 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Feedback-based Algorithms for Quantum Optimization Using Gradient Descent
Feb 12, 2026Feedback-based methods have gained significant attention as an alternative training paradigm for the Quantum Approximate Optimization Algorithm (QAOA) in solving combinatorial optimization problems such as MAX-CUT. In particular, Quantum Lyapunov Control (QLC) employs feedback-driven control laws that guarantee monotonic non-decreasing objective values, can substantially reduce the training overhead of QAOA, and mitigate barren plateaus. However, these methods might require long control sequences, leading to sub-optimal convergence rates. In this work, we propose a hybrid method that incorporates per-layer gradient estimation to accelerate the convergence of QLC while preserving its low training overhead and stability guarantees. By leveraging layer-wise gradient information, the proposed approach selects near-optimal control parameters, resulting in significantly faster convergence and improved robustness. We validate the effectiveness of the method through extensive numerical experiments across a range of problem instances and optimization settings.
New Bounds on Quantum Sample Complexity of Measurement Classes
Aug 22, 2024
This paper studies quantum supervised learning for classical inference from quantum states. In this model, a learner has access to a set of labeled quantum samples as the training set. The objective is to find a quantum measurement that predicts the label of the unseen samples. The hardness of learning is measured via sample complexity under a quantum counterpart of the well-known probably approximately correct (PAC). Quantum sample complexity is expected to be higher than classical one, because of the measurement incompatibility and state collapse. Recent efforts showed that the sample complexity of learning a finite quantum concept class $\mathcal{C}$ scales as $O(|\mathcal{C}|)$. This is significantly higher than the classical sample complexity that grows logarithmically with the class size. This work improves the sample complexity bound to $O(V_{\mathcal{C}^*} \log |\mathcal{C}^*|)$, where $\mathcal{C}^*$ is the set of extreme points of the convex closure of $\mathcal{C}$ and $V_{\mathcal{C}^*}$ is the shadow-norm of this set. We show the tightness of our bound for the class of bounded Hilbert-Schmidt norm, scaling as $O(\log |\mathcal{C}^*|)$. Our approach is based on a new quantum empirical risk minimization (ERM) algorithm equipped with a shadow tomography method.
Efficient Gradient Estimation of Variational Quantum Circuits with Lie Algebraic Symmetries
Apr 07, 2024


Hybrid quantum-classical optimization and learning strategies are among the most promising approaches to harnessing quantum information or gaining a quantum advantage over classical methods. However, efficient estimation of the gradient of the objective function in such models remains a challenge due to several factors including the exponential dimensionality of the Hilbert spaces, and information loss of quantum measurements. In this work, we study generic parameterized circuits in the context of variational methods. We develop a framework for gradient estimation that exploits the algebraic symmetries of Hamiltonian characterized through Lie algebra or group theory. Particularly, we prove that when the dimension of the dynamical Lie algebra is polynomial in the number of qubits, one can estimate the gradient with polynomial classical and quantum resources. This is done by a series of Hadamard tests applied to the output of the ansatz with no change to its circuit. We show that this approach can be equipped with classical shadow tomography to further reduce the measurement shot complexity to scale logarithmically with the number of parameters.
Quantum Shadow Gradient Descent for Quantum Learning
Oct 10, 2023This paper proposes a new procedure called quantum shadow gradient descent (QSGD) that addresses these key challenges. Our method has the benefits of a one-shot approach, in not requiring any sample duplication while having a convergence rate comparable to the ideal update rule using exact gradient computation. We propose a new technique for generating quantum shadow samples (QSS), which generates quantum shadows as opposed to classical shadows used in existing works. With classical shadows, the computations are typically performed on classical computers and, hence, are prohibitive since the dimension grows exponentially. Our approach resolves this issue by measurements of quantum shadows. As the second main contribution, we study more general non-product ansatz of the form $\exp\{i\sum_j \theta_j A_j\}$ that model variational Hamiltonians. We prove that the gradient can be written in terms of the gradient of single-parameter ansatzes that can be easily measured. Our proof is based on the Suzuki-Trotter approximation; however, our expressions are exact, unlike prior efforts that approximate non-product operators. As a result, existing gradient measurement techniques can be applied to more general VQAs followed by correction terms without any approximation penalty. We provide theoretical proofs, convergence analysis and verify our results through numerical experiments.
Agnostic PAC Learning of k-juntas Using L2-Polynomial Regression
Mar 08, 2023
Many conventional learning algorithms rely on loss functions other than the natural 0-1 loss for computational efficiency and theoretical tractability. Among them are approaches based on absolute loss (L1 regression) and square loss (L2 regression). The first is proved to be an \textit{agnostic} PAC learner for various important concept classes such as \textit{juntas}, and \textit{half-spaces}. On the other hand, the second is preferable because of its computational efficiency, which is linear in the sample size. However, PAC learnability is still unknown as guarantees have been proved only under distributional restrictions. The question of whether L2 regression is an agnostic PAC learner for 0-1 loss has been open since 1993 and yet has to be answered. This paper resolves this problem for the junta class on the Boolean cube -- proving agnostic PAC learning of k-juntas using L2 polynomial regression. Moreover, we present a new PAC learning algorithm based on the Boolean Fourier expansion with lower computational complexity. Fourier-based algorithms, such as Linial et al. (1993), have been used under distributional restrictions, such as uniform distribution. We show that with an appropriate change, one can apply those algorithms in agnostic settings without any distributional assumption. We prove our results by connecting the PAC learning with 0-1 loss to the minimum mean square estimation (MMSE) problem. We derive an elegant upper bound on the 0-1 loss in terms of the MMSE error and show that the sign of the MMSE is a PAC learner for any concept class containing it.
Expected Worst Case Regret via Stochastic Sequential Covering
Sep 17, 2022
We study the problem of sequential prediction and online minimax regret with stochastically generated features under a general loss function. We introduce a notion of expected worst case minimax regret that generalizes and encompasses prior known minimax regrets. For such minimax regrets we establish tight upper bounds via a novel concept of stochastic global sequential covering. We show that for a hypothesis class of VC-dimension $\mathsf{VC}$ and $i.i.d.$ generated features of length $T$, the cardinality of the stochastic global sequential covering can be upper bounded with high probability (whp) by $e^{O(\mathsf{VC} \cdot \log^2 T)}$. We then improve this bound by introducing a new complexity measure called the Star-Littlestone dimension, and show that classes with Star-Littlestone dimension $\mathsf{SL}$ admit a stochastic global sequential covering of order $e^{O(\mathsf{SL} \cdot \log T)}$. We further establish upper bounds for real valued classes with finite fat-shattering numbers. Finally, by applying information-theoretic tools of the fixed design minimax regrets, we provide lower bounds for the expected worst case minimax regret. We demonstrate the effectiveness of our approach by establishing tight bounds on the expected worst case minimax regrets for logarithmic loss and general mixable losses.
Precise Regret Bounds for Log-loss via a Truncated Bayesian Algorithm
May 07, 2022
We study the sequential general online regression, known also as the sequential probability assignments, under logarithmic loss when compared against a broad class of experts. We focus on obtaining tight, often matching, lower and upper bounds for the sequential minimax regret that are defined as the excess loss it incurs over a class of experts. After proving a general upper bound, we consider some specific classes of experts from Lipschitz class to bounded Hessian class and derive matching lower and upper bounds with provably optimal constants. Our bounds work for a wide range of values of the data dimension and the number of rounds. To derive lower bounds, we use tools from information theory (e.g., Shtarkov sum) and for upper bounds, we resort to new "smooth truncated covering" of the class of experts. This allows us to find constructive proofs by applying a simple and novel truncated Bayesian algorithm. Our proofs are substantially simpler than the existing ones and yet provide tighter (and often optimal) bounds.
Toward Physically Realizable Quantum Neural Networks
Mar 22, 2022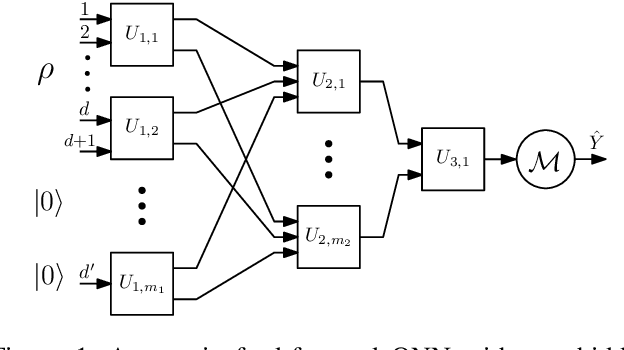

