 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometric Framework for Understanding Memorization in Generative Models
Oct 31, 2024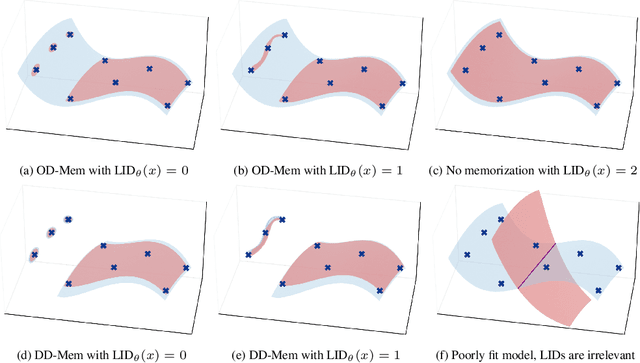

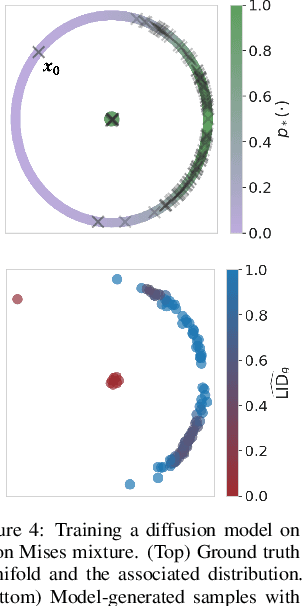
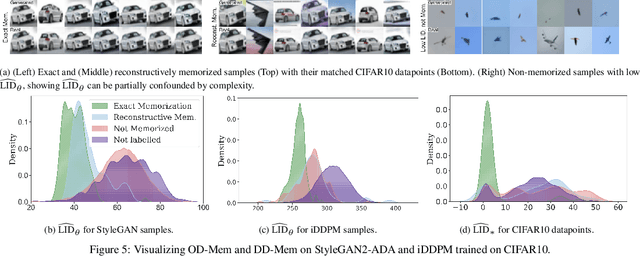
As deep generative models have progressed, recent work has shown them to be capable of memorizing and reproducing training datapoints when deployed. These findings call into question the usability of generative models, especially in light of the legal and privacy risks brought about by memorization. To better understand this phenomenon, we propose the manifold memorization hypothesis (MMH), a geometric framework which leverages the manifold hypothesis into a clear language in which to reason about memorization. We propose to analyze memorization in terms of the relationship between the dimensionalities of $(i)$ the ground truth data manifold and $(ii)$ the manifold learned by the model. This framework provides a formal standard for "how memorized" a datapoint is and systematically categorizes memorized data into two types: memorization driven by overfitting and memorization driven by the underlying data distribution. By analyzing prior work in the context of the MMH, we explain and unify assorted observations in the literature. We empirically validate the MMH using synthetic data and image datasets up to the scale of Stable Diffusion, developing new tools for detecting and preventing generation of memorized samples in the process.
Benchmarking Robust Self-Supervised Learning Across Diverse Downstream Tasks
Jul 18, 2024



Large-scale vision models have become integral in many applications due to their unprecedented performance and versatility across downstream tasks. However, the robustness of these foundation models has primarily been explored for a single task, namely image classification. The vulnerability of other common vision tasks, such as semantic segmentation and depth estimation, remains largely unknown. We present a comprehensive empirical evaluation of the adversarial robustness of self-supervised vision encoders across multiple downstream tasks. Our attacks operate in the encoder embedding space and at the downstream task output level. In both cases, current state-of-the-art adversarial fine-tuning techniques tested only for classification significantly degrade clean and robust performance on other tasks. Since the purpose of a foundation model is to cater to multiple applications at once, our findings reveal the need to enhance encoder robustness more broadly. Our code is available at ${github.com/layer6ai-labs/ssl-robustness}$.
