 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing in 3D: Free-Viewpoint Fusion Rendering with a 3D Infrared-Visible Scene Representation
Jan 19, 2026Infrared-visible image fusion aims to integrate infrared and visible information into a single fused image. Existing 2D fusion methods focus on fusing images from fixed camera viewpoints, neglecting a comprehensive understanding of complex scenarios, which results in the loss of critical information about the scene. To address this limitation, we propose a novel Infrared-Visible Gaussian Fusion (IVGF) framework, which reconstructs scene geometry from multimodal 2D inputs and enables direct rendering of fused images. Specifically, we propose a cross-modal adjustment (CMA) module that modulates the opacity of Gaussians to solve the problem of cross-modal conflicts. Moreover, to preserve the distinctive features from both modalities, we introduce a fusion loss that guides the optimization of CMA, thus ensuring that the fused image retains the critical characteristics of each modality. Comprehensive qualitative and quantitative experiments demonstrate the effectiveness of the proposed method.
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
Discriminative Spatial-Semantic VOS Solution: 1st Place Solution for 6th LSVOS
Aug 29, 2024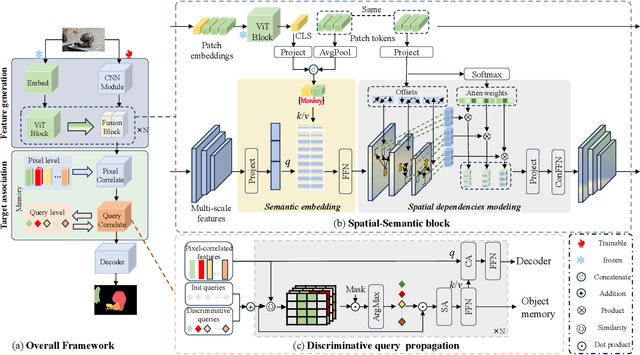
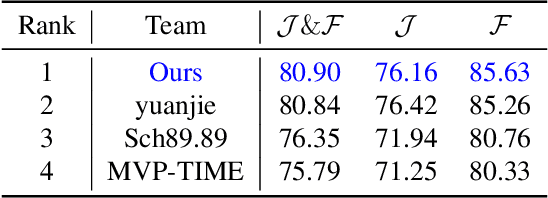

Video object segmentation (VOS) is a crucial task in computer vision, but current VOS methods struggle with complex scenes and prolonged object motions. To address these challenges, the MOSE dataset aims to enhance object recognition and differentiation in complex environments, while the LVOS dataset focuses on segmenting objects exhibiting long-term, intricate movements. This report introduces a discriminative spatial-temporal VOS model that utilizes discriminative object features as query representations. The semantic understanding of spatial-semantic modules enables it to recognize object parts, while salient features highlight more distinctive object characteristics. Our model, trained on extensive VOS datasets, achieved first place (\textbf{80.90\%} $\mathcal{J \& F}$) on the test set of the 6th LSVOS challenge in the VOS Track, demonstrating its effectiveness in tackling the aforementioned challenges. The code will be available at \href{https://github.com/yahooo-m/VOS-Solution}{code}.
Learning Spatial-Semantic Features for Robust Video Object Segmentation
Jul 10, 2024



Tracking and segmenting multiple similar objects with complex or separate parts in long-term videos is inherently challenging due to the ambiguity of target parts and identity confusion caused by occlusion, background clutter, and long-term variations. In this paper, we propose a robust video object segmentation framework equipped with spatial-semantic features and discriminative object queries to address the above issues. Specifically, we construct a spatial-semantic network comprising a semantic embedding block and spatial dependencies modeling block to associate the pretrained ViT features with global semantic features and local spatial features, providing a comprehensive target representation. In addition, we develop a masked cross-attention module to generate object queries that focus on the most discriminative parts of target objects during query propagation, alleviating noise accumulation and ensuring effective long-term query propagation. The experimental results show that the proposed method set a new state-of-the-art performance on multiple datasets, including the DAVIS2017 test (89.1%), YoutubeVOS 2019 (88.5%), MOSE (75.1%), LVOS test (73.0%), and LVOS val (75.1%), which demonstrate the effectiveness and generalization capacity of the proposed method. We will make all source code and trained models publicly available.
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.
1st Place Solution for MOSE Track in CVPR 2024 PVUW Workshop: Complex Video Object Segmentation
Jun 07, 2024

