 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Spatial-Semantic VOS Solution: 1st Place Solution for 6th LSVOS
Paper and Code
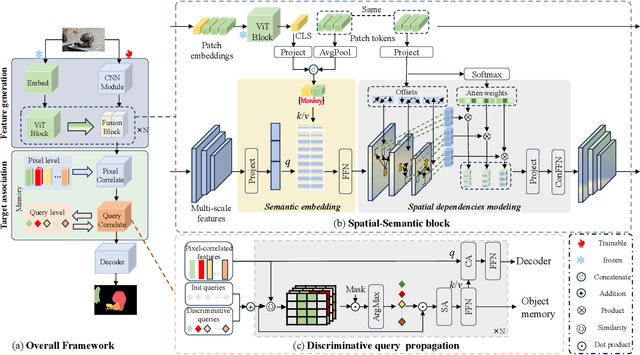
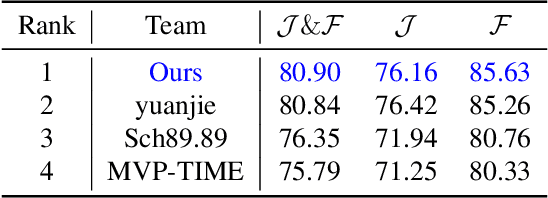

Video object segmentation (VOS) is a crucial task in computer vision, but current VOS methods struggle with complex scenes and prolonged object motions. To address these challenges, the MOSE dataset aims to enhance object recognition and differentiation in complex environments, while the LVOS dataset focuses on segmenting objects exhibiting long-term, intricate movements. This report introduces a discriminative spatial-temporal VOS model that utilizes discriminative object features as query representations. The semantic understanding of spatial-semantic modules enables it to recognize object parts, while salient features highlight more distinctive object characteristics. Our model, trained on extensive VOS datasets, achieved first place (\textbf{80.90\%} $\mathcal{J \& F}$) on the test set of the 6th LSVOS challenge in the VOS Track, demonstrating its effectiveness in tackling the aforementioned challenges. The code will be available at \href{https://github.com/yahooo-m/VOS-Solution}{code}.