 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Qwen2VL: Compute-Efficient Pre-Training of Fully-Open Multimodal LLMs on Academic Resources
Apr 02, 2025The reproduction of state-of-the-art multimodal LLM pre-training faces barriers at every stage of the pipeline, including high-quality data filtering, multimodal data mixture strategies, sequence packing techniques, and training frameworks. We introduce Open-Qwen2VL, a fully open-source 2B-parameter Multimodal Large Language Model pre-trained efficiently on 29M image-text pairs using only 220 A100-40G GPU hours. Our approach employs low-to-high dynamic image resolution and multimodal sequence packing to significantly enhance pre-training efficiency. The training dataset was carefully curated using both MLLM-based filtering techniques (e.g., MLM-Filter) and conventional CLIP-based filtering methods, substantially improving data quality and training efficiency. The Open-Qwen2VL pre-training is conducted on academic level 8xA100-40G GPUs at UCSB on 5B packed multimodal tokens, which is 0.36% of 1.4T multimodal pre-training tokens of Qwen2-VL. The final instruction-tuned Open-Qwen2VL outperforms partially-open state-of-the-art MLLM Qwen2-VL-2B on various multimodal benchmarks of MMBench, SEEDBench, MMstar, and MathVista, indicating the remarkable training efficiency of Open-Qwen2VL. We open-source all aspects of our work, including compute-efficient and data-efficient training details, data filtering methods, sequence packing scripts, pre-training data in WebDataset format, FSDP-based training codebase, and both base and instruction-tuned model checkpoints. We redefine "fully open" for multimodal LLMs as the complete release of: 1) the training codebase, 2) detailed data filtering techniques, and 3) all pre-training and supervised fine-tuning data used to develop the model.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation
Feb 04, 2025This paper introduces the COCONut-PanCap dataset, created to enhance panoptic segmentation and grounded image captioning. Building upon the COCO dataset with advanced COCONut panoptic masks, this dataset aims to overcome limitations in existing image-text datasets that often lack detailed, scene-comprehensive descriptions. The COCONut-PanCap dataset incorporates fine-grained, region-level captions grounded in panoptic segmentation masks, ensuring consistency and improving the detail of generated captions. Through human-edited, densely annotated descriptions, COCONut-PanCap supports improved training of vision-language models (VLMs) for image understanding and generative models for text-to-image tasks. Experimental results demonstrate that COCONut-PanCap significantly boosts performance across understanding and generation tasks, offering complementary benefits to large-scale datasets. This dataset sets a new benchmark for evaluating models on joint panoptic segmentation and grounded captioning tasks, addressing the need for high-quality, detailed image-text annotations in multi-modal learning.
Dual Diffusion for Unified Image Generation and Understanding
Dec 31, 2024Diffusion models have gained tremendous success in text-to-image generation, yet still lag behind with visual understanding tasks, an area dominated by autoregressive vision-language models. We propose a large-scale and fully end-to-end diffusion model for multi-modal understanding and generation that significantly improves on existing diffusion-based multimodal models, and is the first of its kind to support the full suite of vision-language modeling capabilities. Inspired by the multimodal diffusion transformer (MM-DiT) and recent advances in discrete diffusion language modeling, we leverage a cross-modal maximum likelihood estimation framework that simultaneously trains the conditional likelihoods of both images and text jointly under a single loss function, which is back-propagated through both branches of the diffusion transformer. The resulting model is highly flexible and capable of a wide range of tasks including image generation, captioning, and visual question answering. Our model attained competitive performance compared to recent unified image understanding and generation models, demonstrating the potential of multimodal diffusion modeling as a promising alternative to autoregressive next-token prediction models.
Fast Prompt Alignment for Text-to-Image Generation
Dec 11, 2024
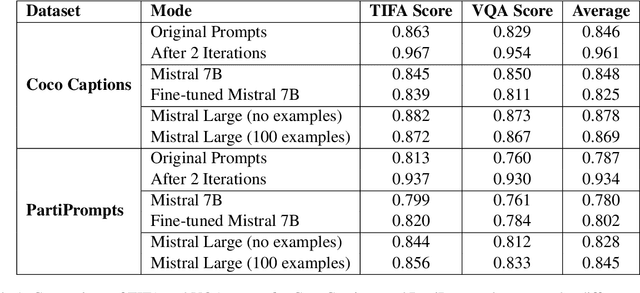
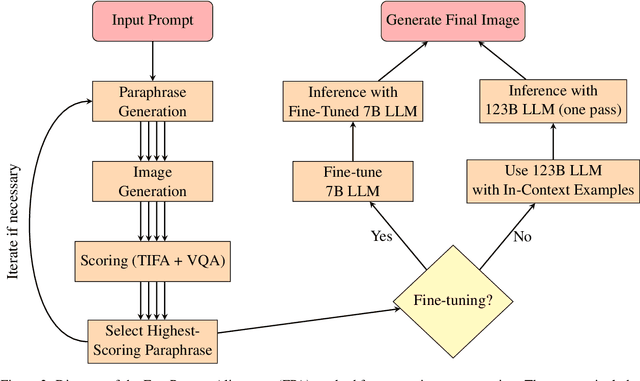
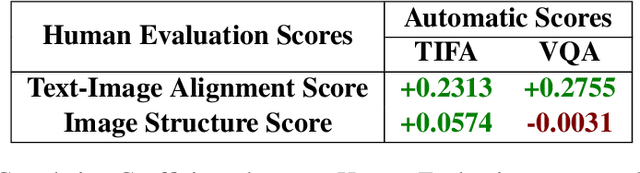
Text-to-image generation has advanced rapidly, yet aligning complex textual prompts with generated visuals remains challenging, especially with intricate object relationships and fine-grained details. This paper introduces Fast Prompt Alignment (FPA), a prompt optimization framework that leverages a one-pass approach, enhancing text-to-image alignment efficiency without the iterative overhead typical of current methods like OPT2I. FPA uses large language models (LLMs) for single-iteration prompt paraphrasing, followed by fine-tuning or in-context learning with optimized prompts to enable real-time inference, reducing computational demands while preserving alignment fidelity. Extensive evaluations on the COCO Captions and PartiPrompts datasets demonstrate that FPA achieves competitive text-image alignment scores at a fraction of the processing time, as validated through both automated metrics (TIFA, VQA) and human evaluation. A human study with expert annotators further reveals a strong correlation between human alignment judgments and automated scores, underscoring the robustness of FPA's improvements. The proposed method showcases a scalable, efficient alternative to iterative prompt optimization, enabling broader applicability in real-time, high-demand settings. The codebase is provided to facilitate further research: https://github.com/tiktok/fast_prompt_alignment
VMAS: Video-to-Music Generation via Semantic Alignment in Web Music Videos
Sep 11, 2024We present a framework for learning to generate background music from video inputs. Unlike existing works that rely on symbolic musical annotations, which are limited in quantity and diversity, our method leverages large-scale web videos accompanied by background music. This enables our model to learn to generate realistic and diverse music. To accomplish this goal, we develop a generative video-music Transformer with a novel semantic video-music alignment scheme. Our model uses a joint autoregressive and contrastive learning objective, which encourages the generation of music aligned with high-level video content. We also introduce a novel video-beat alignment scheme to match the generated music beats with the low-level motions in the video. Lastly, to capture fine-grained visual cues in a video needed for realistic background music generation, we introduce a new temporal video encoder architecture, allowing us to efficiently process videos consisting of many densely sampled frames. We train our framework on our newly curated DISCO-MV dataset, consisting of 2.2M video-music samples, which is orders of magnitude larger than any prior datasets used for video music generation. Our method outperforms existing approaches on the DISCO-MV and MusicCaps datasets according to various music generation evaluation metrics, including human evaluation. Results are available at https://genjib.github.io/project_page/VMAs/index.html
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
Autoregressive Pretraining with Mamba in Vision
Jun 11, 2024



