 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNotes-to-Self: Scratchpad Augmented VLAs for Memory Dependent Manipulation Tasks
Feb 24, 2026Many dexterous manipulation tasks are non-markovian in nature, yet little attention has been paid to this fact in the recent upsurge of the vision-language-action (VLA) paradigm. Although they are successful in bringing internet-scale semantic understanding to robotics, existing VLAs are primarily "stateless" and struggle with memory-dependent long horizon tasks. In this work, we explore a way to impart both spatial and temporal memory to a VLA by incorporating a language scratchpad. The scratchpad makes it possible to memorize task-specific information, such as object positions, and it allows the model to keep track of a plan and progress towards subgoals within that plan. We evaluate this approach on a split of memory-dependent tasks from the ClevrSkills environment, on MemoryBench, as well as on a challenging real-world pick-and-place task. We show that incorporating a language scratchpad significantly improves generalization on these tasks for both non-recurrent and recurrent models.
ClevrSkills: Compositional Language and Visual Reasoning in Robotics
Nov 13, 2024



Robotics tasks are highly compositional by nature. For example, to perform a high-level task like cleaning the table a robot must employ low-level capabilities of moving the effectors to the objects on the table, pick them up and then move them off the table one-by-one, while re-evaluating the consequently dynamic scenario in the process. Given that large vision language models (VLMs) have shown progress on many tasks that require high level, human-like reasoning, we ask the question: if the models are taught the requisite low-level capabilities, can they compose them in novel ways to achieve interesting high-level tasks like cleaning the table without having to be explicitly taught so? To this end, we present ClevrSkills - a benchmark suite for compositional reasoning in robotics. ClevrSkills is an environment suite developed on top of the ManiSkill2 simulator and an accompanying dataset. The dataset contains trajectories generated on a range of robotics tasks with language and visual annotations as well as multi-modal prompts as task specification. The suite includes a curriculum of tasks with three levels of compositional understanding, starting with simple tasks requiring basic motor skills. We benchmark multiple different VLM baselines on ClevrSkills and show that even after being pre-trained on large numbers of tasks, these models fail on compositional reasoning in robotics tasks.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Habitat Synthetic Scenes Dataset (HSSD-200): An Analysis of 3D Scene Scale and Realism Tradeoffs for ObjectGoal Navigation
Jun 21, 2023We contribute the Habitat Synthetic Scene Dataset, a dataset of 211 high-quality 3D scenes, and use it to test navigation agent generalization to realistic 3D environments. Our dataset represents real interiors and contains a diverse set of 18,656 models of real-world objects. We investigate the impact of synthetic 3D scene dataset scale and realism on the task of training embodied agents to find and navigate to objects (ObjectGoal navigation). By comparing to synthetic 3D scene datasets from prior work, we find that scale helps in generalization, but the benefits quickly saturate, making visual fidelity and correlation to real-world scenes more important. Our experiments show that agents trained on our smaller-scale dataset can match or outperform agents trained on much larger datasets. Surprisingly, we observe that agents trained on just 122 scenes from our dataset outperform agents trained on 10,000 scenes from the ProcTHOR-10K dataset in terms of zero-shot generalization in real-world scanned environments.
