 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPDMulti: Openable Part Detection for Multiple Objects
Mar 24, 2023Openable part detection is the task of detecting the openable parts of an object in a single-view image, and predicting corresponding motion parameters. Prior work investigated the unrealistic setting where all input images only contain a single openable object. We generalize this task to scenes with multiple objects each potentially possessing openable parts, and create a corresponding dataset based on real-world scenes. We then address this more challenging scenario with OPDFormer: a part-aware transformer architecture. Our experiments show that the OPDFormer architecture significantly outperforms prior work. The more realistic multiple-object scenarios we investigated remain challenging for all methods, indicating opportunities for future work.
Habitat-Matterport 3D Semantics Dataset
Oct 11, 2022
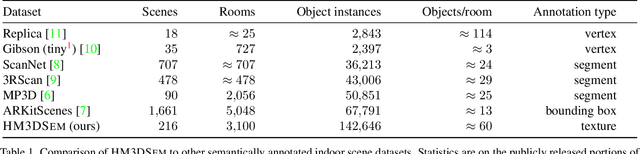

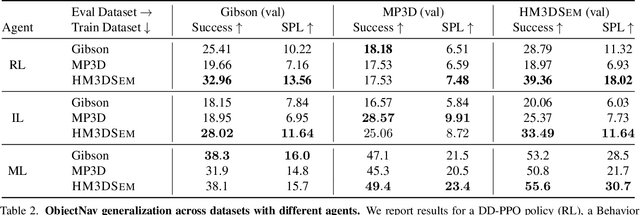
We present the Habitat-Matterport 3D Semantics (HM3DSEM) dataset. HM3DSEM is the largest dataset of 3D real-world spaces with densely annotated semantics that is currently available to the academic community. It consists of 142,646 object instance annotations across 216 3D spaces and 3,100 rooms within those spaces. The scale, quality, and diversity of object annotations far exceed those of datasets from prior work. A key difference setting apart HM3DSEM from other datasets is the use of texture information to annotate pixel-accurate object boundaries. We demonstrate the effectiveness of HM3DSEM dataset for the Object Goal Navigation task using different methods. Policies trained using HM3DSEM perform comparable or better than those trained on prior datasets.
Hierarchy Denoising Recursive Autoencoders for 3D Scene Layout Prediction
Apr 10, 2019
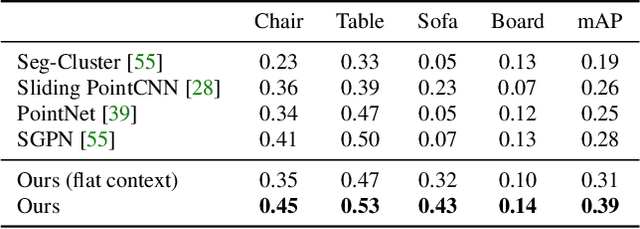


Indoor scenes exhibit rich hierarchical structure in 3D object layouts. Many tasks in 3D scene understanding can benefit from reasoning jointly about the hierarchical context of a scene, and the identities of objects. We present a variational denoising recursive autoencoder (VDRAE) that generates and iteratively refines a hierarchical representation of 3D object layouts, interleaving bottom-up encoding for context aggregation and top-down decoding for propagation. We train our VDRAE on large-scale 3D scene datasets to predict both instance-level segmentations and a 3D object detections from an over-segmentation of an input point cloud. We show that our VDRAE improves object detection performance on real-world 3D point cloud datasets compared to baselines from prior work.