TabPFGen -- Tabular Data Generation with TabPFN
Jun 07, 2024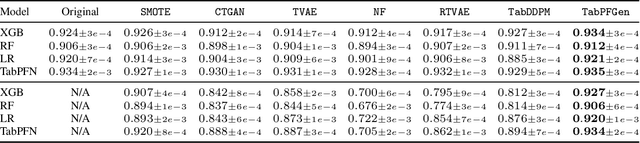
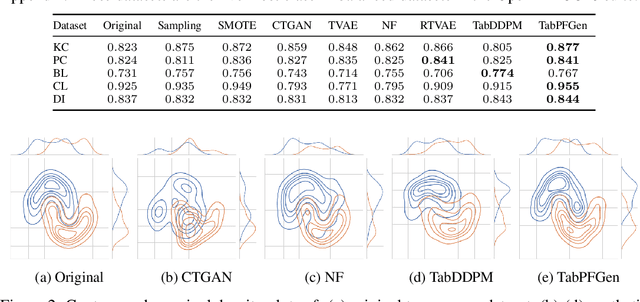
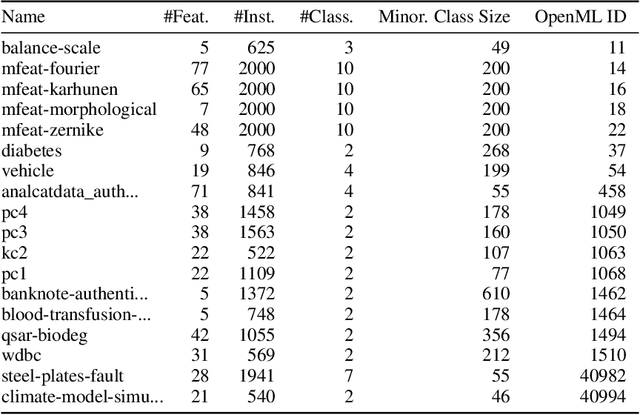
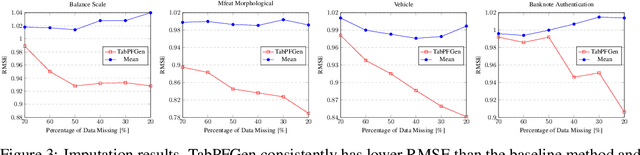
Advances in deep generative modelling have not translated well to tabular data. We argue that this is caused by a mismatch in structure between popular generative models and discriminative models of tabular data. We thus devise a technique to turn TabPFN -- a highly performant transformer initially designed for in-context discriminative tabular tasks -- into an energy-based generative model, which we dub TabPFGen. This novel framework leverages the pre-trained TabPFN as part of the energy function and does not require any additional training or hyperparameter tuning, thus inheriting TabPFN's in-context learning capability. We can sample from TabPFGen analogously to other energy-based models. We demonstrate strong results on standard generative modelling tasks, including data augmentation, class-balancing, and imputation, unlocking a new frontier of tabular data generation.
Self-supervised Representation Learning From Random Data Projectors
Oct 11, 2023

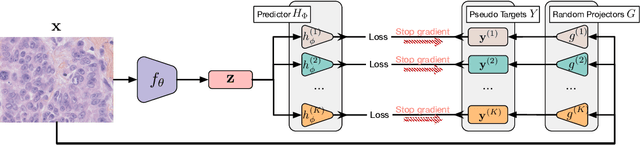
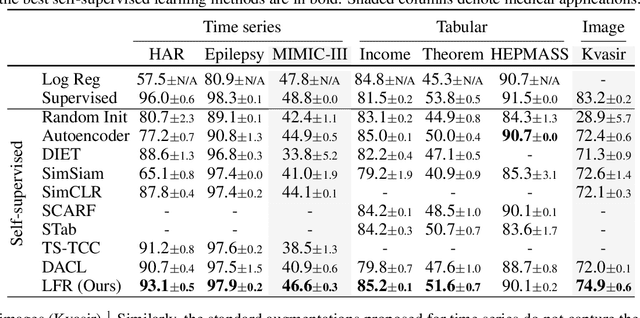
Self-supervised representation learning~(SSRL) has advanced considerably by exploiting the transformation invariance assumption under artificially designed data augmentations. While augmentation-based SSRL algorithms push the boundaries of performance in computer vision and natural language processing, they are often not directly applicable to other data modalities, and can conflict with application-specific data augmentation constraints. This paper presents an SSRL approach that can be applied to any data modality and network architecture because it does not rely on augmentations or masking. Specifically, we show that high-quality data representations can be learned by reconstructing random data projections. We evaluate the proposed approach on a wide range of representation learning tasks that span diverse modalities and real-world applications. We show that it outperforms multiple state-of-the-art SSRL baselines. Due to its wide applicability and strong empirical results, we argue that learning from randomness is a fruitful research direction worthy of attention and further study.