Articulated 3D Human-Object Interactions from RGB Videos: An Empirical Analysis of Approaches and Challenges
Sep 12, 2022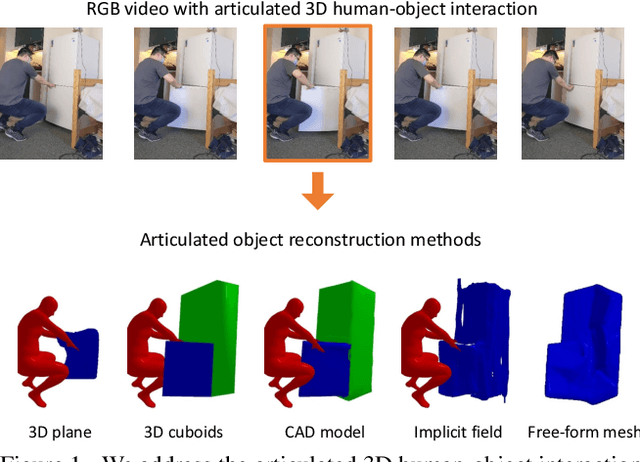
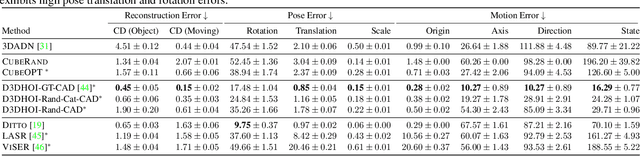
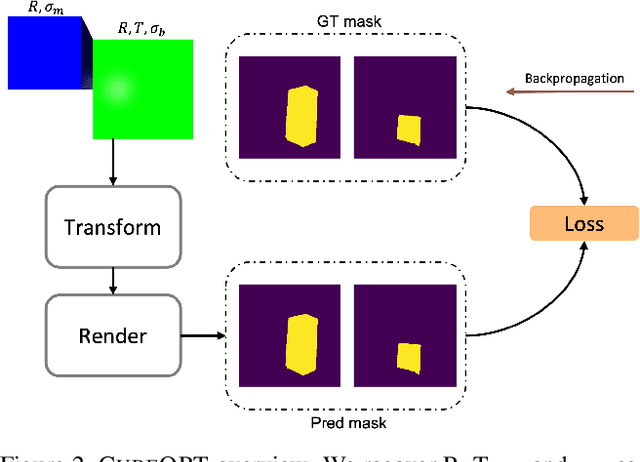
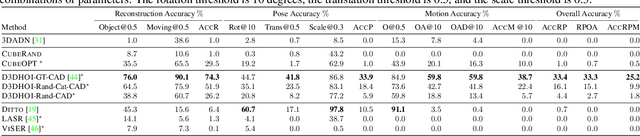
Human-object interactions with articulated objects are common in everyday life. Despite much progress in single-view 3D reconstruction, it is still challenging to infer an articulated 3D object model from an RGB video showing a person manipulating the object. We canonicalize the task of articulated 3D human-object interaction reconstruction from RGB video, and carry out a systematic benchmark of five families of methods for this task: 3D plane estimation, 3D cuboid estimation, CAD model fitting, implicit field fitting, and free-form mesh fitting. Our experiments show that all methods struggle to obtain high accuracy results even when provided ground truth information about the observed objects. We identify key factors which make the task challenging and suggest directions for future work on this challenging 3D computer vision task. Short video summary at https://www.youtube.com/watch?v=5tAlKBojZwc
Timestamp-Supervised Action Segmentation with Graph Convolutional Networks
Jun 30, 2022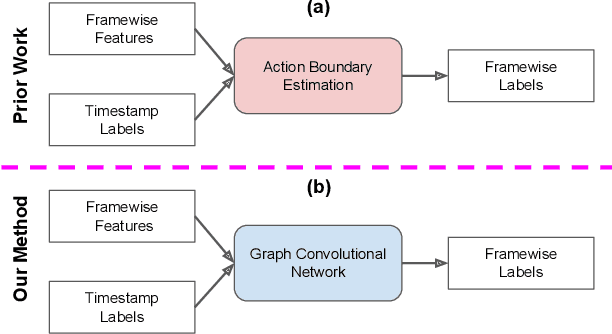
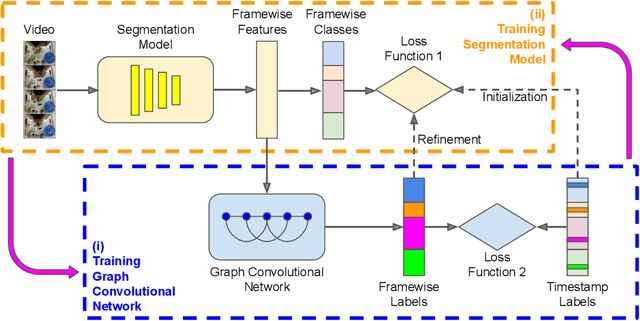

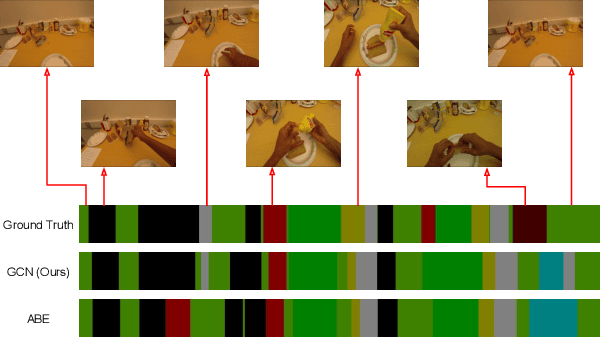
We introduce a novel approach for temporal activity segmentation with timestamp supervision. Our main contribution is a graph convolutional network, which is learned in an end-to-end manner to exploit both frame features and connections between neighboring frames to generate dense framewise labels from sparse timestamp labels. The generated dense framewise labels can then be used to train the segmentation model. In addition, we propose a framework for alternating learning of both the segmentation model and the graph convolutional model, which first initializes and then iteratively refines the learned