 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-based xApp for Dynamic Resource Allocation in O-RAN Networks
Jan 15, 2024The disaggregated, distributed and virtualised implementation of radio access networks allows for dynamic resource allocation. These attributes can be realised by virtue of the Open Radio Access Networks (O-RAN) architecture. In this article, we tackle the issue of dynamic resource allocation using a data-driven approach by employing Machine Learning (ML). We present an xApp-based implementation for the proposed ML algorithm. The core aim of this work is to optimise resource allocation and fulfil Service Level Specifications (SLS). This is accomplished by dynamically adjusting the allocation of Physical Resource Blocks (PRBs) based on traffic demand and Quality of Service (QoS) requirements. The proposed ML model effectively selects the best allocation policy for each base station and enhances the performance of scheduler functionality in O-RAN - Distributed Unit (O-DU). We show that an xApp implementing the Random Forest Classifier can yield high (85\%) performance accuracy for optimal policy selection. This can be attained using the O-RAN instance state input parameters over a short training duration.
Decentralized Federated Learning on the Edge over Wireless Mesh Networks
Nov 02, 2023The rapid growth of Internet of Things (IoT) devices has generated vast amounts of data, leading to the emergence of federated learning as a novel distributed machine learning paradigm. Federated learning enables model training at the edge, leveraging the processing capacity of edge devices while preserving privacy and mitigating data transfer bottlenecks. However, the conventional centralized federated learning architecture suffers from a single point of failure and susceptibility to malicious attacks. In this study, we delve into an alternative approach called decentralized federated learning (DFL) conducted over a wireless mesh network as the communication backbone. We perform a comprehensive network performance analysis using stochastic geometry theory and physical interference models, offering fresh insights into the convergence analysis of DFL. Additionally, we conduct system simulations to assess the proposed decentralized architecture under various network parameters and different aggregator methods such as FedAvg, Krum and Median methods. Our model is trained on the widely recognized EMNIST dataset for benchmarking handwritten digit classification. To minimize the model's size at the edge and reduce communication overhead, we employ a cutting-edge compression technique based on genetic algorithms. Our simulation results reveal that the compressed decentralized architecture achieves performance comparable to the baseline centralized architecture and traditional DFL in terms of accuracy and average loss for our classification task. Moreover, it significantly reduces the size of shared models over the wireless channel by compressing participants' local model sizes to nearly half of their original size compared to the baselines, effectively reducing complexity and communication overhead.