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models
Jun 07, 2023



We systematically study a wide variety of image-based generative models spanning semantically-diverse datasets to understand and improve the feature extractors and metrics used to evaluate them. Using best practices in psychophysics, we measure human perception of image realism for generated samples by conducting the largest experiment evaluating generative models to date, and find that no existing metric strongly correlates with human evaluations. Comparing to 16 modern metrics for evaluating the overall performance, fidelity, diversity, and memorization of generative models, we find that the state-of-the-art perceptual realism of diffusion models as judged by humans is not reflected in commonly reported metrics such as FID. This discrepancy is not explained by diversity in generated samples, though one cause is over-reliance on Inception-V3. We address these flaws through a study of alternative self-supervised feature extractors, find that the semantic information encoded by individual networks strongly depends on their training procedure, and show that DINOv2-ViT-L/14 allows for much richer evaluation of generative models. Next, we investigate data memorization, and find that generative models do memorize training examples on simple, smaller datasets like CIFAR10, but not necessarily on more complex datasets like ImageNet. However, our experiments show that current metrics do not properly detect memorization; none in the literature is able to separate memorization from other phenomena such as underfitting or mode shrinkage. To facilitate further development of generative models and their evaluation we release all generated image datasets, human evaluation data, and a modular library to compute 16 common metrics for 8 different encoders at https://github.com/layer6ai-labs/dgm-eval.
A Probabilistic Autoencoder for Type Ia Supernovae Spectral Time Series
Jul 15, 2022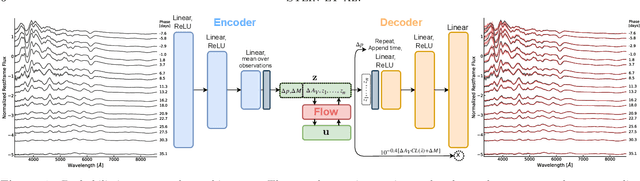
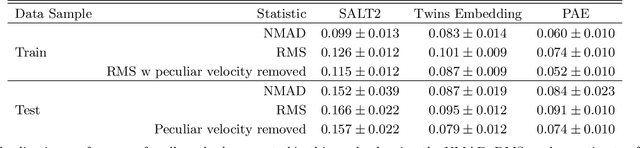
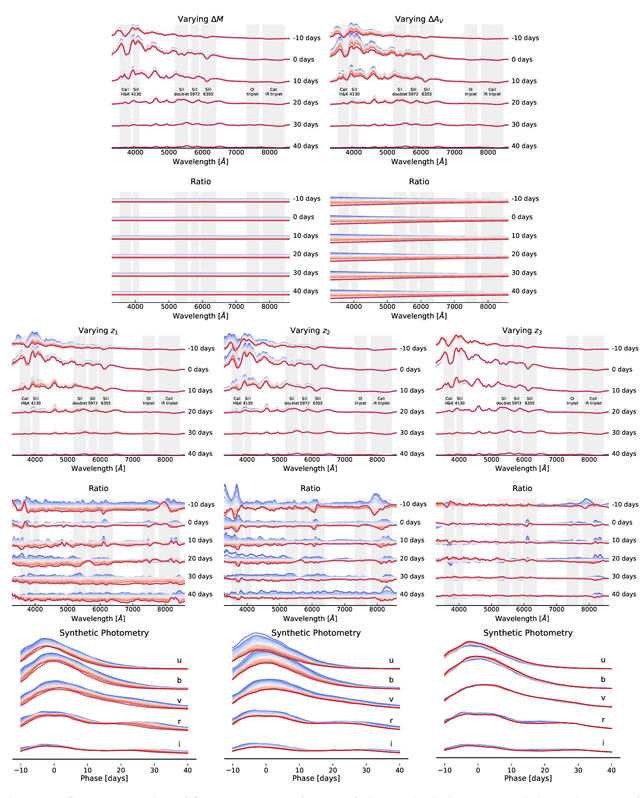
