 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabDPT: Scaling Tabular Foundation Models
Oct 23, 2024



The challenges faced by neural networks on tabular data are well-documented and have hampered the progress of tabular foundation models. Techniques leveraging in-context learning (ICL) have shown promise here, allowing for dynamic adaptation to unseen data. ICL can provide predictions for entirely new datasets without further training or hyperparameter tuning, therefore providing very fast inference when encountering a novel task. However, scaling ICL for tabular data remains an issue: approaches based on large language models cannot efficiently process numeric tables, and tabular-specific techniques have not been able to effectively harness the power of real data to improve performance and generalization. We are able to overcome these challenges by training tabular-specific ICL-based architectures on real data with self-supervised learning and retrieval, combining the best of both worlds. Our resulting model -- the Tabular Discriminative Pre-trained Transformer (TabDPT) -- achieves state-of-the-art performance on the CC18 (classification) and CTR23 (regression) benchmarks with no task-specific fine-tuning, demonstrating the adapatability and speed of ICL once the model is pre-trained. TabDPT also demonstrates strong scaling as both model size and amount of available data increase, pointing towards future improvements simply through the curation of larger tabular pre-training datasets and training larger models.
MSc-SQL: Multi-Sample Critiquing Small Language Models For Text-To-SQL Translation
Oct 16, 2024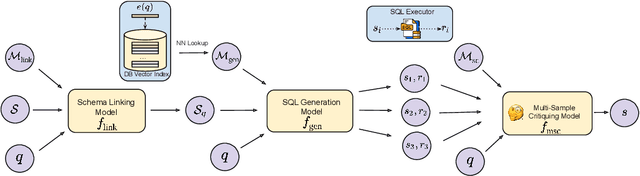
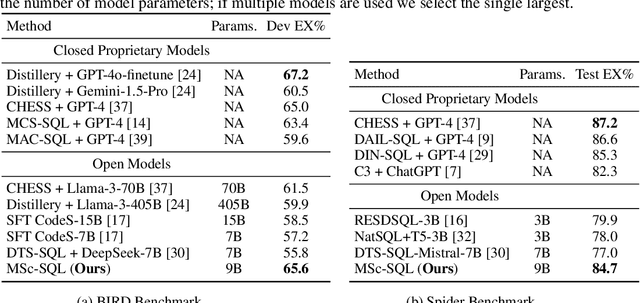


Text-to-SQL generation enables non-experts to interact with databases via natural language. Recent advances rely on large closed-source models like GPT-4 that present challenges in accessibility, privacy, and latency. To address these issues, we focus on developing small, efficient, and open-source text-to-SQL models. We demonstrate the benefits of sampling multiple candidate SQL generations and propose our method, MSc-SQL, to critique them using associated metadata. Our sample critiquing model evaluates multiple outputs simultaneously, achieving state-of-the-art performance compared to other open-source models while remaining competitive with larger models at a much lower cost. Full code can be found at github.com/layer6ai-labs/msc-sql.
Retrieval & Fine-Tuning for In-Context Tabular Models
Jun 07, 2024Tabular data is a pervasive modality spanning a wide range of domains, and the inherent diversity poses a considerable challenge for deep learning. Recent advancements using transformer-based in-context learning have shown promise on smaller and less complex datasets, but have struggled to scale to larger and more complex ones. To address this limitation, we propose a combination of retrieval and fine-tuning: we can adapt the transformer to a local subset of the data by collecting nearest neighbours, and then perform task-specific fine-tuning with this retrieved set of neighbours in context. Using TabPFN as the base model -- currently the best tabular in-context learner -- and applying our retrieval and fine-tuning scheme on top results in what we call a locally-calibrated PFN, or LoCalPFN. We conduct extensive evaluation on 95 datasets curated by TabZilla from OpenML, upon which we establish a new state-of-the-art with LoCalPFN -- even with respect to tuned tree-based models. Notably, we show a significant boost in performance compared to the base in-context model, demonstrating the efficacy of our approach and advancing the frontier of deep learning in tabular data.
