 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuETT: Dual Event Time Transformer for Electronic Health Records
Apr 25, 2023Electronic health records (EHRs) recorded in hospital settings typically contain a wide range of numeric time series data that is characterized by high sparsity and irregular observations. Effective modelling for such data must exploit its time series nature, the semantic relationship between different types of observations, and information in the sparsity structure of the data. Self-supervised Transformers have shown outstanding performance in a variety of structured tasks in NLP and computer vision. But multivariate time series data contains structured relationships over two dimensions: time and recorded event type, and straightforward applications of Transformers to time series data do not leverage this distinct structure. The quadratic scaling of self-attention layers can also significantly limit the input sequence length without appropriate input engineering. We introduce the DuETT architecture, an extension of Transformers designed to attend over both time and event type dimensions, yielding robust representations from EHR data. DuETT uses an aggregated input where sparse time series are transformed into a regular sequence with fixed length; this lowers the computational complexity relative to previous EHR Transformer models and, more importantly, enables the use of larger and deeper neural networks. When trained with self-supervised prediction tasks, that provide rich and informative signals for model pre-training, our model outperforms state-of-the-art deep learning models on multiple downstream tasks from the MIMIC-IV and PhysioNet-2012 EHR datasets.
Confounding Feature Acquisition for Causal Effect Estimation
Nov 17, 2020
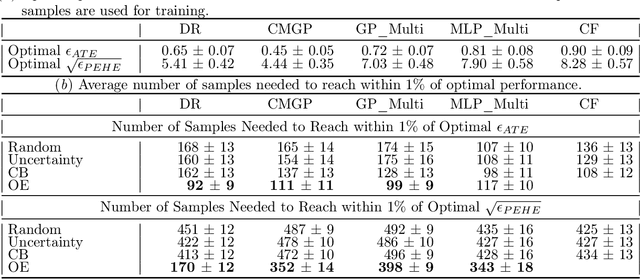
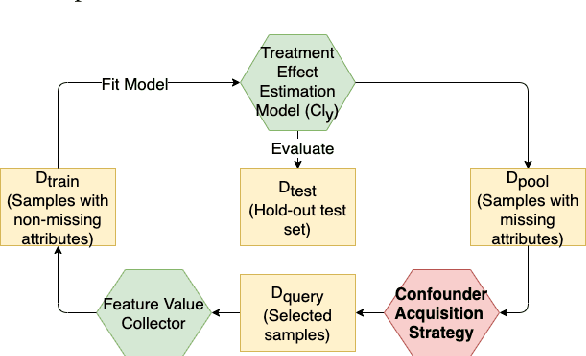

Reliable treatment effect estimation from observational data depends on the availability of all confounding information. While much work has targeted treatment effect estimation from observational data, there is relatively little work in the setting of confounding variable missingness, where collecting more information on confounders is often costly or time-consuming. In this work, we frame this challenge as a problem of feature acquisition of confounding features for causal inference. Our goal is to prioritize acquiring values for a fixed and known subset of missing confounders in samples that lead to efficient average treatment effect estimation. We propose two acquisition strategies based on i) covariate balancing (CB), and ii) reducing statistical estimation error on observed factual outcome error (OE). We compare CB and OE on five common causal effect estimation methods, and demonstrate improved sample efficiency of OE over baseline methods under various settings. We also provide visualizations for further analysis on the difference between our proposed methods.
A Comparison of LSTMs and Attention Mechanisms for Forecasting Financial Time Series
Dec 18, 2018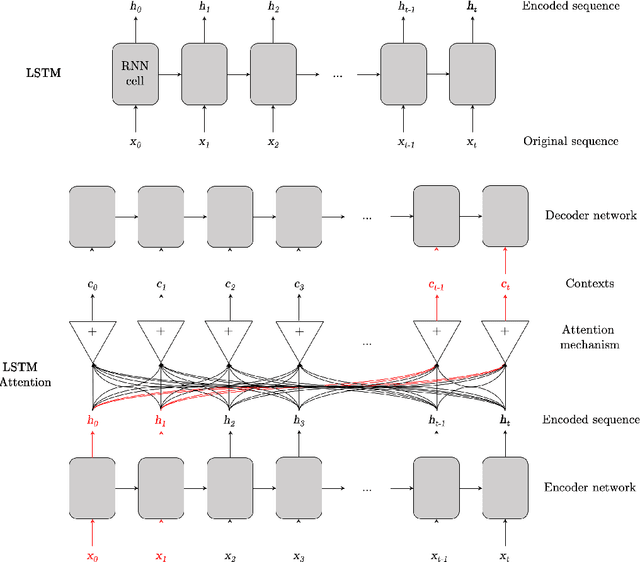
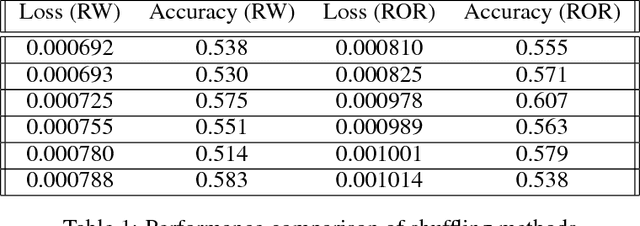
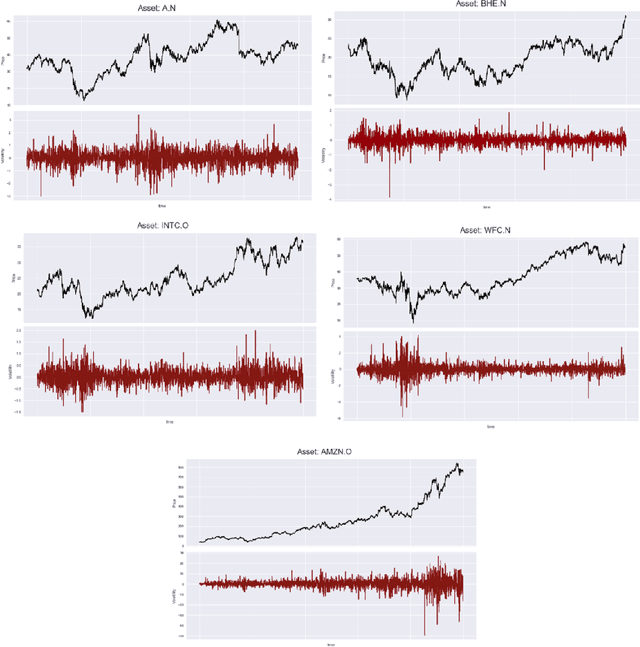
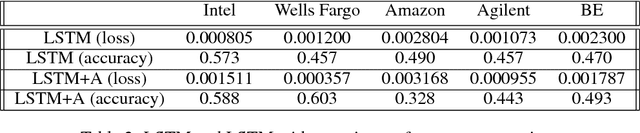
While LSTMs show increasingly promising results for forecasting Financial Time Series (FTS), this paper seeks to assess if attention mechanisms can further improve performance. The hypothesis is that attention can help prevent long-term dependencies experienced by LSTM models. To test this hypothesis, the main contribution of this paper is the implementation of an LSTM with attention. Both the benchmark LSTM and the LSTM with attention were compared and both achieved reasonable performances of up to 60% on five stocks from Kaggle's Two Sigma dataset. This comparative analysis demonstrates that an LSTM with attention can indeed outperform standalone LSTMs but further investigation is required as issues do arise with such model architectures.