 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching in Space and Time: Unified Memory-Action Loops for Open-World Object Retrieval
Nov 19, 2025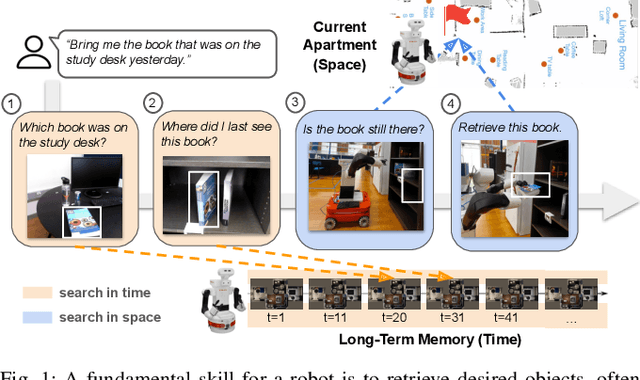
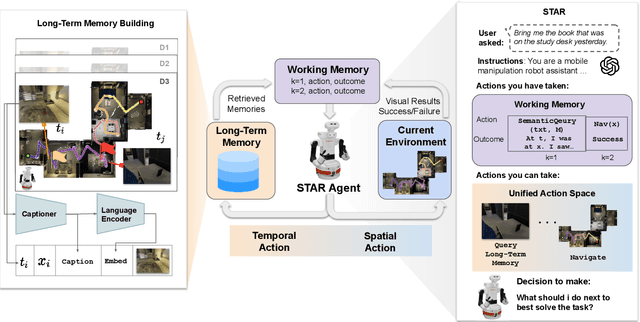

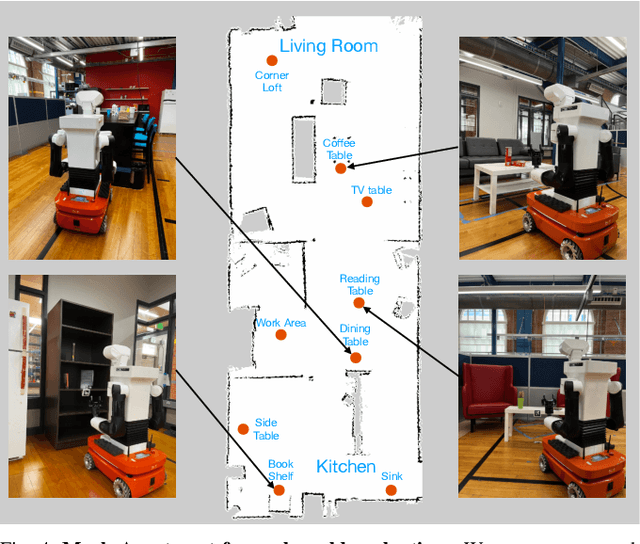
Service robots must retrieve objects in dynamic, open-world settings where requests may reference attributes ("the red mug"), spatial context ("the mug on the table"), or past states ("the mug that was here yesterday"). Existing approaches capture only parts of this problem: scene graphs capture spatial relations but ignore temporal grounding, temporal reasoning methods model dynamics but do not support embodied interaction, and dynamic scene graphs handle both but remain closed-world with fixed vocabularies. We present STAR (SpatioTemporal Active Retrieval), a framework that unifies memory queries and embodied actions within a single decision loop. STAR leverages non-parametric long-term memory and a working memory to support efficient recall, and uses a vision-language model to select either temporal or spatial actions at each step. We introduce STARBench, a benchmark of spatiotemporal object search tasks across simulated and real environments. Experiments in STARBench and on a Tiago robot show that STAR consistently outperforms scene-graph and memory-only baselines, demonstrating the benefits of treating search in time and search in space as a unified problem.
Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters
Mar 05, 2024



We propose a novel framework for filtering image-text data by leveraging fine-tuned Multimodal Language Models (MLMs). Our approach outperforms predominant filtering methods (e.g., CLIPScore) via integrating the recent advances in MLMs. We design four distinct yet complementary metrics to holistically measure the quality of image-text data. A new pipeline is established to construct high-quality instruction data for fine-tuning MLMs as data filters. Comparing with CLIPScore, our MLM filters produce more precise and comprehensive scores that directly improve the quality of filtered data and boost the performance of pre-trained models. We achieve significant improvements over CLIPScore on popular foundation models (i.e., CLIP and BLIP2) and various downstream tasks. Our MLM filter can generalize to different models and tasks, and be used as a drop-in replacement for CLIPScore. An additional ablation study is provided to verify our design choices for the MLM filter.
The Devil is in the Details: A Deep Dive into the Rabbit Hole of Data Filtering
Sep 27, 2023

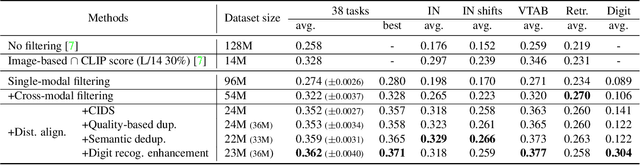

The quality of pre-training data plays a critical role in the performance of foundation models. Popular foundation models often design their own recipe for data filtering, which makes it hard to analyze and compare different data filtering approaches. DataComp is a new benchmark dedicated to evaluating different methods for data filtering. This paper describes our learning and solution when participating in the DataComp challenge. Our filtering strategy includes three stages: single-modality filtering, cross-modality filtering, and data distribution alignment. We integrate existing methods and propose new solutions, such as computing CLIP score on horizontally flipped images to mitigate the interference of scene text, using vision and language models to retrieve training samples for target downstream tasks, rebalancing the data distribution to improve the efficiency of allocating the computational budget, etc. We slice and dice our design choices, provide in-depth analysis, and discuss open questions. Our approach outperforms the best method from the DataComp paper by over 4% on the average performance of 38 tasks and by over 2% on ImageNet.
Graph Inverse Reinforcement Learning from Diverse Videos
Aug 01, 2022
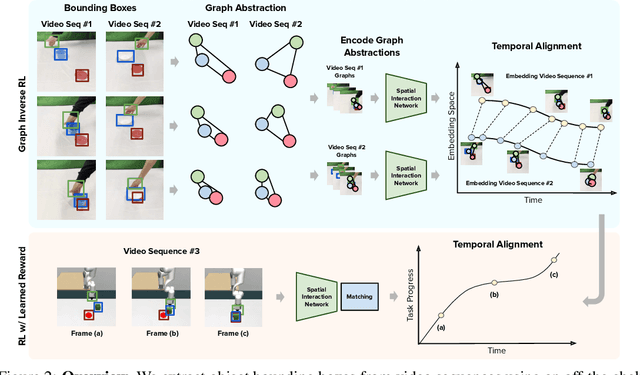

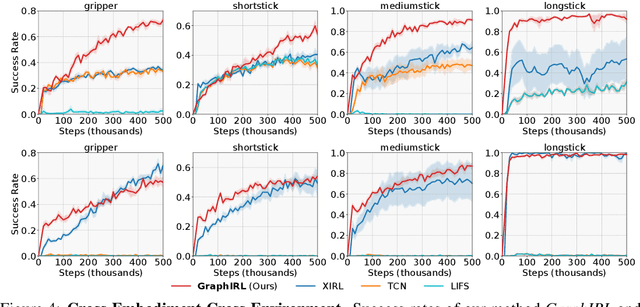
Research on Inverse Reinforcement Learning (IRL) from third-person videos has shown encouraging results on removing the need for manual reward design for robotic tasks. However, most prior works are still limited by training from a relatively restricted domain of videos. In this paper, we argue that the true potential of third-person IRL lies in increasing the diversity of videos for better scaling. To learn a reward function from diverse videos, we propose to perform graph abstraction on the videos followed by temporal matching in the graph space to measure the task progress. Our insight is that a task can be described by entity interactions that form a graph, and this graph abstraction can help remove irrelevant information such as textures, resulting in more robust reward functions. We evaluate our approach, GraphIRL, on cross-embodiment learning in X-MAGICAL and learning from human demonstrations for real-robot manipulation. We show significant improvements in robustness to diverse video demonstrations over previous approaches, and even achieve better results than manual reward design on a real robot pushing task. Videos are available at https://sateeshkumar21.github.io/GraphIRL .