Data-aided Active User Detection with False Alarm Correction in Grant-Free Transmission
Jul 26, 2022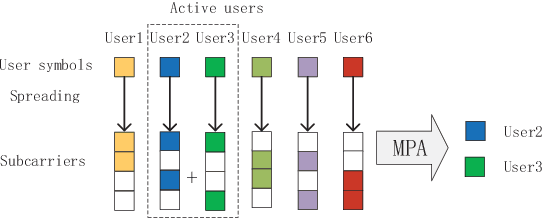
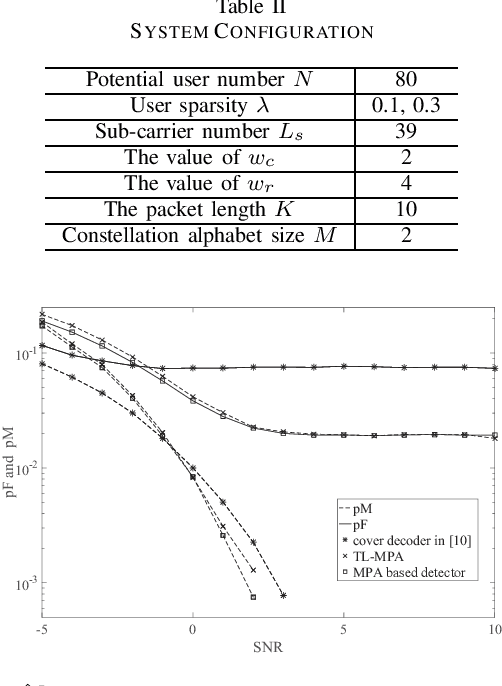
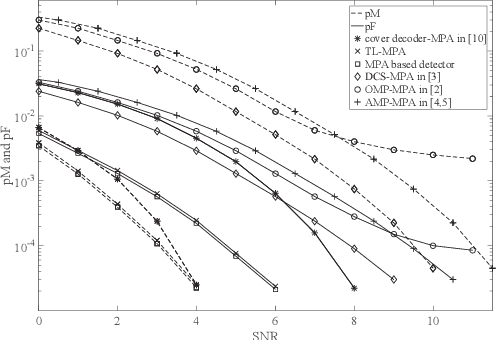
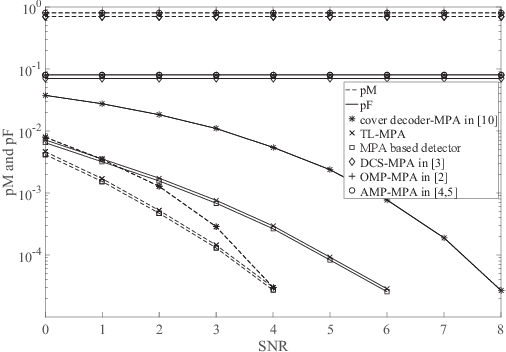
In most existing grant-free (GF) studies, the two key tasks, namely active user detection (AUD) and payload data decoding, are handled separately. In this paper, a two-step dataaided AUD scheme is proposed, namely the initial AUD step and the false alarm correction step respectively. To implement the initial AUD step, an embedded low-density-signature (LDS) based preamble pool is constructed. In addition, two message passing algorithm (MPA) based initial estimators are developed. In the false alarm correction step, a redundant factor graph is constructed based on the initial active user set, on which MPA is employed for data decoding. The remaining false detected inactive users will be further recognized by the false alarm corrector with the aid of decoded data symbols. Simulation results reveal that both the data decoding performance and the AUD performance are significantly enhanced by more than 1:5 dB at the target accuracy of 10^3 compared with the traditional compressed sensing (CS) based counterparts
Fine Timing and Frequency Synchronization for MIMO-OFDM: An Extreme Learning Approach
Jul 17, 2020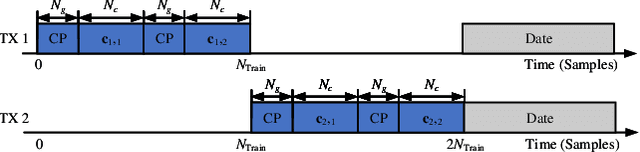
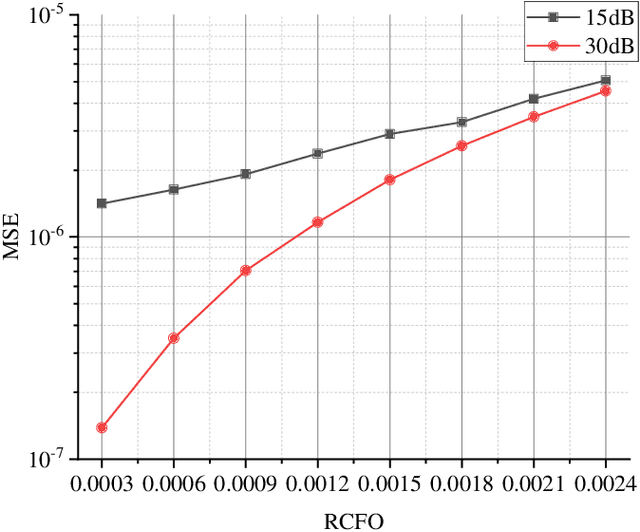
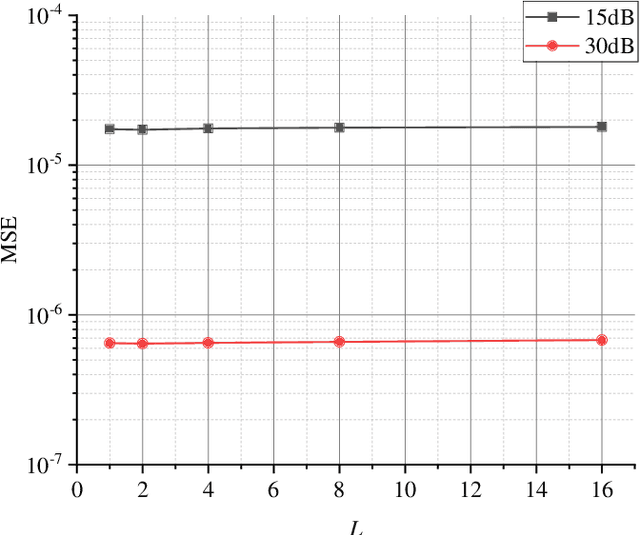
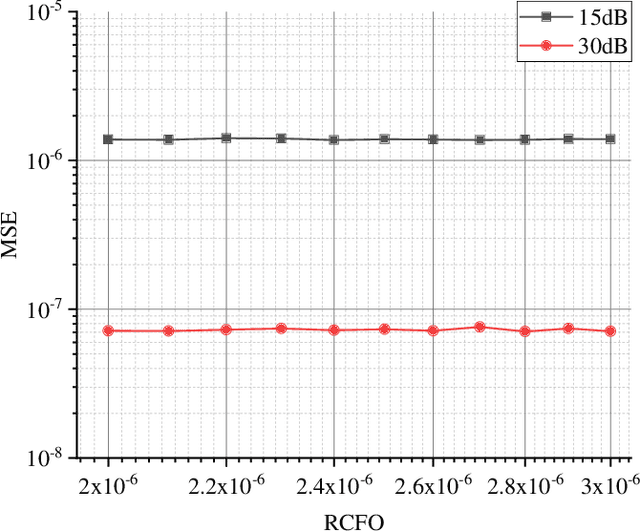
Multiple-input multiple-output orthogonal frequency-division multiplexing (MIMO-OFDM) is a key technology component in the evolution towards next-generation communication in which the accuracy of timing and frequency synchronization significantly impacts the overall system performance. In this paper, we propose a novel scheme leveraging extreme learning machine (ELM) to achieve high-precision timing and frequency synchronization. Specifically, two ELMs are incorporated into a traditional MIMO-OFDM system to estimate both the residual symbol timing offset (RSTO) and the residual carrier frequency offset (RCFO). The simulation results show that the performance of an ELM-based synchronization scheme is superior to the traditional method under both additive white Gaussian noise (AWGN) and frequency selective fading channels. Finally, the proposed method is robust in terms of choice of channel parameters (e.g., number of paths) and also in terms of "generalization ability" from a machine learning standpoint.