models. Detailed experiments on four public datasets, including 50 Salads, GTEA, Breakfast, and Desktop Assembly, show that our method is superior to the multi-layer perceptron baseline, while performing on par with or better than the state of the art in temporal activity segmentation with timestamp supervision.
Unsupervised Activity Segmentation by Joint Representation Learning and Online Clustering
May 28, 2021
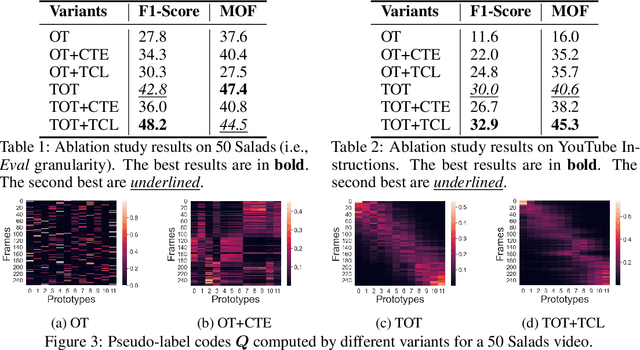
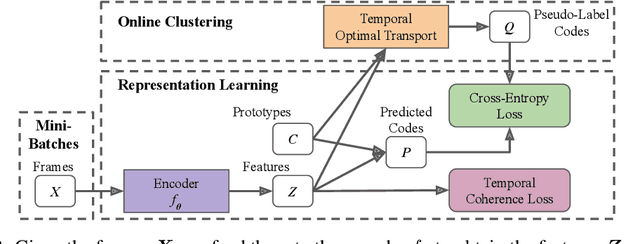
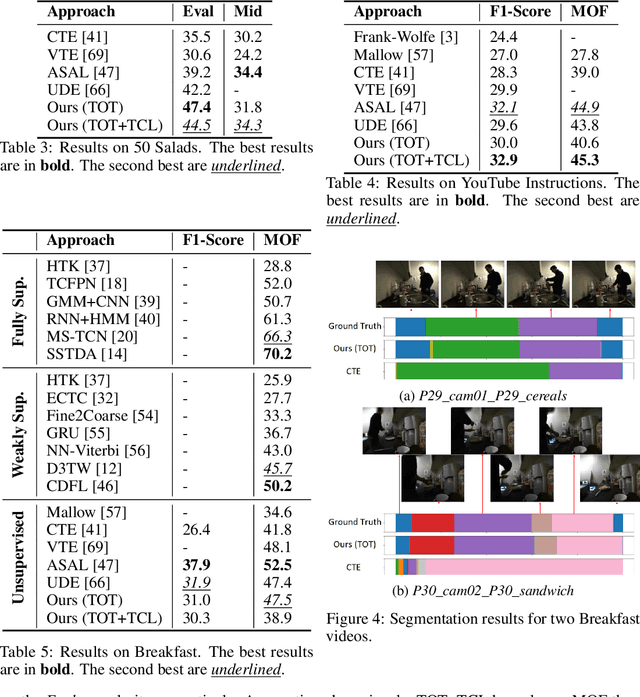
We present a novel approach for unsupervised activity segmentation, which uses video frame clustering as a pretext task and simultaneously performs representation learning and online clustering. This is in contrast with prior works where representation learning and clustering are often performed sequentially. We leverage temporal information in videos by employing temporal optimal transport and temporal coherence loss. In particular, we incorporate a temporal regularization term into the standard optimal transport module, which preserves the temporal order of the activity, yielding the temporal optimal transport module for computing pseudo-label cluster assignments. Next, the temporal coherence loss encourages neighboring video frames to be mapped to nearby points while distant video frames are mapped to farther away points in the embedding space. The combination of these two components results in effective representations for unsupervised activity segmentation. Furthermore, previous methods require storing learned features for the entire dataset before clustering them in an offline manner, whereas our approach processes one mini-batch at a time in an online manner. Extensive evaluations on three public datasets, i.e. 50-Salads, YouTube Instructions, and Breakfast, and our dataset, i.e., Desktop Assembly, show that our approach performs on par or better than previous methods for unsupervised activity segmentation, despite having significantly less memory constraints.
