally, prior work does not explicitly address the temporal sparsity and variability of entity distributions in TKGs. We propose the Temporal Message Passing (TeMP) framework to address these challenges by combining graph neural networks, temporal dynamics models, data imputation and frequency-based gating techniques. Experiments on standard TKG tasks show that our approach provides substantial gains compared to the previous state of the art, achieving a 10.7% average relative improvement in Hits@10 across three standard benchmarks. Our analysis also reveals important sources of variability both within and across TKG datasets, and we introduce several simple but strong baselines that outperform the prior state of the art in certain settings.