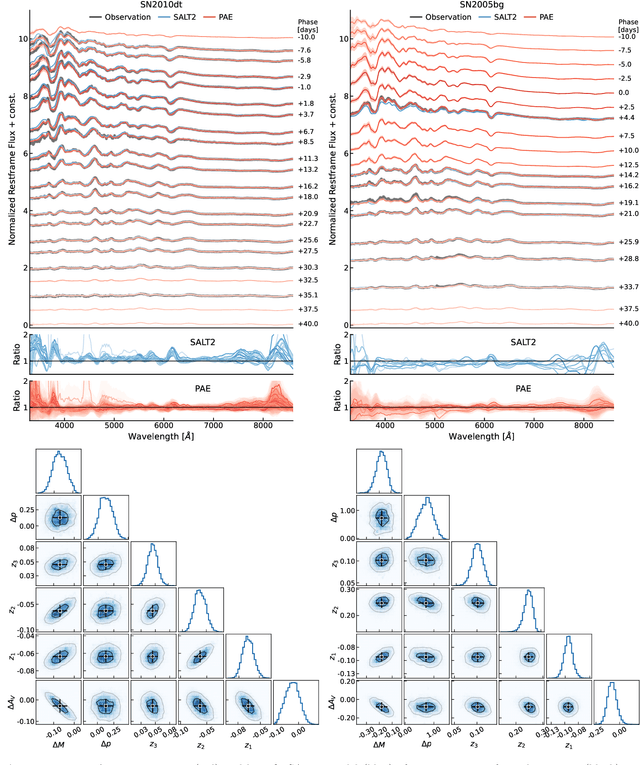
We construct a physically-parameterized probabilistic autoencoder (PAE) to learn the intrinsic diversity of type Ia supernovae (SNe Ia) from a sparse set of spectral time series. The PAE is a two-stage generative model, composed of an Auto-Encoder (AE) which is interpreted probabilistically after training using a Normalizing Flow (NF). We demonstrate that the PAE learns a low-dimensional latent space that captures the nonlinear range of features that exists within the population, and can accurately model the spectral evolution of SNe Ia across the full range of wavelength and observation times directly from the data. By introducing a correlation penalty term and multi-stage training setup alongside our physically-parameterized network we show that intrinsic and extrinsic modes of variability can be separated during training, removing the need for the additional models to perform magnitude standardization. We then use our PAE in a number of downstream tasks on SNe Ia for increasingly precise cosmological analyses, including automatic detection of SN outliers, the generation of samples consistent with the data distribution, and solving the inverse problem in the presence of noisy and incomplete data to constrain cosmological distance measurements. We find that the optimal number of intrinsic model parameters appears to be three, in line with previous studies, and show that we can standardize our test sample of SNe Ia with an RMS of $0.091 \pm 0.010$ mag, which corresponds to $0.074 \pm 0.010$ mag if peculiar velocity contributions are removed. Trained models and codes are released at \href{https://github.com/georgestein/suPAErnova}{github.com/georgestein/suPAErnova}
Self-supervised similarity search for large scientific datasets
Oct 25, 2021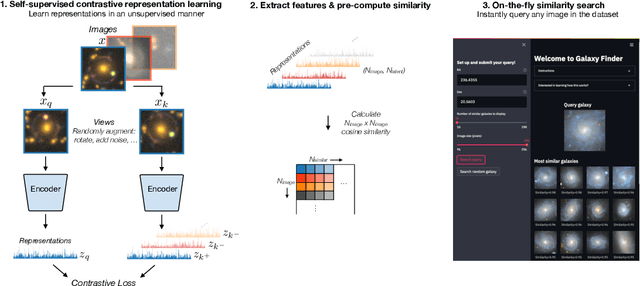