TabPFGen -- Tabular Data Generation with TabPFN
Jun 07, 2024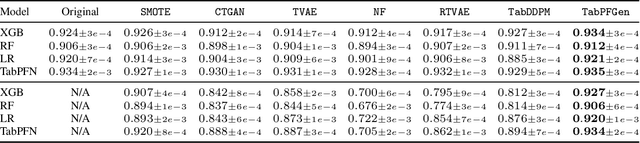
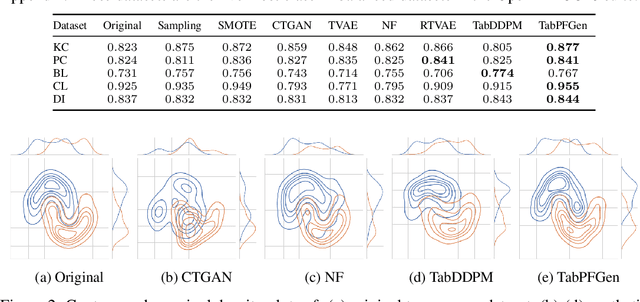
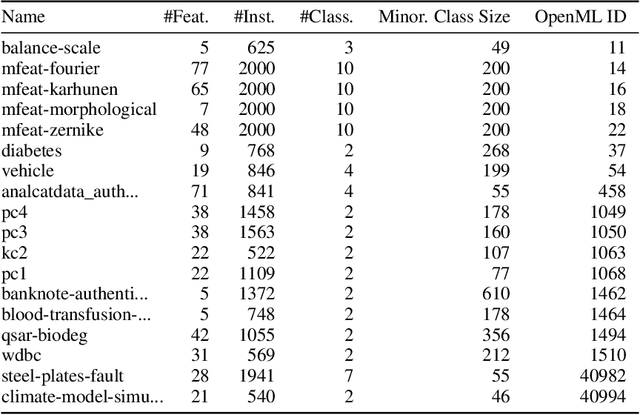
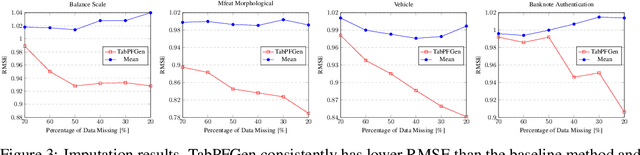
Advances in deep generative modelling have not translated well to tabular data. We argue that this is caused by a mismatch in structure between popular generative models and discriminative models of tabular data. We thus devise a technique to turn TabPFN -- a highly performant transformer initially designed for in-context discriminative tabular tasks -- into an energy-based generative model, which we dub TabPFGen. This novel framework leverages the pre-trained TabPFN as part of the energy function and does not require any additional training or hyperparameter tuning, thus inheriting TabPFN's in-context learning capability. We can sample from TabPFGen analogously to other energy-based models. We demonstrate strong results on standard generative modelling tasks, including data augmentation, class-balancing, and imputation, unlocking a new frontier of tabular data generation.
In-Context Data Distillation with TabPFN
Feb 10, 2024Foundation models have revolutionized tasks in computer vision and natural language processing. However, in the realm of tabular data, tree-based models like XGBoost continue to dominate. TabPFN, a transformer model tailored for tabular data, mirrors recent foundation models in its exceptional in-context learning capability, being competitive with XGBoost's performance without the need for task-specific training or hyperparameter tuning. Despite its promise, TabPFN's applicability is hindered by its data size constraint, limiting its use in real-world scenarios. To address this, we present in-context data distillation (ICD), a novel methodology that effectively eliminates these constraints by optimizing TabPFN's context. ICD efficiently enables TabPFN to handle significantly larger datasets with a fixed memory budget, improving TabPFN's quadratic memory complexity but at the cost of a linear number of tuning steps. Notably, TabPFN, enhanced with ICD, demonstrates very strong performance against established tree-based models and modern deep learning methods on 48 large tabular datasets from OpenML.
