 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARDoc: A Memory-Aware Refinement Agent Framework for Multimodal Long Document QA
Jun 04, 2026Iterative retrieval-reasoning agents have recently shown promise for multimodal long-document question answering. However, most existing systems maintain a single growing context that mixes retrieval traces, observations, and intermediate reasoning. As interactions accumulate, key evidence becomes scattered and diluted, making multi-hop reasoning noisy. We propose MARDoc, a Memory-Aware Refinement Agent framework that decouples long-document QA into three specialized agents: an Explorer for multi-granularity multimodal retrieval, a Refiner for distilling interaction traces into structured evidence and reasoning memories, and a Reflector for checking evidence sufficiency and providing targeted feedback. Across iterations, the agents rely on a dynamically updated structured memory rather than a full accumulated interaction history. This design reduces context noise while preserving answer-critical facts and their logical dependencies. Experiments on MMLongBench-Doc and DocBench show that MARDoc achieves strong results, outperforming same-backbone baselines and demonstrating the effectiveness of structured memory for agentic document QA.
Physical Layer Security Performance of Pinching-Antenna Systems With In-Waveguide Attenuation
Apr 16, 2026Pinching antenna (PA) systems have recently gained significant attention. While their physical-layer security (PLS) is being explored, most studies rely on idealized lossless models, ignoring practical waveguide attenuation. In this paper, we investigate the PLS performance of PA systems under a more realistic attenuation-incorporated waveguide model. Specifically, we investigate a PA system-based secure communication scenario consisting of a base station (BS), a legitimate user, and a passive eavesdropper. We derive expressions for closed-form upper and lower bounds on both the secrecy outage probability (SOP) and ergodic secrecy capacity (ESC). The results indicate that the PA system outperforms conventional fixed-antenna systems.
Knockoff-Guided Compressive Sensing: A Statistical Machine Learning Framework for Support-Assured Signal Recovery
May 30, 2025This paper introduces a novel Knockoff-guided compressive sensing framework, referred to as \TheName{}, which enhances signal recovery by leveraging precise false discovery rate (FDR) control during the support identification phase. Unlike LASSO, which jointly performs support selection and signal estimation without explicit error control, our method guarantees FDR control in finite samples, enabling more reliable identification of the true signal support. By separating and controlling the support recovery process through statistical Knockoff filters, our framework achieves more accurate signal reconstruction, especially in challenging scenarios where traditional methods fail. We establish theoretical guarantees demonstrating how FDR control directly ensures recovery performance under weaker conditions than traditional $\ell_1$-based compressive sensing methods, while maintaining accurate signal reconstruction. Extensive numerical experiments demonstrate that our proposed Knockoff-based method consistently outperforms LASSO-based and other state-of-the-art compressive sensing techniques. In simulation studies, our method improves F1-score by up to 3.9x over baseline methods, attributed to principled false discovery rate (FDR) control and enhanced support recovery. The method also consistently yields lower reconstruction and relative errors. We further validate the framework on real-world datasets, where it achieves top downstream predictive performance across both regression and classification tasks, often narrowing or even surpassing the performance gap relative to uncompressed signals. These results establish \TheName{} as a robust and practical alternative to existing approaches, offering both theoretical guarantees and strong empirical performance through statistically grounded support selection.
Knoop: Practical Enhancement of Knockoff with Over-Parameterization for Variable Selection
Jan 28, 2025Variable selection plays a crucial role in enhancing modeling effectiveness across diverse fields, addressing the challenges posed by high-dimensional datasets of correlated variables. This work introduces a novel approach namely Knockoff with over-parameterization (Knoop) to enhance Knockoff filters for variable selection. Specifically, Knoop first generates multiple knockoff variables for each original variable and integrates them with the original variables into an over-parameterized Ridgeless regression model. For each original variable, Knoop evaluates the coefficient distribution of its knockoffs and compares these with the original coefficients to conduct an anomaly-based significance test, ensuring robust variable selection. Extensive experiments demonstrate superior performance compared to existing methods in both simulation and real-world datasets. Knoop achieves a notably higher Area under the Curve (AUC) of the Receiver Operating Characteristic (ROC) Curve for effectively identifying relevant variables against the ground truth by controlled simulations, while showcasing enhanced predictive accuracy across diverse regression and classification tasks. The analytical results further backup our observations.