Learning by Aligning Videos in Time
Mar 31, 2021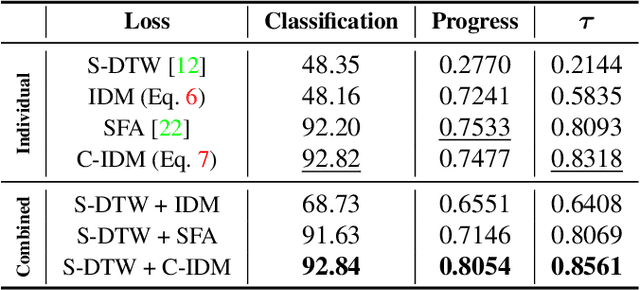
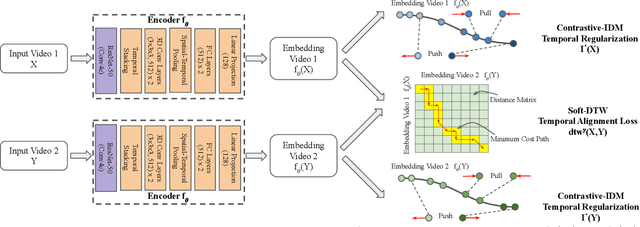
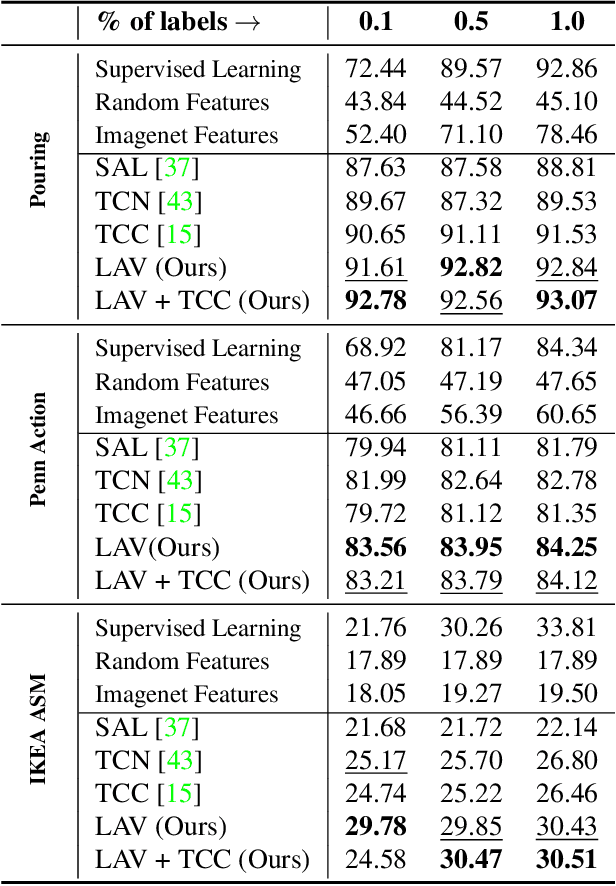
We present a self-supervised approach for learning video representations using temporal video alignment as a pretext task, while exploiting both frame-level and video-level information. We leverage a novel combination of temporal alignment loss and temporal regularization terms, which can be used as supervision signals for training an encoder network. Specifically, the temporal alignment loss (i.e., Soft-DTW) aims for the minimum cost for temporally aligning videos in the embedding space. However, optimizing solely for this term leads to trivial solutions, particularly, one where all frames get mapped to a small cluster in the embedding space. To overcome this problem, we propose a temporal regularization term (i.e., Contrastive-IDM) which encourages different frames to be mapped to different points in the embedding space. Extensive evaluations on various tasks, including action phase classification, action phase progression, and fine-grained frame retrieval, on three datasets, namely Pouring, Penn Action, and IKEA ASM, show superior performance of our approach over state-of-the-art methods for self-supervised representation learning from videos. In addition, our method provides significant performance gain where labeled data is lacking.
