 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperBench: A Super-Resolution Benchmark Dataset for Scientific Machine Learning
Jun 24, 2023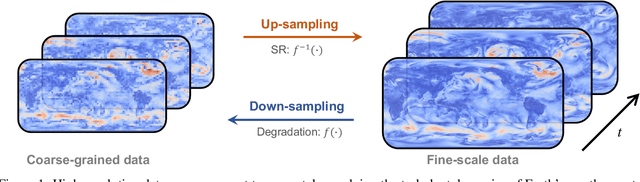

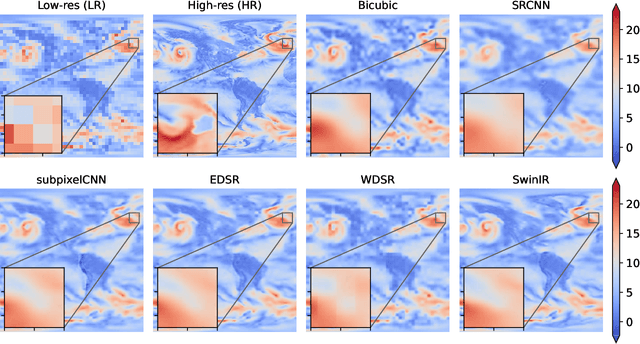

Super-Resolution (SR) techniques aim to enhance data resolution, enabling the retrieval of finer details, and improving the overall quality and fidelity of the data representation. There is growing interest in applying SR methods to complex spatiotemporal systems within the Scientific Machine Learning (SciML) community, with the hope of accelerating numerical simulations and/or improving forecasts in weather, climate, and related areas. However, the lack of standardized benchmark datasets for comparing and validating SR methods hinders progress and adoption in SciML. To address this, we introduce SuperBench, the first benchmark dataset featuring high-resolution datasets (up to $2048\times2048$ dimensions), including data from fluid flows, cosmology, and weather. Here, we focus on validating spatial SR performance from data-centric and physics-preserved perspectives, as well as assessing robustness to data degradation tasks. While deep learning-based SR methods (developed in the computer vision community) excel on certain tasks, despite relatively limited prior physics information, we identify limitations of these methods in accurately capturing intricate fine-scale features and preserving fundamental physical properties and constraints in scientific data. These shortcomings highlight the importance and subtlety of incorporating domain knowledge into ML models. We anticipate that SuperBench will significantly advance SR methods for scientific tasks.
Self-supervised similarity search for large scientific datasets
Oct 25, 2021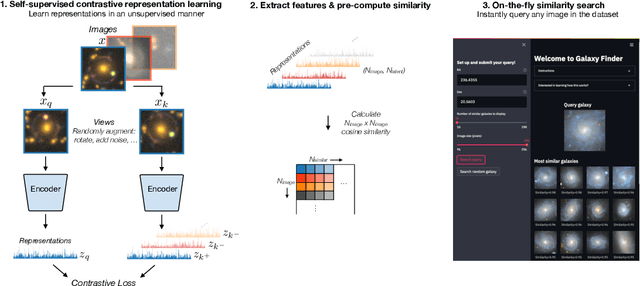

We present the use of self-supervised learning to explore and exploit large unlabeled datasets. Focusing on 42 million galaxy images from the latest data release of the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Surveys, we first train a self-supervised model to distil low-dimensional representations that are robust to symmetries, uncertainties, and noise in each image. We then use the representations to construct and publicly release an interactive semantic similarity search tool. We demonstrate how our tool can be used to rapidly discover rare objects given only a single example, increase the speed of crowd-sourcing campaigns, and construct and improve training sets for supervised applications. While we focus on images from sky surveys, the technique is straightforward to apply to any scientific dataset of any dimensionality. The similarity search web app can be found at https://github.com/georgestein/galaxy_search
Mining for strong gravitational lenses with self-supervised learning
Sep 30, 2021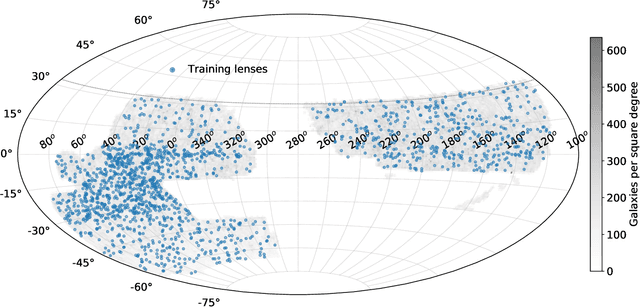
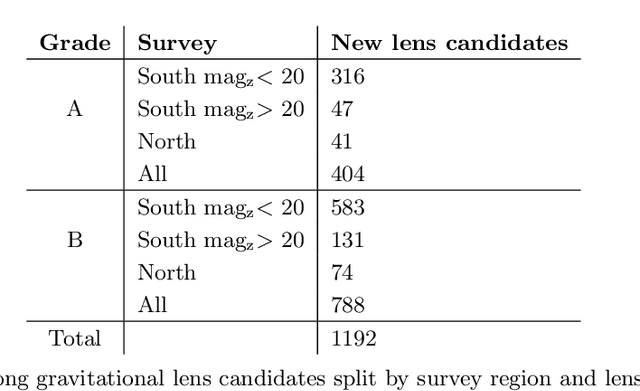
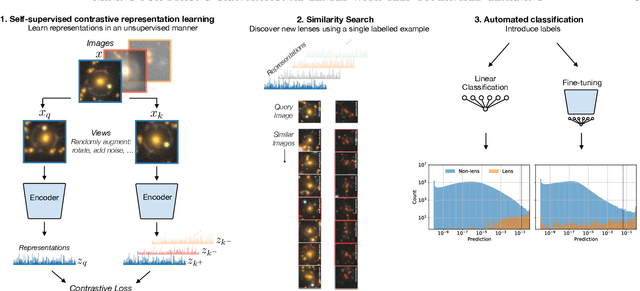

We employ self-supervised representation learning to distill information from 76 million galaxy images from the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Surveys' Data Release 9. Targeting the identification of new strong gravitational lens candidates, we first create a rapid similarity search tool to discover new strong lenses given only a single labelled example. We then show how training a simple linear classifier on the self-supervised representations, requiring only a few minutes on a CPU, can automatically classify strong lenses with great efficiency. We present 1192 new strong lens candidates that we identified through a brief visual identification campaign, and release an interactive web-based similarity search tool and the top network predictions to facilitate crowd-sourcing rapid discovery of additional strong gravitational lenses and other rare objects: github.com/georgestein/ssl-legacysurvey