* An earlier version of our paper at Machine Learning
Self-supervised Representation Learning From Random Data Projectors
Oct 11, 2023

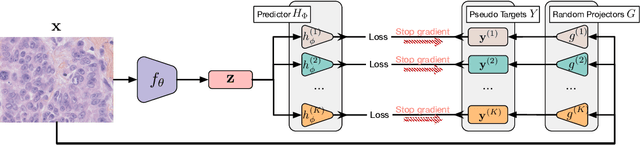
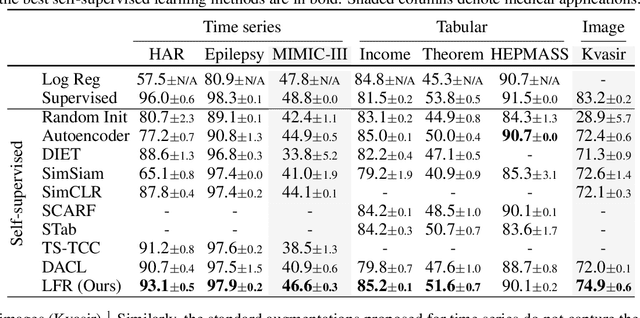
Self-supervised representation learning~(SSRL) has advanced considerably by exploiting the transformation invariance assumption under artificially designed data augmentations. While augmentation-based SSRL algorithms push the boundaries of performance in computer vision and natural language processing, they are often not directly applicable to other data modalities, and can conflict with application-specific data augmentation constraints. This paper presents an SSRL approach that can be applied to any data modality and network architecture because it does not rely on augmentations or masking. Specifically, we show that high-quality data representations can be learned by reconstructing random data projections. We evaluate the proposed approach on a wide range of representation learning tasks that span diverse modalities and real-world applications. We show that it outperforms multiple state-of-the-art SSRL baselines. Due to its wide applicability and strong empirical results, we argue that learning from randomness is a fruitful research direction worthy of attention and further study.
Emotion Detection in Unfix-length-Context Conversation
Feb 13, 2023We leverage different context windows when predicting the emotion of different utterances. New modules are included to realize variable-length context: 1) two speaker-aware units, which explicitly model inner- and inter-speaker dependencies to form distilled conversational context, and 2) a top-k normalization layer, which determines the most proper context windows from the conversational context to predict emotion. Experiments and ablation studies show that our approach outperforms several strong baselines on three public datasets.
Scalable Power Control/Beamforming in Heterogeneous Wireless Networks with Graph Neural Networks
Apr 12, 2021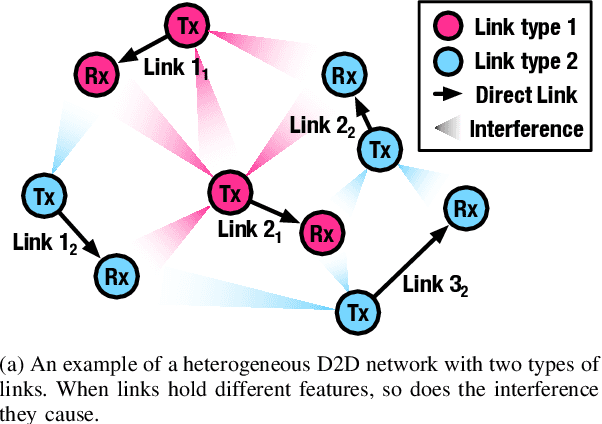
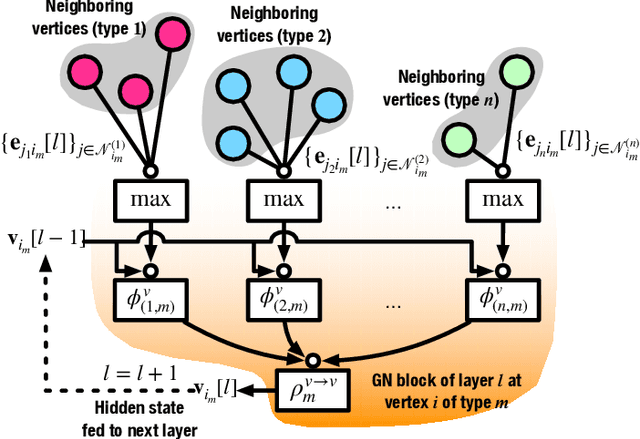
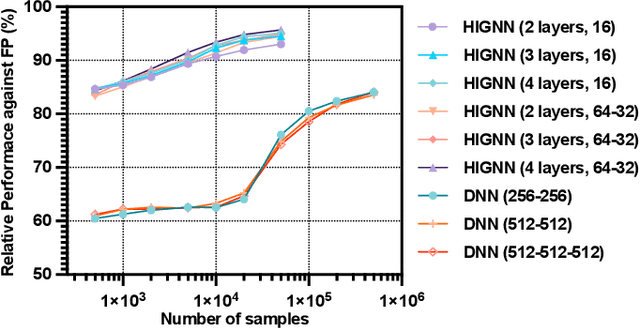
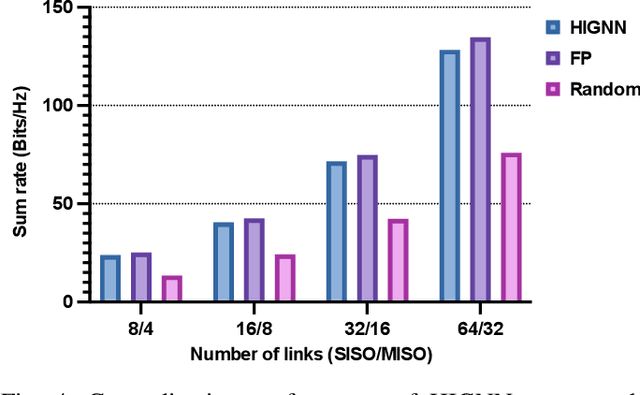