Towards Anomaly Detection in Dashcam Videos
May 12, 2020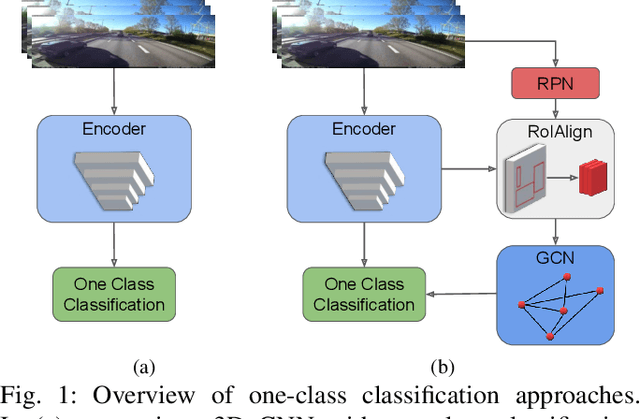
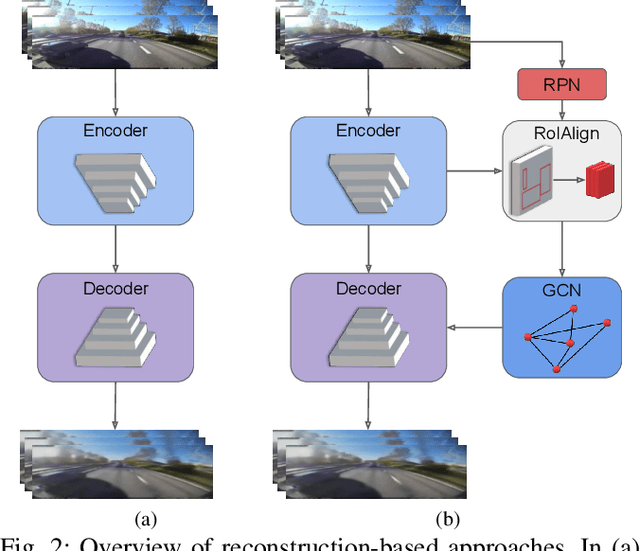


Inexpensive sensing and computation, as well as insurance innovations, have made smart dashboard cameras ubiquitous. Increasingly, simple model-driven computer vision algorithms focused on lane departures or safe following distances are finding their way into these devices. Unfortunately, the long-tailed distribution of road hazards means that these hand-crafted pipelines are inadequate for driver safety systems. We propose to apply data-driven anomaly detection ideas from deep learning to dashcam videos, which hold the promise of bridging this gap. Unfortunately, there exists almost no literature applying anomaly understanding to moving cameras, and correspondingly there is also a lack of relevant datasets. To counter this issue, we present a large and diverse dataset of truck dashcam videos, namely RetroTrucks, that includes normal and anomalous driving scenes. We apply: (i) one-class classification loss and (ii) reconstruction-based loss, for anomaly detection on RetroTrucks as well as on existing static-camera datasets. We introduce formulations for modeling object interactions in this context as priors. Our experiments indicate that our dataset is indeed more challenging than standard anomaly detection datasets, and previous anomaly detection methods do not perform well here out-of-the-box. In addition, we share insights into the behavior of these two important families of anomaly detection approaches on dashcam data.