 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1st Place Solution for MOSE Track in CVPR 2024 PVUW Workshop: Complex Video Object Segmentation
Paper and Code
Jun 07, 2024

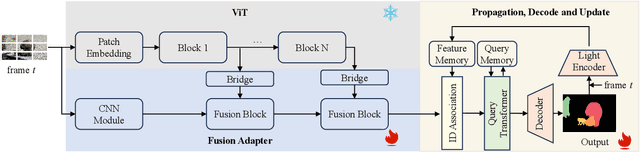
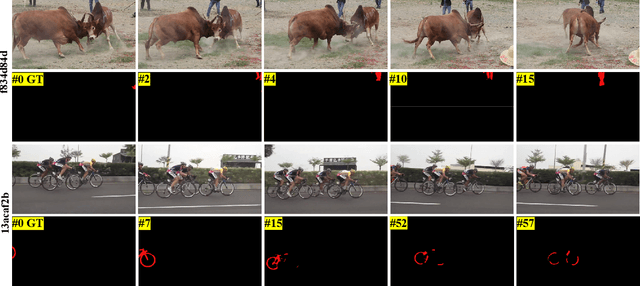
Tracking and segmenting multiple objects in complex scenes has always been a challenge in the field of video object segmentation, especially in scenarios where objects are occluded and split into parts. In such cases, the definition of objects becomes very ambiguous. The motivation behind the MOSE dataset is how to clearly recognize and distinguish objects in complex scenes. In this challenge, we propose a semantic embedding video object segmentation model and use the salient features of objects as query representations. The semantic understanding helps the model to recognize parts of the objects and the salient feature captures the more discriminative features of the objects. Trained on a large-scale video object segmentation dataset, our model achieves first place (\textbf{84.45\%}) in the test set of PVUW Challenge 2024: Complex Video Object Segmentation Track.