We present the use of self-supervised learning to explore and exploit large unlabeled datasets. Focusing on 42 million galaxy images from the latest data release of the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Surveys, we first train a self-supervised model to distil low-dimensional representations that are robust to symmetries, uncertainties, and noise in each image. We then use the representations to construct and publicly release an interactive semantic similarity search tool. We demonstrate how our tool can be used to rapidly discover rare objects given only a single example, increase the speed of crowd-sourcing campaigns, and construct and improve training sets for supervised applications. While we focus on images from sky surveys, the technique is straightforward to apply to any scientific dataset of any dimensionality. The similarity search web app can be found at https://github.com/georgestein/galaxy_search
Mining for strong gravitational lenses with self-supervised learning
Sep 30, 2021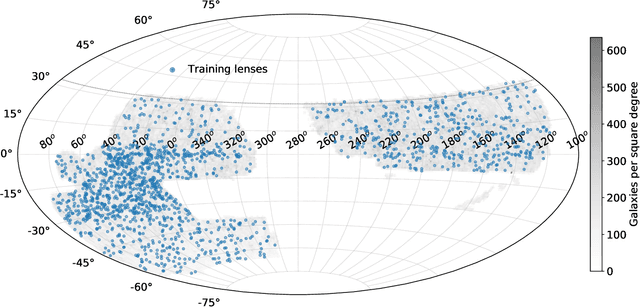
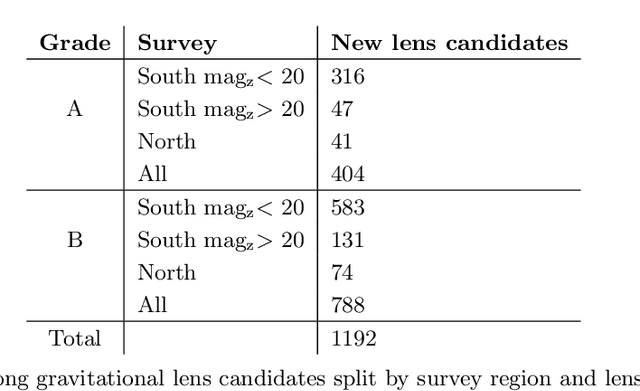
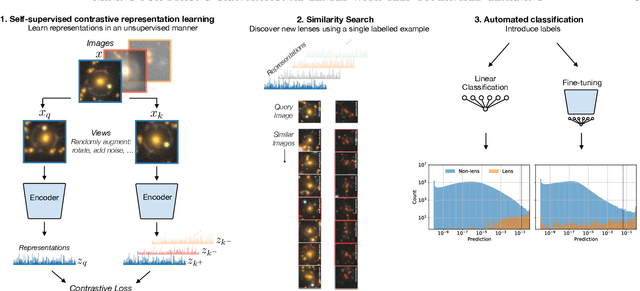

We employ self-supervised representation learning to distill information from 76 million galaxy images from the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Surveys' Data Release 9. Targeting the identification of new strong gravitational lens candidates, we first create a rapid similarity search tool to discover new strong lenses given only a single labelled example. We then show how training a simple linear classifier on the self-supervised representations, requiring only a few minutes on a CPU, can automatically classify strong lenses with great efficiency. We present 1192 new strong lens candidates that we identified through a brief visual identification campaign, and release an interactive web-based similarity search tool and the top network predictions to facilitate crowd-sourcing rapid discovery of additional strong gravitational lenses and other rare objects: github.com/georgestein/ssl-legacysurvey
Estimating Galactic Distances From Images Using Self-supervised Representation Learning
Jan 12, 2021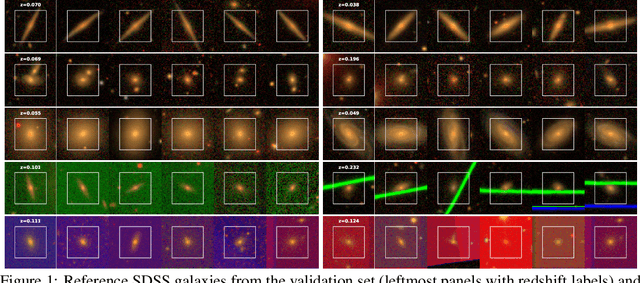
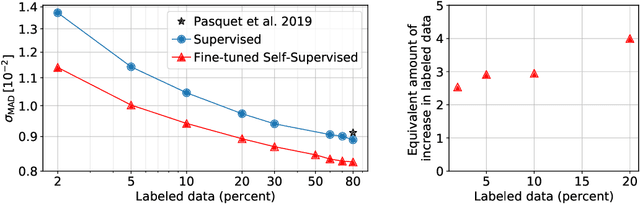