Data-Efficient Multimodal Fusion on a Single GPU
Jan 02, 2024



The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $\sim \! 600\times$ fewer GPU days and $\sim \! 80\times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
A Multi-size Kernel based Adaptive Convolutional Neural Network for Bearing Fault Diagnosis
Mar 29, 2022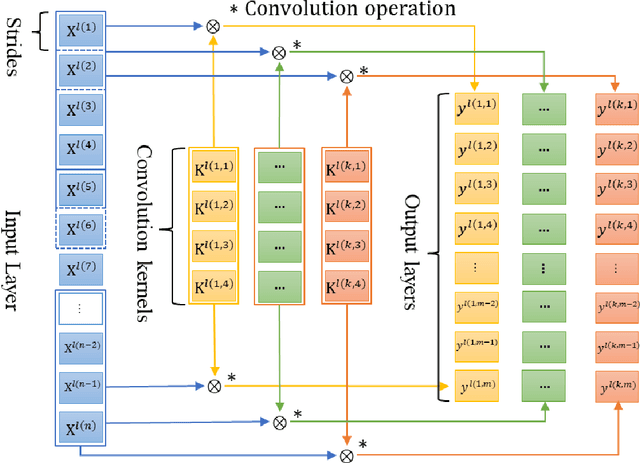
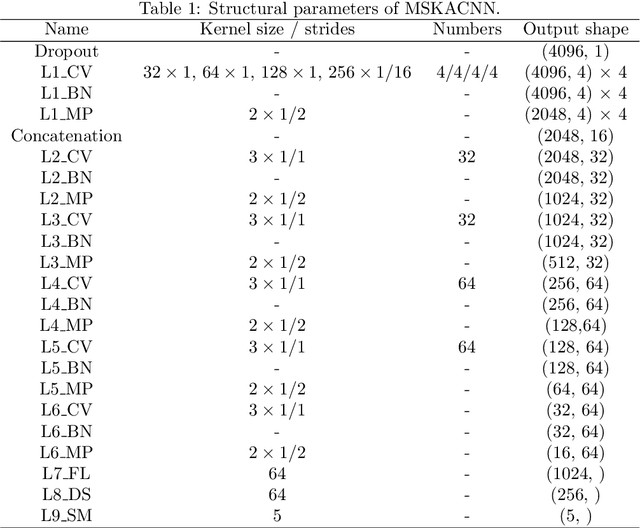
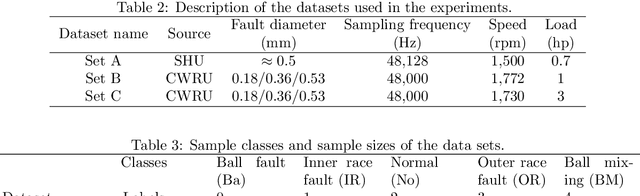
Bearing fault identification and analysis is an important research area in the field of machinery fault diagnosis. Aiming at the common faults of rolling bearings, we propose a data-driven diagnostic algorithm based on the characteristics of bearing vibrations called multi-size kernel based adaptive convolutional neural network (MSKACNN). Using raw bearing vibration signals as the inputs, MSKACNN provides vibration feature learning and signal classification capabilities to identify and analyze bearing faults. Ball mixing is a ball bearing production quality problem that is difficult to identify using traditional frequency domain analysis methods since it requires high frequency resolutions of the measurement signals and results in a long analyzing time. The proposed MSKACNN is shown to improve the efficiency and accuracy of ball mixing diagnosis. To further demonstrate the effectiveness of MSKACNN in bearing fault identification, a bearing vibration data acquisition system was developed, and vibration signal acquisition was performed on rolling bearings under five different fault conditions including ball mixing. The resulting datasets were used to analyze the performance of our proposed model. To validate the adaptive ability of MSKACNN, fault test data from the Case Western Reserve University Bearing Data Center were also used. Test results show that MSKACNN can identify the different bearing conditions with high accuracy with high generalization ability. We presented an implementation of the MSKACNN as a lightweight module for a real-time bearing fault diagnosis system that is suitable for production.
