 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreak the Chain: Large Language Models Can be Shortcut Reasoners
Paper and Code
Jun 04, 2024

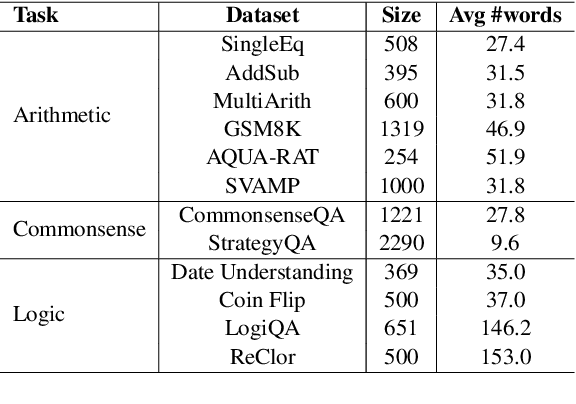
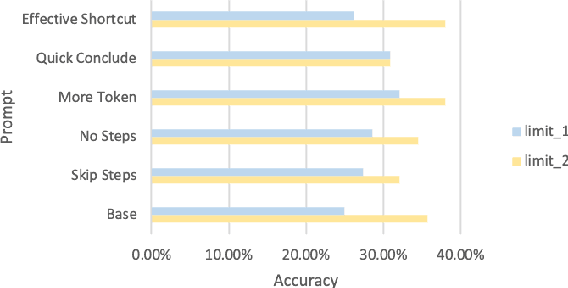
Recent advancements in Chain-of-Thought (CoT) reasoning utilize complex modules but are hampered by high token consumption, limited applicability, and challenges in reproducibility. This paper conducts a critical evaluation of CoT prompting, extending beyond arithmetic to include complex logical and commonsense reasoning tasks, areas where standard CoT methods fall short. We propose the integration of human-like heuristics and shortcuts into language models (LMs) through "break the chain" strategies. These strategies disrupt traditional CoT processes using controlled variables to assess their efficacy. Additionally, we develop innovative zero-shot prompting strategies that encourage the use of shortcuts, enabling LMs to quickly exploit reasoning clues and bypass detailed procedural steps. Our comprehensive experiments across various LMs, both commercial and open-source, reveal that LMs maintain effective performance with "break the chain" strategies. We also introduce ShortcutQA, a dataset specifically designed to evaluate reasoning through shortcuts, compiled from competitive tests optimized for heuristic reasoning tasks such as forward/backward reasoning and simplification. Our analysis confirms that ShortcutQA not only poses a robust challenge to LMs but also serves as an essential benchmark for enhancing reasoning efficiency in AI.