Machine learning (ML) has been widely used for efficient resource allocation (RA) in wireless networks. Although superb performance is achieved on small and simple networks, most existing ML-based approaches are confronted with difficulties when heterogeneity occurs and network size expands. In this paper, specifically focusing on power control/beamforming (PC/BF) in heterogeneous device-to-device (D2D) networks, we propose a novel unsupervised learning-based framework named heterogeneous interference graph neural network (HIGNN) to handle these challenges. First, we characterize diversified link features and interference relations with heterogeneous graphs. Then, HIGNN is proposed to empower each link to obtain its individual transmission scheme after limited information exchange with neighboring links. It is noteworthy that HIGNN is scalable to wireless networks of growing sizes with robust performance after trained on small-sized networks. Numerical results show that compared with state-of-the-art benchmarks, HIGNN achieves much higher execution efficiency while providing strong performance.
Fine Timing and Frequency Synchronization for MIMO-OFDM: An Extreme Learning Approach
Jul 17, 2020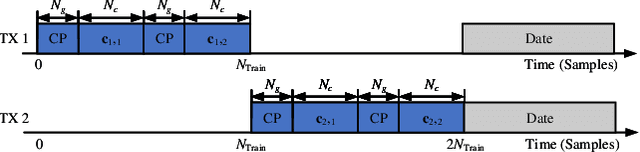
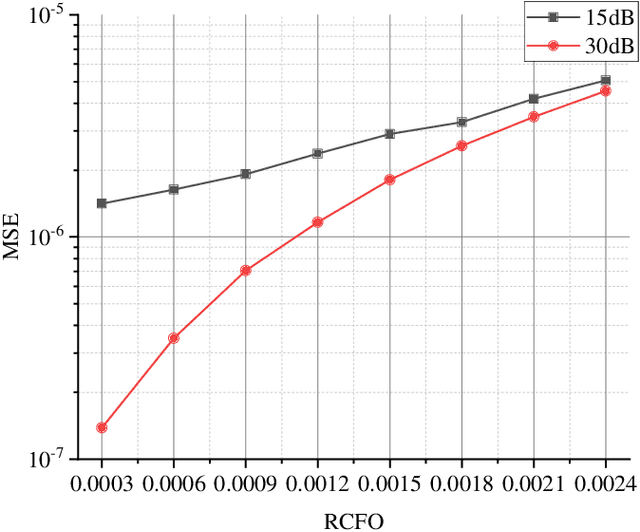
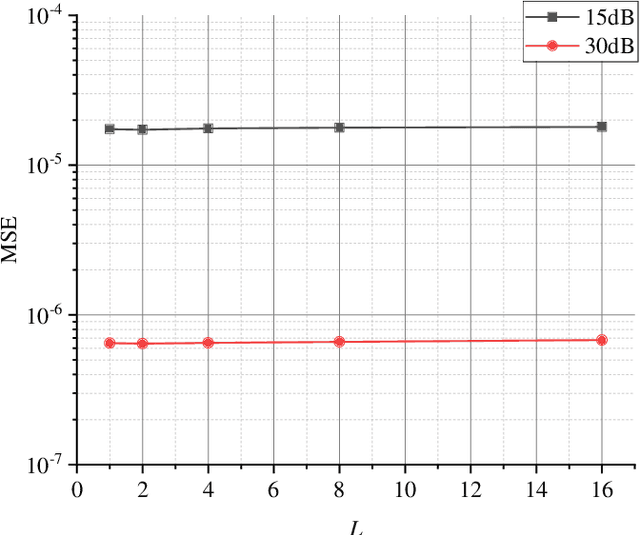
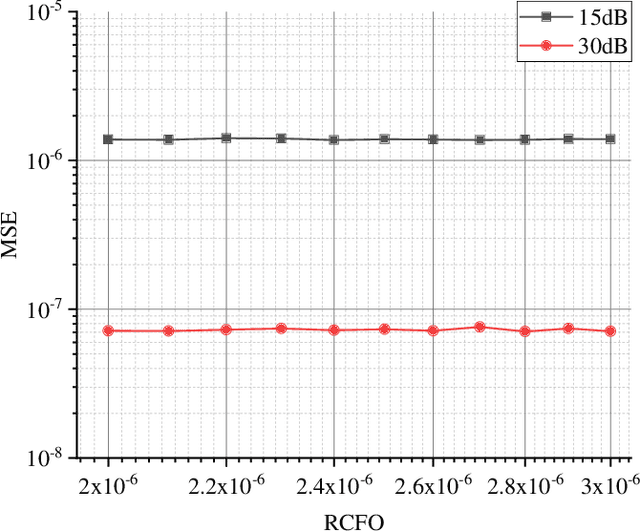
Multiple-input multiple-output orthogonal frequency-division multiplexing (MIMO-OFDM) is a key technology component in the evolution towards next-generation communication in which the accuracy of timing and frequency synchronization significantly impacts the overall system performance. In this paper, we propose a novel scheme leveraging extreme learning machine (ELM) to achieve high-precision timing and frequency synchronization. Specifically, two ELMs are incorporated into a traditional MIMO-OFDM system to estimate both the residual symbol timing offset (RSTO) and the residual carrier frequency offset (RCFO). The simulation results show that the performance of an ELM-based synchronization scheme is superior to the traditional method under both additive white Gaussian noise (AWGN) and frequency selective fading channels. Finally, the proposed method is robust in terms of choice of channel parameters (e.g., number of paths) and also in terms of "generalization ability" from a machine learning standpoint.