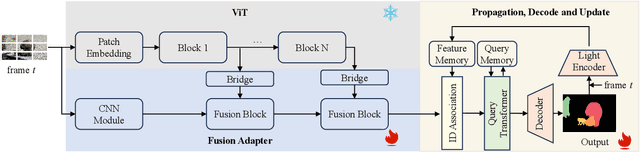
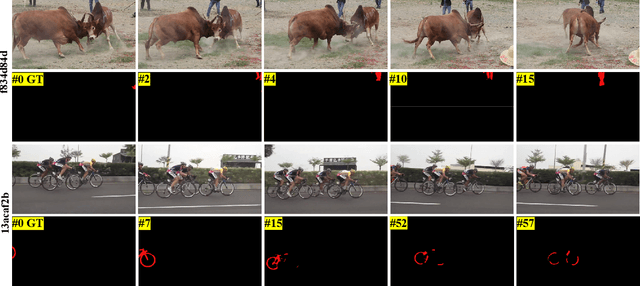
Tracking and segmenting multiple objects in complex scenes has always been a challenge in the field of video object segmentation, especially in scenarios where objects are occluded and split into parts. In such cases, the definition of objects becomes very ambiguous. The motivation behind the MOSE dataset is how to clearly recognize and distinguish objects in complex scenes. In this challenge, we propose a semantic embedding video object segmentation model and use the salient features of objects as query representations. The semantic understanding helps the model to recognize parts of the objects and the salient feature captures the more discriminative features of the objects. Trained on a large-scale video object segmentation dataset, our model achieves first place (\textbf{84.45\%}) in the test set of PVUW Challenge 2024: Complex Video Object Segmentation Track.
Spatial-Temporal Multi-level Association for Video Object Segmentation
Apr 09, 2024Existing semi-supervised video object segmentation methods either focus on temporal feature matching or spatial-temporal feature modeling. However, they do not address the issues of sufficient target interaction and efficient parallel processing simultaneously, thereby constraining the learning of dynamic, target-aware features. To tackle these limitations, this paper proposes a spatial-temporal multi-level association framework, which jointly associates reference frame, test frame, and object features to achieve sufficient interaction and parallel target ID association with a spatial-temporal memory bank for efficient video object segmentation. Specifically, we construct a spatial-temporal multi-level feature association module to learn better target-aware features, which formulates feature extraction and interaction as the efficient operations of object self-attention, reference object enhancement, and test reference correlation. In addition, we propose a spatial-temporal memory to assist feature association and temporal ID assignment and correlation. We evaluate the proposed method by conducting extensive experiments on numerous video object segmentation datasets, including DAVIS 2016/2017 val, DAVIS 2017 test-dev, and YouTube-VOS 2018/2019 val. The favorable performance against the state-of-the-art methods demonstrates the effectiveness of our approach. All source code and trained models will be made publicly available.
Simple Contrastive Representation Adversarial Learning for NLP Tasks
Dec 02, 2021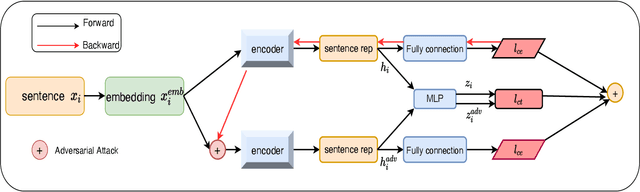
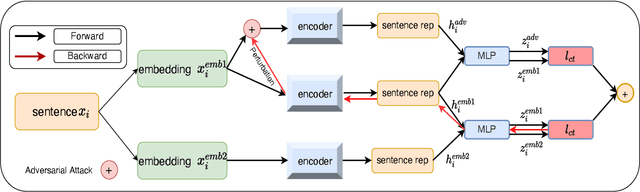

Self-supervised learning approach like contrastive learning is attached great attention in natural language processing. It uses pairs of training data augmentations to build a classification task for an encoder with well representation ability. However, the construction of learning pairs over contrastive learning is much harder in NLP tasks. Previous works generate word-level changes to form pairs, but small transforms may cause notable changes on the meaning of sentences as the discrete and sparse nature of natural language. In this paper, adversarial training is performed to generate challenging and harder learning adversarial examples over the embedding space of NLP as learning pairs. Using contrastive learning improves the generalization ability of adversarial training because contrastive loss can uniform the sample distribution. And at the same time, adversarial training also enhances the robustness of contrastive learning. Two novel frameworks, supervised contrastive adversarial learning (SCAL) and unsupervised SCAL (USCAL), are proposed, which yields learning pairs by utilizing the adversarial training for contrastive learning. The label-based loss of supervised tasks is exploited to generate adversarial examples while unsupervised tasks bring contrastive loss. To validate the effectiveness of the proposed framework, we employ it to Transformer-based models for natural language understanding, sentence semantic textual similarity and adversarial learning tasks. Experimental results on GLUE benchmark tasks show that our fine-tuned supervised method outperforms BERT$_{base}$ over 1.75\%. We also evaluate our unsupervised method on semantic textual similarity (STS) tasks, and our method gets 77.29\% with BERT$_{base}$. The robustness of our approach conducts state-of-the-art results under multiple adversarial datasets on NLI tasks.