Robotic Mobility Diversity Algorithm with Continuous Search Space
May 21, 2018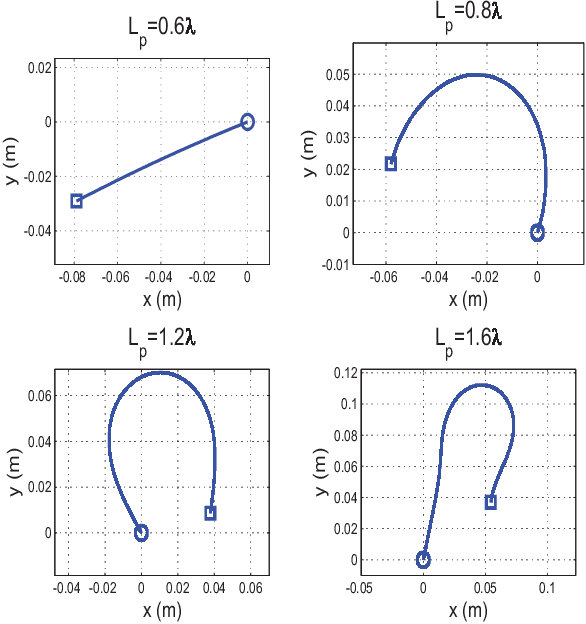
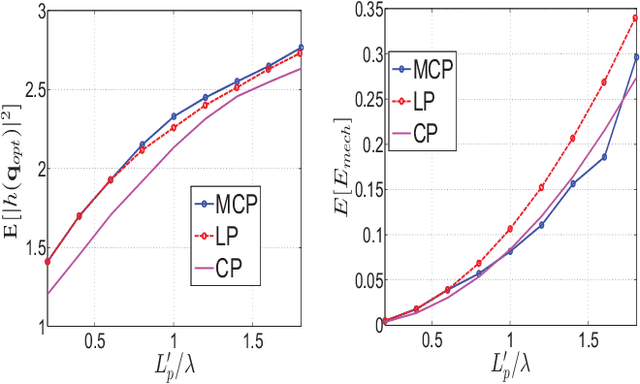
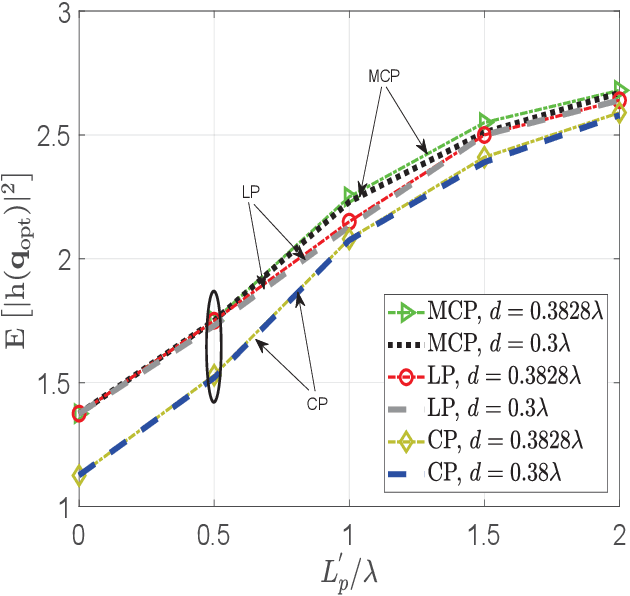
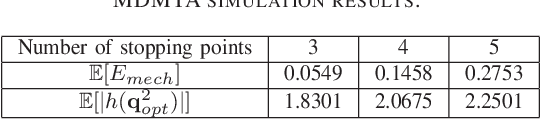
Small scale fading makes the wireless channel gain vary significantly over small distances and in the context of classical communication systems it can be detrimental to performance. But in the context of mobile robot (MR) wireless communications, we can take advantage of the fading using a mobility diversity algorithm (MDA) to deliberately locate the MR at a point where the channel gain is high. There are two classes of MDAs. In the first class, the MR explores various points, stops at each one to collect channel measurements and then locates the best position to establish communications. In the second class the MR moves, without stopping, along a continuous path while collecting channel measurements and then stops at the end of the path. It determines the best point to establish communications. Until now, the shape of the continuous path for such MDAs has been arbitrarily selected and currently there is no method to optimize it. In this paper, we propose a method to optimize such a path. Simulation results show that such optimized paths provide the MDAs with an increased performance, enabling them to experience higher channel gains while using less mechanical energy for the MR motion.