The vision community has started to build with the recently developed state space model, Mamba, as the new backbone for a range of tasks. This paper shows that Mamba's visual capability can be significantly enhanced through autoregressive pretraining, a direction not previously explored. Efficiency-wise, the autoregressive nature can well capitalize on the Mamba's unidirectional recurrent structure, enabling faster overall training speed compared to other training strategies like mask modeling. Performance-wise, autoregressive pretraining equips the Mamba architecture with markedly higher accuracy over its supervised-trained counterparts and, more importantly, successfully unlocks its scaling potential to large and even huge model sizes. For example, with autoregressive pretraining, a base-size Mamba attains 83.2\% ImageNet accuracy, outperforming its supervised counterpart by 2.0\%; our huge-size Mamba, the largest Vision Mamba to date, attains 85.0\% ImageNet accuracy (85.5\% when finetuned with $384\times384$ inputs), notably surpassing all other Mamba variants in vision. The code is available at \url{https://github.com/OliverRensu/ARM}.
Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters
Mar 05, 2024



We propose a novel framework for filtering image-text data by leveraging fine-tuned Multimodal Language Models (MLMs). Our approach outperforms predominant filtering methods (e.g., CLIPScore) via integrating the recent advances in MLMs. We design four distinct yet complementary metrics to holistically measure the quality of image-text data. A new pipeline is established to construct high-quality instruction data for fine-tuning MLMs as data filters. Comparing with CLIPScore, our MLM filters produce more precise and comprehensive scores that directly improve the quality of filtered data and boost the performance of pre-trained models. We achieve significant improvements over CLIPScore on popular foundation models (i.e., CLIP and BLIP2) and various downstream tasks. Our MLM filter can generalize to different models and tasks, and be used as a drop-in replacement for CLIPScore. An additional ablation study is provided to verify our design choices for the MLM filter.
Video Recognition in Portrait Mode
Dec 21, 2023



The creation of new datasets often presents new challenges for video recognition and can inspire novel ideas while addressing these challenges. While existing datasets mainly comprise landscape mode videos, our paper seeks to introduce portrait mode videos to the research community and highlight the unique challenges associated with this video format. With the growing popularity of smartphones and social media applications, recognizing portrait mode videos is becoming increasingly important. To this end, we have developed the first dataset dedicated to portrait mode video recognition, namely PortraitMode-400. The taxonomy of PortraitMode-400 was constructed in a data-driven manner, comprising 400 fine-grained categories, and rigorous quality assurance was implemented to ensure the accuracy of human annotations. In addition to the new dataset, we conducted a comprehensive analysis of the impact of video format (portrait mode versus landscape mode) on recognition accuracy and spatial bias due to the different formats. Furthermore, we designed extensive experiments to explore key aspects of portrait mode video recognition, including the choice of data augmentation, evaluation procedure, the importance of temporal information, and the role of audio modality. Building on the insights from our experimental results and the introduction of PortraitMode-400, our paper aims to inspire further research efforts in this emerging research area.