Machine Learning Based Channel Estimation: A Computational Approach for Universal Channel Conditions
Nov 10, 2019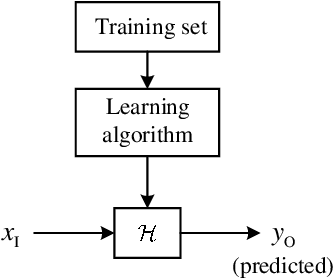
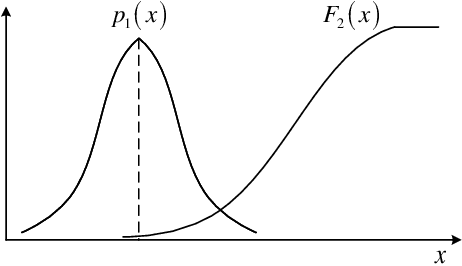
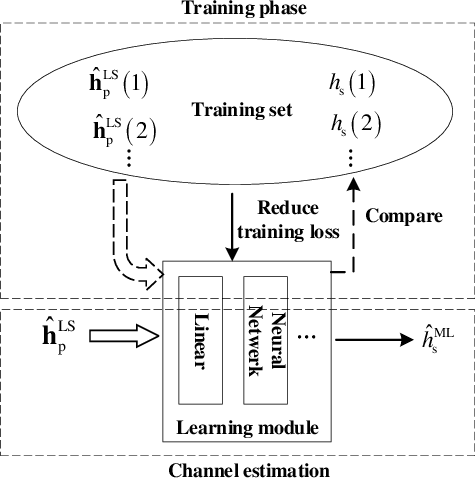
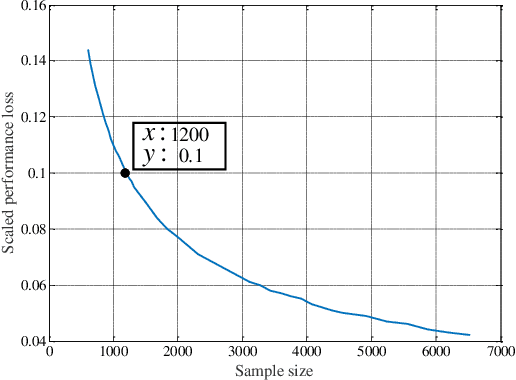
Recently, machine learning has been introduced in communications to deal with channel estimation. Under non-linear system models, the superiority of machine learning based estimation has been demonstrated by simulation expriments, but the theoretical analysis is not sufficient, since the performance of machine learning, especially deep learning, is hard to analyze. This paper focuses on some theoretical problems in machine learning based channel estimation. As a data-driven method, certain amount of training data is the prerequisite of a workable machine learning based estimation, and it is analyzed qualitively in a statistic view in this paper. To deduce the exact sample size, we build a statistic model ignoring the exact structure of the learning module and then the relationship between sample size and learning performance is derived. To testify our analysis, we employ machine learning based channel estimation in OFDM system and apply two typical neural networks as the learning module: single layer or linear structure and three layer structure. The simulation results show that the analysis sample size is correct when input dimension and complexity of learning module are low, but the true required sample size will be larger the analysis result otherwise, since the influence of the two factors is not considered in the analysis of sample size. Also, we simulate the performance of machine learning based channel estimation under quasi-stationary channel condition, where the explicit form of MMSE estimation is hard to obtain, and the simulation results exhibit the effectiveness and convenience of machine learning based channel estimation under complex channel models.