Unsupervised Activity Segmentation by Joint Representation Learning and Online Clustering
May 28, 2021
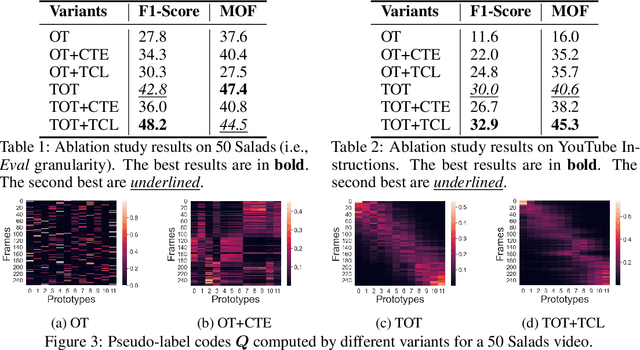
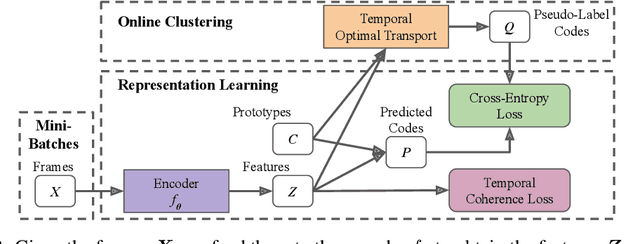
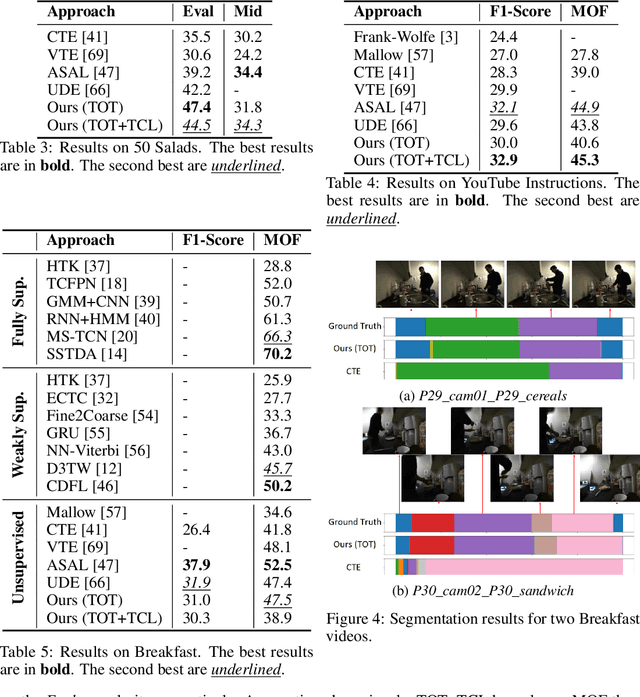
We present a novel approach for unsupervised activity segmentation, which uses video frame clustering as a pretext task and simultaneously performs representation learning and online clustering. This is in contrast with prior works where representation learning and clustering are often performed sequentially. We leverage temporal information in videos by employing temporal optimal transport and temporal coherence loss. In particular, we incorporate a temporal regularization term into the standard optimal transport module, which preserves the temporal order of the activity, yielding the temporal optimal transport module for computing pseudo-label cluster assignments. Next, the temporal coherence loss encourages neighboring video frames to be mapped to nearby points while distant video frames are mapped to farther away points in the embedding space. The combination of these two components results in effective representations for unsupervised activity segmentation. Furthermore, previous methods require storing learned features for the entire dataset before clustering them in an offline manner, whereas our approach processes one mini-batch at a time in an online manner. Extensive evaluations on three public datasets, i.e. 50-Salads, YouTube Instructions, and Breakfast, and our dataset, i.e., Desktop Assembly, show that our approach performs on par or better than previous methods for unsupervised activity segmentation, despite having significantly less memory constraints.
