 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Representation Learning From Random Data Projectors
Oct 11, 2023

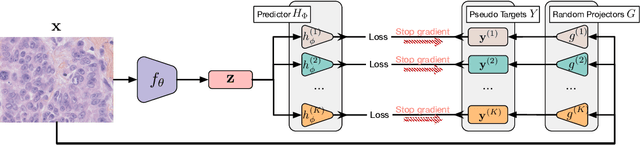
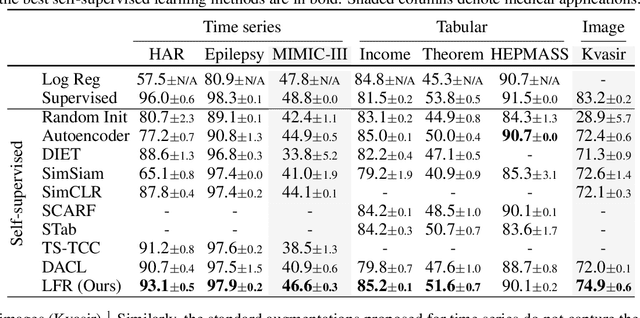
Self-supervised representation learning~(SSRL) has advanced considerably by exploiting the transformation invariance assumption under artificially designed data augmentations. While augmentation-based SSRL algorithms push the boundaries of performance in computer vision and natural language processing, they are often not directly applicable to other data modalities, and can conflict with application-specific data augmentation constraints. This paper presents an SSRL approach that can be applied to any data modality and network architecture because it does not rely on augmentations or masking. Specifically, we show that high-quality data representations can be learned by reconstructing random data projections. We evaluate the proposed approach on a wide range of representation learning tasks that span diverse modalities and real-world applications. We show that it outperforms multiple state-of-the-art SSRL baselines. Due to its wide applicability and strong empirical results, we argue that learning from randomness is a fruitful research direction worthy of attention and further study.
DuETT: Dual Event Time Transformer for Electronic Health Records
Apr 25, 2023Electronic health records (EHRs) recorded in hospital settings typically contain a wide range of numeric time series data that is characterized by high sparsity and irregular observations. Effective modelling for such data must exploit its time series nature, the semantic relationship between different types of observations, and information in the sparsity structure of the data. Self-supervised Transformers have shown outstanding performance in a variety of structured tasks in NLP and computer vision. But multivariate time series data contains structured relationships over two dimensions: time and recorded event type, and straightforward applications of Transformers to time series data do not leverage this distinct structure. The quadratic scaling of self-attention layers can also significantly limit the input sequence length without appropriate input engineering. We introduce the DuETT architecture, an extension of Transformers designed to attend over both time and event type dimensions, yielding robust representations from EHR data. DuETT uses an aggregated input where sparse time series are transformed into a regular sequence with fixed length; this lowers the computational complexity relative to previous EHR Transformer models and, more importantly, enables the use of larger and deeper neural networks. When trained with self-supervised prediction tasks, that provide rich and informative signals for model pre-training, our model outperforms state-of-the-art deep learning models on multiple downstream tasks from the MIMIC-IV and PhysioNet-2012 EHR datasets.