X-Pool: Cross-Modal Language-Video Attention for Text-Video Retrieval
Mar 28, 2022
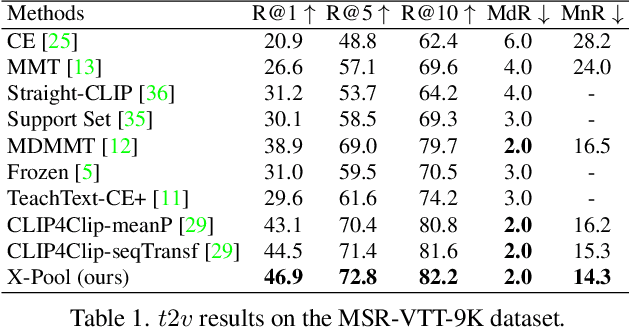
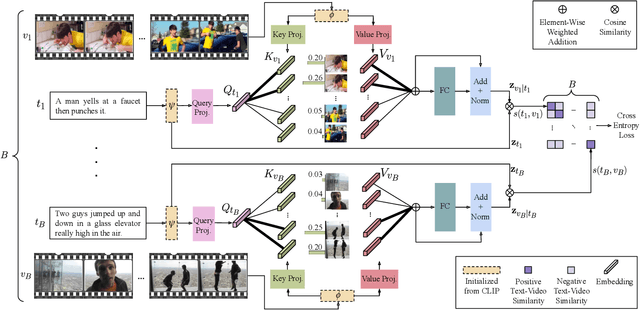
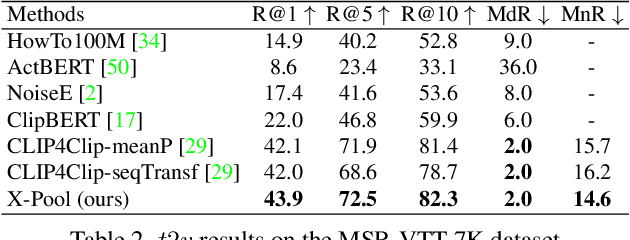
In text-video retrieval, the objective is to learn a cross-modal similarity function between a text and a video that ranks relevant text-video pairs higher than irrelevant pairs. However, videos inherently express a much wider gamut of information than texts. Instead, texts often capture sub-regions of entire videos and are most semantically similar to certain frames within videos. Therefore, for a given text, a retrieval model should focus on the text's most semantically similar video sub-regions to make a more relevant comparison. Yet, most existing works aggregate entire videos without directly considering text. Common text-agnostic aggregations schemes include mean-pooling or self-attention over the frames, but these are likely to encode misleading visual information not described in the given text. To address this, we propose a cross-modal attention model called X-Pool that reasons between a text and the frames of a video. Our core mechanism is a scaled dot product attention for a text to attend to its most semantically similar frames. We then generate an aggregated video representation conditioned on the text's attention weights over the frames. We evaluate our method on three benchmark datasets of MSR-VTT, MSVD and LSMDC, achieving new state-of-the-art results by up to 12% in relative improvement in Recall@1. Our findings thereby highlight the importance of joint text-video reasoning to extract important visual cues according to text. Full code and demo can be found at: https://layer6ai-labs.github.io/xpool/
Weakly Supervised Action Selection Learning in Video
May 06, 2021
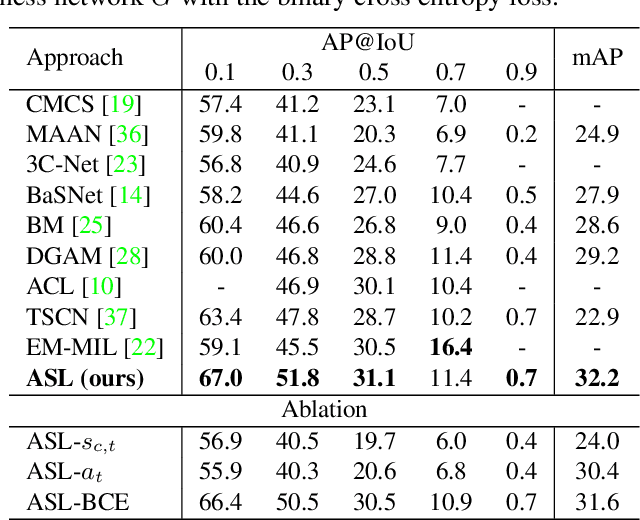
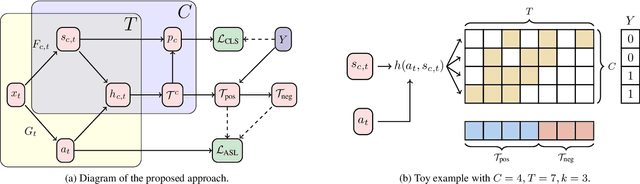
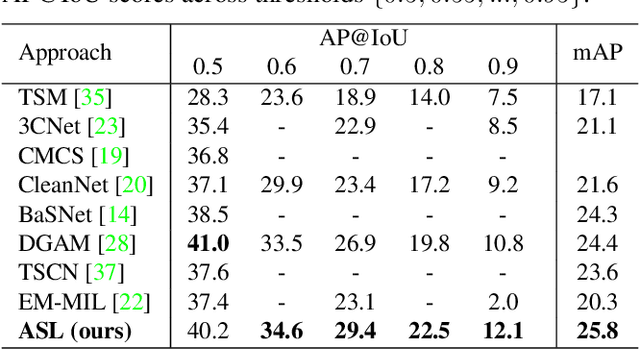
Localizing actions in video is a core task in computer vision. The weakly supervised temporal localization problem investigates whether this task can be adequately solved with only video-level labels, significantly reducing the amount of expensive and error-prone annotation that is required. A common approach is to train a frame-level classifier where frames with the highest class probability are selected to make a video-level prediction. Frame level activations are then used for localization. However, the absence of frame-level annotations cause the classifier to impart class bias on every frame. To address this, we propose the Action Selection Learning (ASL) approach to capture the general concept of action, a property we refer to as "actionness". Under ASL, the model is trained with a novel class-agnostic task to predict which frames will be selected by the classifier. Empirically, we show that ASL outperforms leading baselines on two popular benchmarks THUMOS-14 and ActivityNet-1.2, with 10.3% and 5.7% relative improvement respectively. We further analyze the properties of ASL and demonstrate the importance of actionness. Full code for this work is available here: https://github.com/layer6ai-labs/ASL.
