 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned IMU Bias Prediction for Invariant Visual Inertial Odometry
May 10, 2025Autonomous mobile robots operating in novel environments depend critically on accurate state estimation, often utilizing visual and inertial measurements. Recent work has shown that an invariant formulation of the extended Kalman filter improves the convergence and robustness of visual-inertial odometry by utilizing the Lie group structure of a robot's position, velocity, and orientation states. However, inertial sensors also require measurement bias estimation, yet introducing the bias in the filter state breaks the Lie group symmetry. In this paper, we design a neural network to predict the bias of an inertial measurement unit (IMU) from a sequence of previous IMU measurements. This allows us to use an invariant filter for visual inertial odometry, relying on the learned bias prediction rather than introducing the bias in the filter state. We demonstrate that an invariant multi-state constraint Kalman filter (MSCKF) with learned bias predictions achieves robust visual-inertial odometry in real experiments, even when visual information is unavailable for extended periods and the system needs to rely solely on IMU measurements.
Hamiltonian Dynamics Learning from Point Cloud Observations for Nonholonomic Mobile Robot Control
Sep 17, 2023Reliable autonomous navigation requires adapting the control policy of a mobile robot in response to dynamics changes in different operational conditions. Hand-designed dynamics models may struggle to capture model variations due to a limited set of parameters. Data-driven dynamics learning approaches offer higher model capacity and better generalization but require large amounts of state-labeled data. This paper develops an approach for learning robot dynamics directly from point-cloud observations, removing the need and associated errors of state estimation, while embedding Hamiltonian structure in the dynamics model to improve data efficiency. We design an observation-space loss that relates motion prediction from the dynamics model with motion prediction from point-cloud registration to train a Hamiltonian neural ordinary differential equation. The learned Hamiltonian model enables the design of an energy-shaping model-based tracking controller for rigid-body robots. We demonstrate dynamics learning and tracking control on a real nonholonomic wheeled robot.
Look Closer: Bridging Egocentric and Third-Person Views with Transformers for Robotic Manipulation
Jan 20, 2022
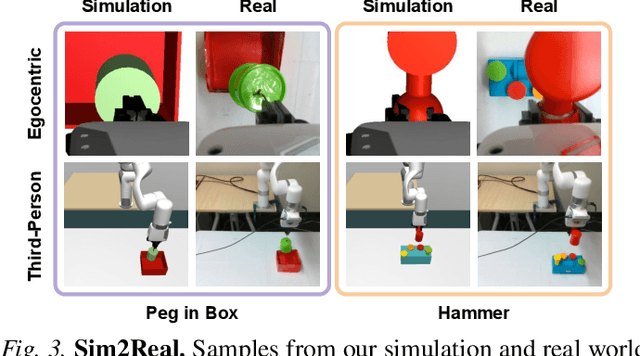
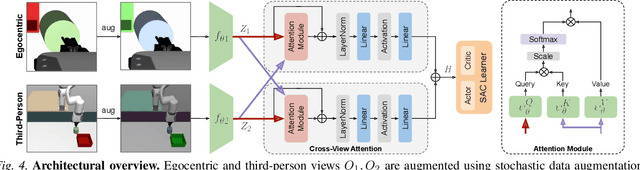

Learning to solve precision-based manipulation tasks from visual feedback using Reinforcement Learning (RL) could drastically reduce the engineering efforts required by traditional robot systems. However, performing fine-grained motor control from visual inputs alone is challenging, especially with a static third-person camera as often used in previous work. We propose a setting for robotic manipulation in which the agent receives visual feedback from both a third-person camera and an egocentric camera mounted on the robot's wrist. While the third-person camera is static, the egocentric camera enables the robot to actively control its vision to aid in precise manipulation. To fuse visual information from both cameras effectively, we additionally propose to use Transformers with a cross-view attention mechanism that models spatial attention from one view to another (and vice-versa), and use the learned features as input to an RL policy. Our method improves learning over strong single-view and multi-view baselines, and successfully transfers to a set of challenging manipulation tasks on a real robot with uncalibrated cameras, no access to state information, and a high degree of task variability. In a hammer manipulation task, our method succeeds in 75% of trials versus 38% and 13% for multi-view and single-view baselines, respectively.