We use a contrastive self-supervised learning framework to estimate distances to galaxies from their photometric images. We incorporate data augmentations from computer vision as well as an application-specific augmentation accounting for galactic dust. We find that the resulting visual representations of galaxy images are semantically useful and allow for fast similarity searches, and can be successfully fine-tuned for the task of redshift estimation. We show that (1) pretraining on a large corpus of unlabeled data followed by fine-tuning on some labels can attain the accuracy of a fully-supervised model which requires 2-4x more labeled data, and (2) that by fine-tuning our self-supervised representations using all available data labels in the Main Galaxy Sample of the Sloan Digital Sky Survey (SDSS), we outperform the state-of-the-art supervised learning method.
Self-Supervised Representation Learning for Astronomical Images
Dec 24, 2020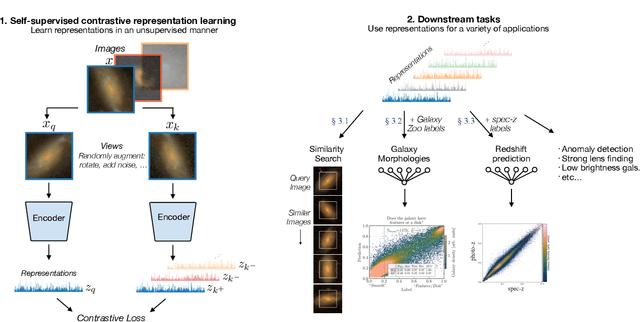

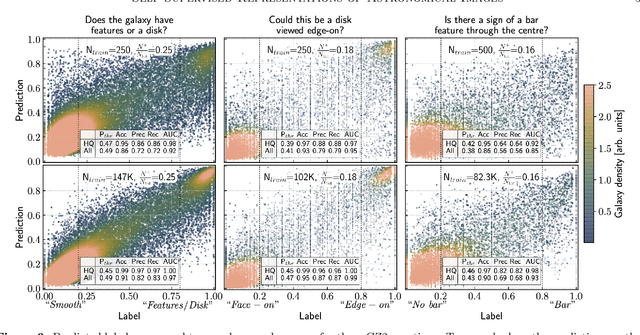
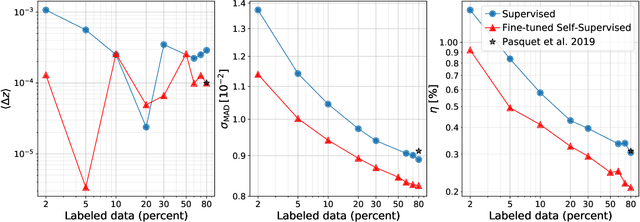
Sky surveys are the largest data generators in astronomy, making automated tools for extracting meaningful scientific information an absolute necessity. We show that, without the need for labels, self-supervised learning recovers representations of sky survey images that are semantically useful for a variety of scientific tasks. These representations can be directly used as features, or fine-tuned, to outperform supervised methods trained only on labeled data. We apply a contrastive learning framework on multi-band galaxy photometry from the Sloan Digital Sky Survey (SDSS) to learn image representations. We then use them for galaxy morphology classification, and fine-tune them for photometric redshift estimation, using labels from the Galaxy Zoo 2 dataset and SDSS spectroscopy. In both downstream tasks, using the same learned representations, we outperform the supervised state-of-the-art results, and we show that our approach can achieve the accuracy of supervised models while using 2-4 times fewer labels for training.