 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCartesian-nj: Extending e3nn to Irreducible Cartesian Tensor Product and Contracion
Dec 18, 2025
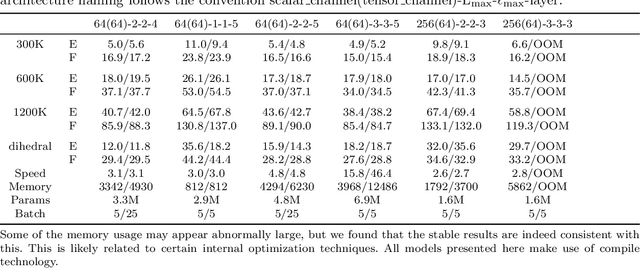
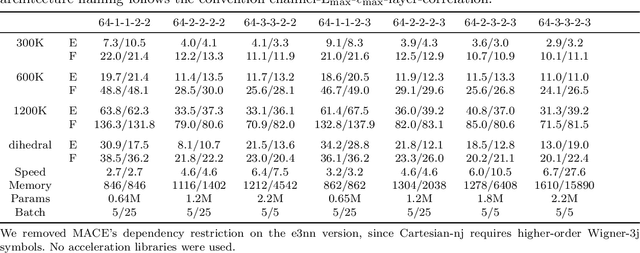
Equivariant atomistic machine learning models have brought substantial gains in both extrapolation capability and predictive accuracy. Depending on the basis of the space, two distinct types of irreducible representations are utilized. From architectures built upon spherical tensors (STs) to more recent formulations employing irreducible Cartesian tensors (ICTs), STs have remained dominant owing to their compactness, elegance, and theoretical completeness. Nevertheless, questions have persisted regarding whether ST constructions are the only viable design principle, motivating continued development of Cartesian networks. In this work, we introduce the Cartesian-3j and Cartesian-nj symbol, which serve as direct analogues of the Wigner-3j and Wigner-nj symbol defined for tensor coupling. These coefficients enable the combination of any two ICTs into a new ICT. Building on this foundation, we extend e3nn to support irreducible Cartesian tensor product, and we release the resulting Python package as cartnn. Within this framework, we implement Cartesian counterparts of MACE, NequIP, and Allegro, allowing the first systematic comparison of Cartesian and spherical models to assess whether Cartesian formulations may offer advantages under specific conditions. Using TACE as a representative example, we further examine whether architectures constructed from irreducible Cartesian tensor product and contraction(ICTP and ICTC) are conceptually well-founded in Cartesian space and whether opportunities remain for improving their design.
Towards universal property prediction in Cartesian space: TACE is all you need
Sep 18, 2025Machine learning has revolutionized atomistic simulations and materials science, yet current approaches often depend on spherical-harmonic representations. Here we introduce the Tensor Atomic Cluster Expansion and Tensor Moment Potential, the first unified framework formulated entirely in Cartesian space for the systematic prediction of arbitrary structure-determined tensorial properties. TACE achieves this by decomposing atomic environments into a complete hierarchy of (irreducible) Cartesian tensors, ensuring symmetry-consistent representations that naturally encode invariance and equivariance constraints. Beyond geometry, TACE incorporates universal embeddings that flexibly integrate diverse attributes including basis sets, charges, magnetic moments and field perturbations. This allows explicit control over external invariants and equivariants in the prediction process. Long-range interactions are also accurately described through the Latent Ewald Summation module within the short-range approximation, providing a rigorous yet computationally efficient treatment of electrostatic interactions. We demonstrate that TACE attains accuracy, stability, and efficiency on par with or surpassing leading equivariant frameworks across finite molecules and extended materials, including in-domain and out-of-domain benchmarks, spectra, hessians, external-field response, charged systems, magnetic systems, multi-fidelity training, and heterogeneous catalytic systems. Crucially, TACE bridges scalar and tensorial modeling and establishes a Cartesian-space paradigm that unifies and extends beyond the design space of spherical-harmonic-based methods. This work lays the foundation for a new generation of universal atomistic machine learning models capable of systematically capturing the rich interplay of geometry, fields and material properties within a single coherent framework.
