 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHabitat-Matterport 3D Semantics Dataset
Oct 11, 2022
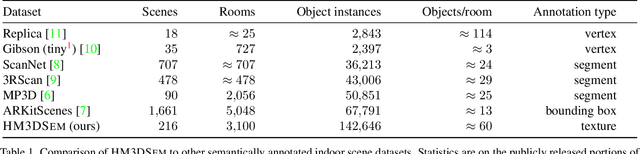

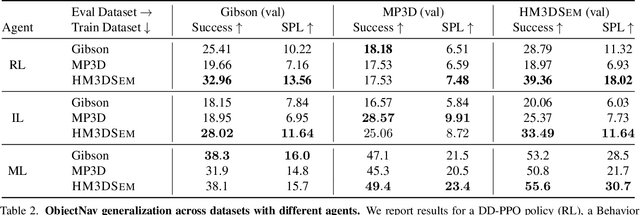
We present the Habitat-Matterport 3D Semantics (HM3DSEM) dataset. HM3DSEM is the largest dataset of 3D real-world spaces with densely annotated semantics that is currently available to the academic community. It consists of 142,646 object instance annotations across 216 3D spaces and 3,100 rooms within those spaces. The scale, quality, and diversity of object annotations far exceed those of datasets from prior work. A key difference setting apart HM3DSEM from other datasets is the use of texture information to annotate pixel-accurate object boundaries. We demonstrate the effectiveness of HM3DSEM dataset for the Object Goal Navigation task using different methods. Policies trained using HM3DSEM perform comparable or better than those trained on prior datasets.
Habitat 2.0: Training Home Assistants to Rearrange their Habitat
Jun 28, 2021


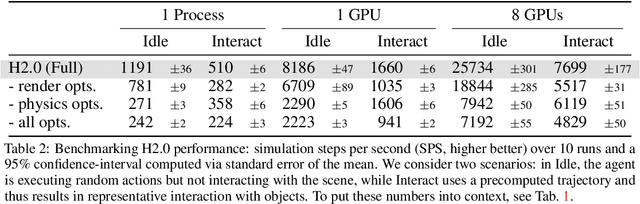
We introduce Habitat 2.0 (H2.0), a simulation platform for training virtual robots in interactive 3D environments and complex physics-enabled scenarios. We make comprehensive contributions to all levels of the embodied AI stack - data, simulation, and benchmark tasks. Specifically, we present: (i) ReplicaCAD: an artist-authored, annotated, reconfigurable 3D dataset of apartments (matching real spaces) with articulated objects (e.g. cabinets and drawers that can open/close); (ii) H2.0: a high-performance physics-enabled 3D simulator with speeds exceeding 25,000 simulation steps per second (850x real-time) on an 8-GPU node, representing 100x speed-ups over prior work; and, (iii) Home Assistant Benchmark (HAB): a suite of common tasks for assistive robots (tidy the house, prepare groceries, set the table) that test a range of mobile manipulation capabilities. These large-scale engineering contributions allow us to systematically compare deep reinforcement learning (RL) at scale and classical sense-plan-act (SPA) pipelines in long-horizon structured tasks, with an emphasis on generalization to new objects, receptacles, and layouts. We find that (1) flat RL policies struggle on HAB compared to hierarchical ones; (2) a hierarchy with independent skills suffers from 'hand-off problems', and (3) SPA pipelines are more brittle than RL policies.