 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Inverse Reinforcement Learning from Diverse Videos
Aug 01, 2022
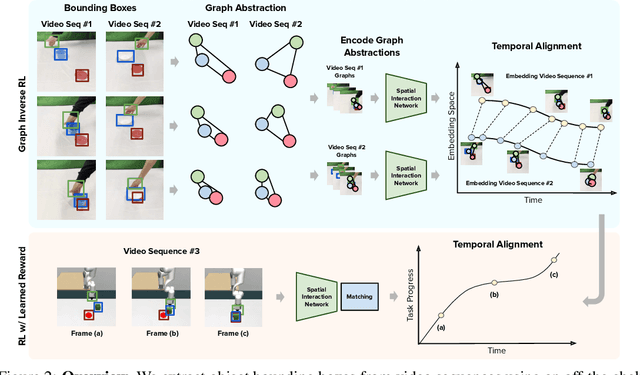

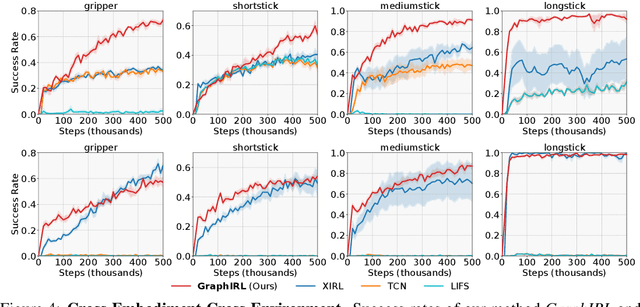
Research on Inverse Reinforcement Learning (IRL) from third-person videos has shown encouraging results on removing the need for manual reward design for robotic tasks. However, most prior works are still limited by training from a relatively restricted domain of videos. In this paper, we argue that the true potential of third-person IRL lies in increasing the diversity of videos for better scaling. To learn a reward function from diverse videos, we propose to perform graph abstraction on the videos followed by temporal matching in the graph space to measure the task progress. Our insight is that a task can be described by entity interactions that form a graph, and this graph abstraction can help remove irrelevant information such as textures, resulting in more robust reward functions. We evaluate our approach, GraphIRL, on cross-embodiment learning in X-MAGICAL and learning from human demonstrations for real-robot manipulation. We show significant improvements in robustness to diverse video demonstrations over previous approaches, and even achieve better results than manual reward design on a real robot pushing task. Videos are available at https://sateeshkumar21.github.io/GraphIRL .
Look Closer: Bridging Egocentric and Third-Person Views with Transformers for Robotic Manipulation
Jan 20, 2022
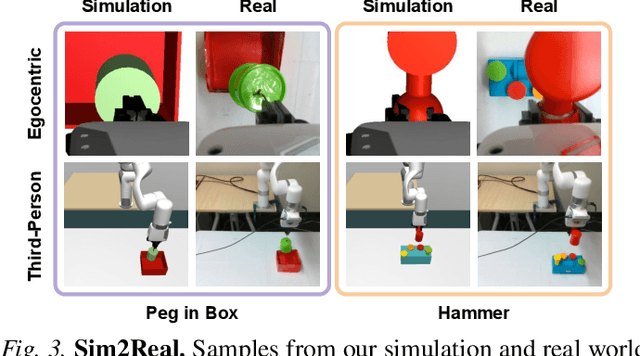
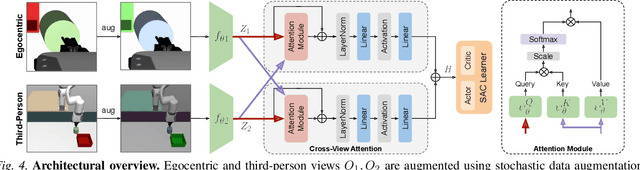

Learning to solve precision-based manipulation tasks from visual feedback using Reinforcement Learning (RL) could drastically reduce the engineering efforts required by traditional robot systems. However, performing fine-grained motor control from visual inputs alone is challenging, especially with a static third-person camera as often used in previous work. We propose a setting for robotic manipulation in which the agent receives visual feedback from both a third-person camera and an egocentric camera mounted on the robot's wrist. While the third-person camera is static, the egocentric camera enables the robot to actively control its vision to aid in precise manipulation. To fuse visual information from both cameras effectively, we additionally propose to use Transformers with a cross-view attention mechanism that models spatial attention from one view to another (and vice-versa), and use the learned features as input to an RL policy. Our method improves learning over strong single-view and multi-view baselines, and successfully transfers to a set of challenging manipulation tasks on a real robot with uncalibrated cameras, no access to state information, and a high degree of task variability. In a hammer manipulation task, our method succeeds in 75% of trials versus 38% and 13% for multi-view and single-view baselines, respectively.
Dynamic Cloth Manipulation with Deep Reinforcement Learning
Oct 31, 2019

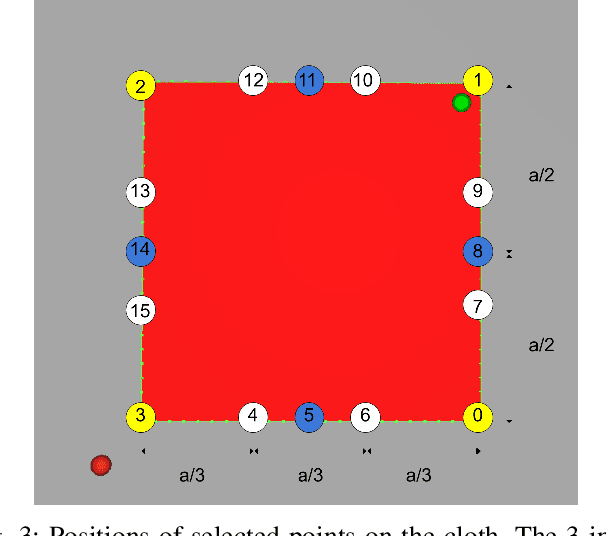
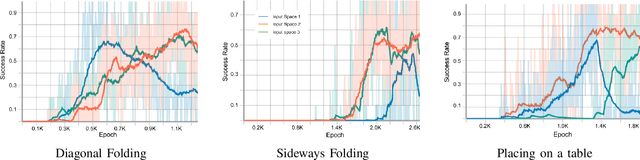
In this paper we present a Deep Reinforcement Learning approach to solve dynamic cloth manipulation tasks. Differing from the case of rigid objects, we stress that the followed trajectory (including speed and acceleration) has a decisive influence on the final state of cloth, which can greatly vary even if the positions reached by the grasped points are the same. We explore how goal positions for non-grasped points can be attained through learning adequate trajectories for the grasped points. Our approach uses few demonstrations to improve control policy learning, and a sparse reward approach to avoid engineering complex reward functions. Since perception of textiles is challenging, we also study different state representations to assess the minimum observation space required for learning to succeed. Finally, we compare different combinations of control policy encodings, demonstrations, and sparse reward learning techniques, and show that our proposed approach can learn dynamic cloth manipulation in an efficient way, i.e., using a reduced observation space, a few demonstrations, and a sparse reward.