Break the Chain: Large Language Models Can be Shortcut Reasoners
Jun 04, 2024

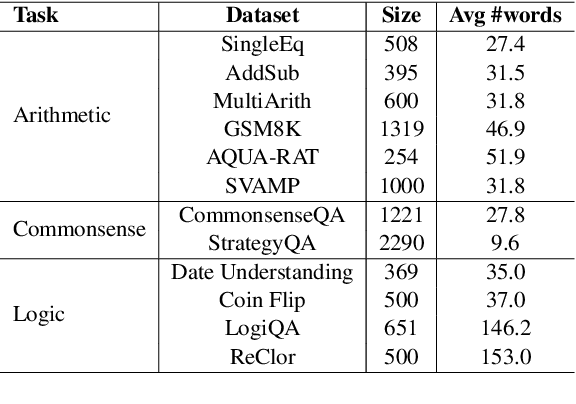
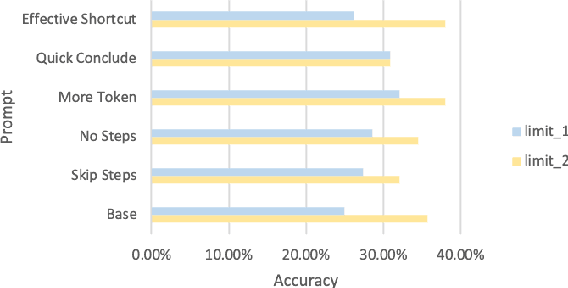
Recent advancements in Chain-of-Thought (CoT) reasoning utilize complex modules but are hampered by high token consumption, limited applicability, and challenges in reproducibility. This paper conducts a critical evaluation of CoT prompting, extending beyond arithmetic to include complex logical and commonsense reasoning tasks, areas where standard CoT methods fall short. We propose the integration of human-like heuristics and shortcuts into language models (LMs) through "break the chain" strategies. These strategies disrupt traditional CoT processes using controlled variables to assess their efficacy. Additionally, we develop innovative zero-shot prompting strategies that encourage the use of shortcuts, enabling LMs to quickly exploit reasoning clues and bypass detailed procedural steps. Our comprehensive experiments across various LMs, both commercial and open-source, reveal that LMs maintain effective performance with "break the chain" strategies. We also introduce ShortcutQA, a dataset specifically designed to evaluate reasoning through shortcuts, compiled from competitive tests optimized for heuristic reasoning tasks such as forward/backward reasoning and simplification. Our analysis confirms that ShortcutQA not only poses a robust challenge to LMs but also serves as an essential benchmark for enhancing reasoning efficiency in AI.
Quantum Shadow Gradient Descent for Quantum Learning
Oct 10, 2023This paper proposes a new procedure called quantum shadow gradient descent (QSGD) that addresses these key challenges. Our method has the benefits of a one-shot approach, in not requiring any sample duplication while having a convergence rate comparable to the ideal update rule using exact gradient computation. We propose a new technique for generating quantum shadow samples (QSS), which generates quantum shadows as opposed to classical shadows used in existing works. With classical shadows, the computations are typically performed on classical computers and, hence, are prohibitive since the dimension grows exponentially. Our approach resolves this issue by measurements of quantum shadows. As the second main contribution, we study more general non-product ansatz of the form $\exp\{i\sum_j \theta_j A_j\}$ that model variational Hamiltonians. We prove that the gradient can be written in terms of the gradient of single-parameter ansatzes that can be easily measured. Our proof is based on the Suzuki-Trotter approximation; however, our expressions are exact, unlike prior efforts that approximate non-product operators. As a result, existing gradient measurement techniques can be applied to more general VQAs followed by correction terms without any approximation penalty. We provide theoretical proofs, convergence analysis and verify our results through numerical experiments.
Simple Contrastive Representation Adversarial Learning for NLP Tasks
Dec 02, 2021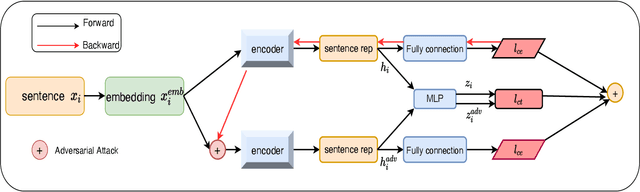
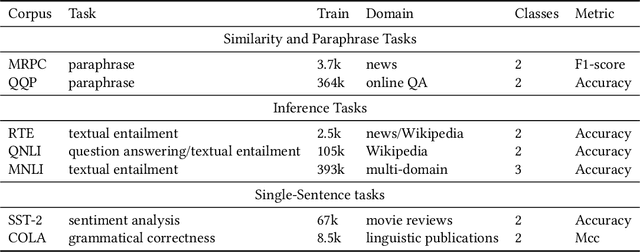
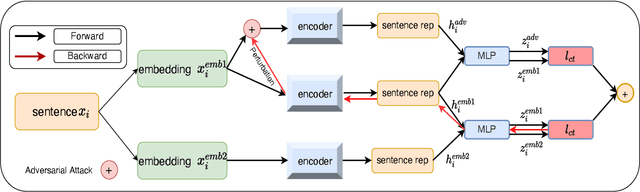

Self-supervised learning approach like contrastive learning is attached great attention in natural language processing. It uses pairs of training data augmentations to build a classification task for an encoder with well representation ability. However, the construction of learning pairs over contrastive learning is much harder in NLP tasks. Previous works generate word-level changes to form pairs, but small transforms may cause notable changes on the meaning of sentences as the discrete and sparse nature of natural language. In this paper, adversarial training is performed to generate challenging and harder learning adversarial examples over the embedding space of NLP as learning pairs. Using contrastive learning improves the generalization ability of adversarial training because contrastive loss can uniform the sample distribution. And at the same time, adversarial training also enhances the robustness of contrastive learning. Two novel frameworks, supervised contrastive adversarial learning (SCAL) and unsupervised SCAL (USCAL), are proposed, which yields learning pairs by utilizing the adversarial training for contrastive learning. The label-based loss of supervised tasks is exploited to generate adversarial examples while unsupervised tasks bring contrastive loss. To validate the effectiveness of the proposed framework, we employ it to Transformer-based models for natural language understanding, sentence semantic textual similarity and adversarial learning tasks. Experimental results on GLUE benchmark tasks show that our fine-tuned supervised method outperforms BERT$_{base}$ over 1.75\%. We also evaluate our unsupervised method on semantic textual similarity (STS) tasks, and our method gets 77.29\% with BERT$_{base}$. The robustness of our approach conducts state-of-the-art results under multiple adversarial datasets on NLI tasks.