Learning Effective Visual Relationship Detector on 1 GPU
Dec 12, 2019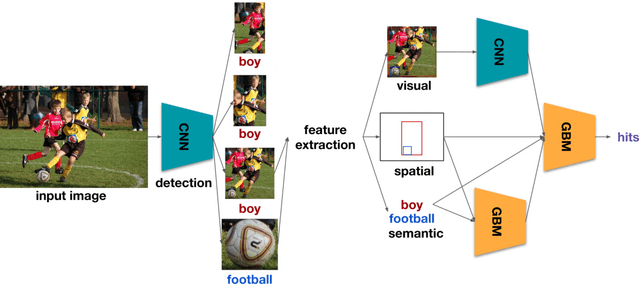
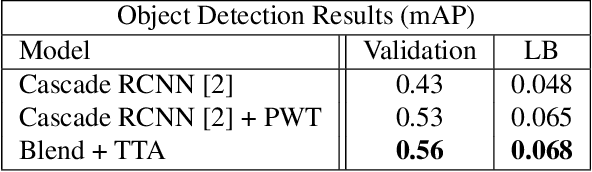
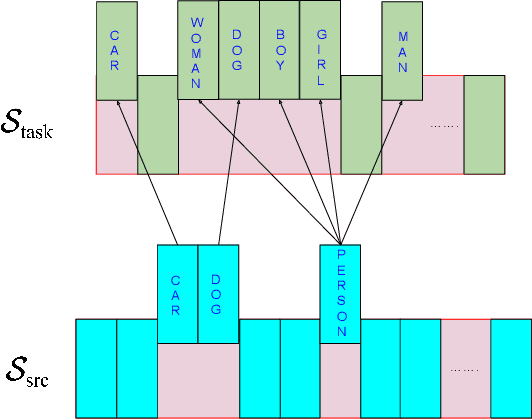
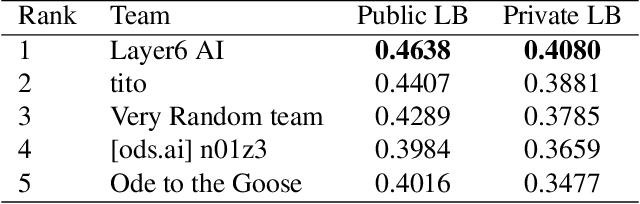
We present our winning solution to the Open Images 2019 Visual Relationship challenge. This is the largest challenge of its kind to date with nearly 9 million training images. Challenge task consists of detecting objects and identifying relationships between them in complex scenes. Our solution has three stages, first object detection model is fine-tuned for the challenge classes using a novel weight transfer approach. Then, spatio-semantic and visual relationship models are trained on candidate object pairs. Finally, features and model predictions are combined to generate the final relationship prediction. Throughout the challenge we focused on minimizing the hardware requirements of our architecture. Specifically, our weight transfer approach enables much faster optimization, allowing the entire architecture to be trained on a single GPU in under two days. In addition to efficient optimization, our approach also achieves superior accuracy winning first place out of over 200 teams, and outperforming the second place team by over $5\%$ on the held-out private leaderboard.