 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPDMulti: Openable Part Detection for Multiple Objects
Mar 24, 2023Openable part detection is the task of detecting the openable parts of an object in a single-view image, and predicting corresponding motion parameters. Prior work investigated the unrealistic setting where all input images only contain a single openable object. We generalize this task to scenes with multiple objects each potentially possessing openable parts, and create a corresponding dataset based on real-world scenes. We then address this more challenging scenario with OPDFormer: a part-aware transformer architecture. Our experiments show that the OPDFormer architecture significantly outperforms prior work. The more realistic multiple-object scenarios we investigated remain challenging for all methods, indicating opportunities for future work.
Articulated 3D Human-Object Interactions from RGB Videos: An Empirical Analysis of Approaches and Challenges
Sep 12, 2022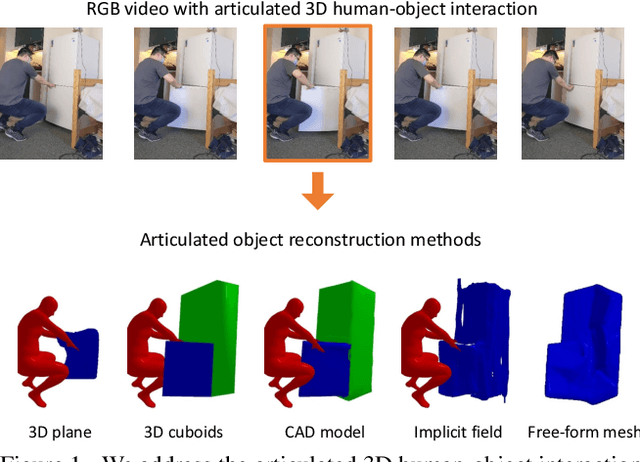
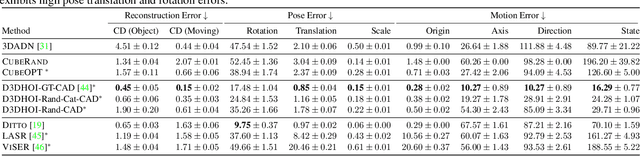
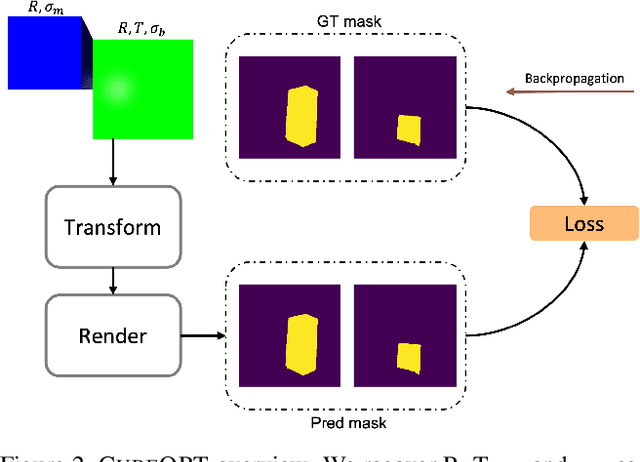
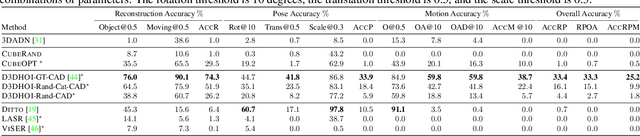
Human-object interactions with articulated objects are common in everyday life. Despite much progress in single-view 3D reconstruction, it is still challenging to infer an articulated 3D object model from an RGB video showing a person manipulating the object. We canonicalize the task of articulated 3D human-object interaction reconstruction from RGB video, and carry out a systematic benchmark of five families of methods for this task: 3D plane estimation, 3D cuboid estimation, CAD model fitting, implicit field fitting, and free-form mesh fitting. Our experiments show that all methods struggle to obtain high accuracy results even when provided ground truth information about the observed objects. We identify key factors which make the task challenging and suggest directions for future work on this challenging 3D computer vision task. Short video summary at https://www.youtube.com/watch?v=5tAlKBojZwc