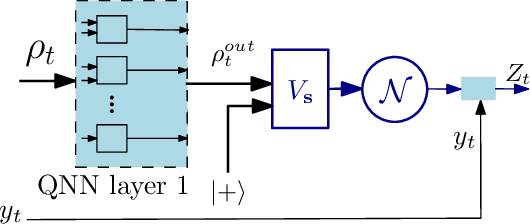

There has been significant recent interest in quantum neural networks (QNNs), along with their applications in diverse domains. Current solutions for QNNs pose significant challenges concerning their scalability, ensuring that the postulates of quantum mechanics are satisfied and that the networks are physically realizable. The exponential state space of QNNs poses challenges for the scalability of training procedures. The no-cloning principle prohibits making multiple copies of training samples, and the measurement postulates lead to non-deterministic loss functions. Consequently, the physical realizability and efficiency of existing approaches that rely on repeated measurement of several copies of each sample for training QNNs are unclear. This paper presents a new model for QNNs that relies on band-limited Fourier expansions of transfer functions of quantum perceptrons (QPs) to design scalable training procedures. This training procedure is augmented with a randomized quantum stochastic gradient descent technique that eliminates the need for sample replication. We show that this training procedure converges to the true minima in expectation, even in the presence of non-determinism due to quantum measurement. Our solution has a number of important benefits: (i) using QPs with concentrated Fourier power spectrum, we show that the training procedure for QNNs can be made scalable; (ii) it eliminates the need for resampling, thus staying consistent with the no-cloning rule; and (iii) enhanced data efficiency for the overall training process since each data sample is processed once per epoch. We present a detailed theoretical foundation for our models and methods' scalability, accuracy, and data efficiency. We also validate the utility of our approach through a series of numerical experiments.
On Agnostic PAC Learning using $\mathcal{L}_2$-polynomial Regression and Fourier-based Algorithms
Feb 11, 2021We develop a framework using Hilbert spaces as a proxy to analyze PAC learning problems with structural properties. We consider a joint Hilbert space incorporating the relation between the true label and the predictor under a joint distribution $D$. We demonstrate that agnostic PAC learning with 0-1 loss is equivalent to an optimization in the Hilbert space domain. With our model, we revisit the PAC learning problem using methods based on least-squares such as $\mathcal{L}_2$ polynomial regression and Linial's low-degree algorithm. We study learning with respect to several hypothesis classes such as half-spaces and polynomial-approximated classes (i.e., functions approximated by a fixed-degree polynomial). We prove that (under some distributional assumptions) such methods obtain generalization error up to $2opt$ with $opt$ being the optimal error of the class. Hence, we show the tightest bound on generalization error when $opt\leq 0.2$.