Learning by Aligning Videos in Time
Mar 31, 2021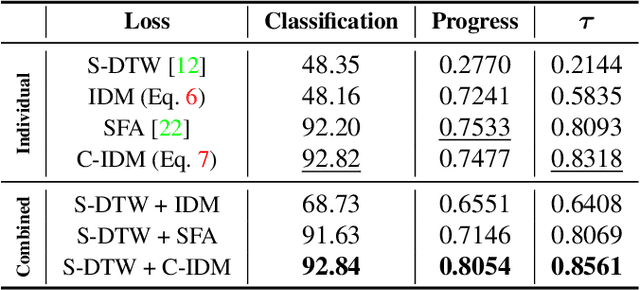
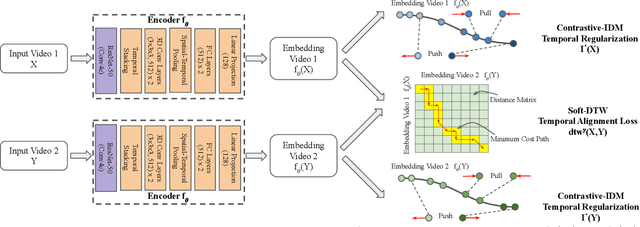
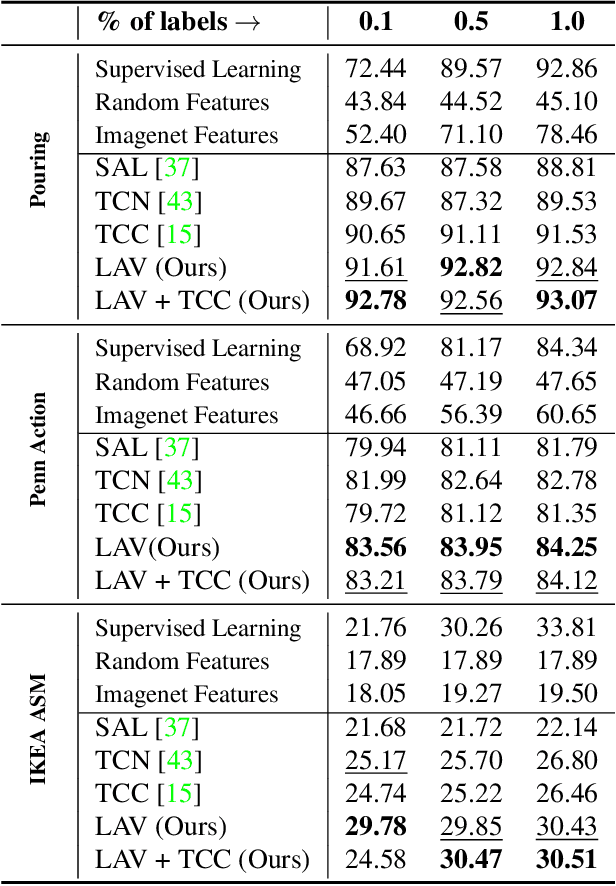
We present a self-supervised approach for learning video representations using temporal video alignment as a pretext task, while exploiting both frame-level and video-level information. We leverage a novel combination of temporal alignment loss and temporal regularization terms, which can be used as supervision signals for training an encoder network. Specifically, the temporal alignment loss (i.e., Soft-DTW) aims for the minimum cost for temporally aligning videos in the embedding space. However, optimizing solely for this term leads to trivial solutions, particularly, one where all frames get mapped to a small cluster in the embedding space. To overcome this problem, we propose a temporal regularization term (i.e., Contrastive-IDM) which encourages different frames to be mapped to different points in the embedding space. Extensive evaluations on various tasks, including action phase classification, action phase progression, and fine-grained frame retrieval, on three datasets, namely Pouring, Penn Action, and IKEA ASM, show superior performance of our approach over state-of-the-art methods for self-supervised representation learning from videos. In addition, our method provides significant performance gain where labeled data is lacking.
