 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing in 3D: Free-Viewpoint Fusion Rendering with a 3D Infrared-Visible Scene Representation
Jan 19, 2026Infrared-visible image fusion aims to integrate infrared and visible information into a single fused image. Existing 2D fusion methods focus on fusing images from fixed camera viewpoints, neglecting a comprehensive understanding of complex scenarios, which results in the loss of critical information about the scene. To address this limitation, we propose a novel Infrared-Visible Gaussian Fusion (IVGF) framework, which reconstructs scene geometry from multimodal 2D inputs and enables direct rendering of fused images. Specifically, we propose a cross-modal adjustment (CMA) module that modulates the opacity of Gaussians to solve the problem of cross-modal conflicts. Moreover, to preserve the distinctive features from both modalities, we introduce a fusion loss that guides the optimization of CMA, thus ensuring that the fused image retains the critical characteristics of each modality. Comprehensive qualitative and quantitative experiments demonstrate the effectiveness of the proposed method.
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
Discriminative Spatial-Semantic VOS Solution: 1st Place Solution for 6th LSVOS
Aug 29, 2024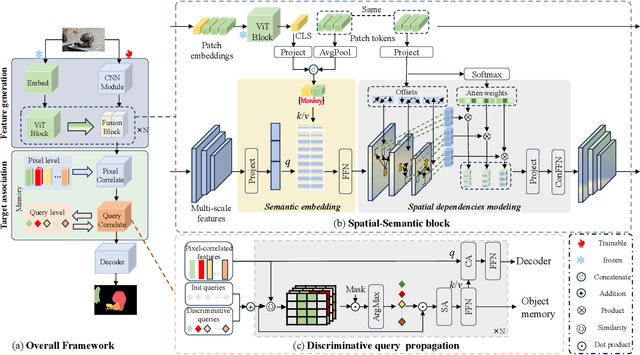
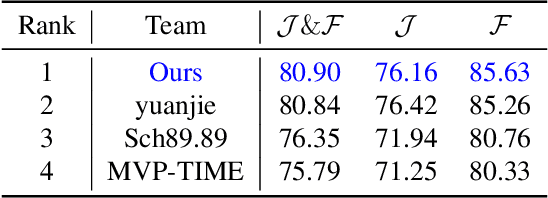

Video object segmentation (VOS) is a crucial task in computer vision, but current VOS methods struggle with complex scenes and prolonged object motions. To address these challenges, the MOSE dataset aims to enhance object recognition and differentiation in complex environments, while the LVOS dataset focuses on segmenting objects exhibiting long-term, intricate movements. This report introduces a discriminative spatial-temporal VOS model that utilizes discriminative object features as query representations. The semantic understanding of spatial-semantic modules enables it to recognize object parts, while salient features highlight more distinctive object characteristics. Our model, trained on extensive VOS datasets, achieved first place (\textbf{80.90\%} $\mathcal{J \& F}$) on the test set of the 6th LSVOS challenge in the VOS Track, demonstrating its effectiveness in tackling the aforementioned challenges. The code will be available at \href{https://github.com/yahooo-m/VOS-Solution}{code}.