Towards Anomaly Detection in Dashcam Videos
May 12, 2020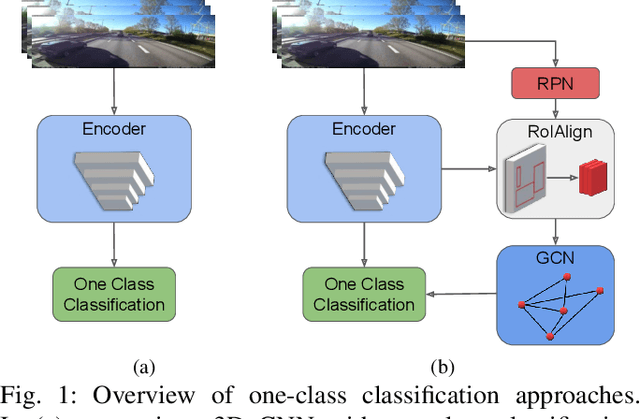
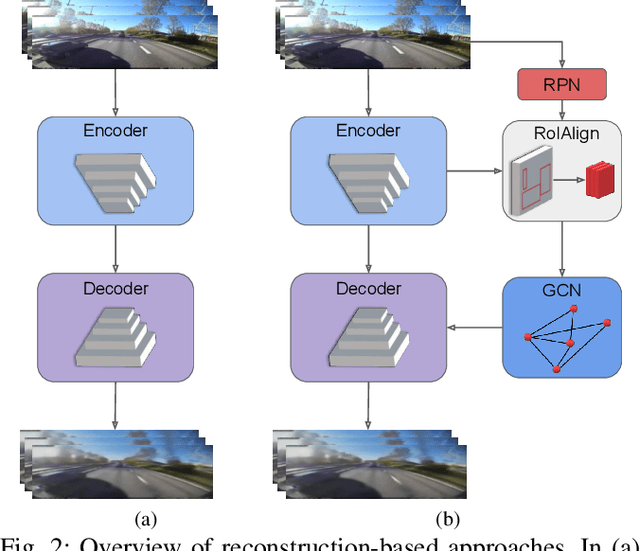


Inexpensive sensing and computation, as well as insurance innovations, have made smart dashboard cameras ubiquitous. Increasingly, simple model-driven computer vision algorithms focused on lane departures or safe following distances are finding their way into these devices. Unfortunately, the long-tailed distribution of road hazards means that these hand-crafted pipelines are inadequate for driver safety systems. We propose to apply data-driven anomaly detection ideas from deep learning to dashcam videos, which hold the promise of bridging this gap. Unfortunately, there exists almost no literature applying anomaly understanding to moving cameras, and correspondingly there is also a lack of relevant datasets. To counter this issue, we present a large and diverse dataset of truck dashcam videos, namely RetroTrucks, that includes normal and anomalous driving scenes. We apply: (i) one-class classification loss and (ii) reconstruction-based loss, for anomaly detection on RetroTrucks as well as on existing static-camera datasets. We introduce formulations for modeling object interactions in this context as priors. Our experiments indicate that our dataset is indeed more challenging than standard anomaly detection datasets, and previous anomaly detection methods do not perform well here out-of-the-box. In addition, we share insights into the behavior of these two important families of anomaly detection approaches on dashcam data.