 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTLD: Sim-to-real Privileged Tactile Latent Distillation for Dexterous Manipulation
Mar 04, 2026Tactile dexterous manipulation is essential to automating complex household tasks, yet learning effective control policies remains a challenge. While recent work has relied on imitation learning, obtaining high quality demonstrations for multi-fingered hands via robot teleoperation or kinesthetic teaching is prohibitive. Alternatively, with reinforcement we can learn skills in simulation, but fast and realistic simulation of tactile observations is challenging. To bridge this gap, we introduce PTLD: sim-to-real Privileged Tactile Latent Distillation, a novel approach to learning tactile manipulation skills without requiring tactile simulation. Instead of simulating tactile sensors or relying purely on proprioceptive policies to transfer zero-shot sim-to-real, our key idea is to leverage privileged sensors in the real world to collect real-world tactile policy data. This data is then used to distill a robust state estimator that operates on tactile input. We demonstrate from our experiments that PTLD can be used to improve proprioceptive manipulation policies trained in simulation significantly by incorporating tactile sensing. On the benchmark in-hand rotation task, PTLD achieves a 182% improvement over a proprioception only policy. We also show that PTLD enables learning the challenging task of tactile in-hand reorientation where we see a 57% improvement in the number of goals reached over using proprioception alone. Website: https://akashsharma02.github.io/ptld-website/.
HydroShear: Hydroelastic Shear Simulation for Tactile Sim-to-Real Reinforcement Learning
Feb 28, 2026In this paper, we address the problem of tactile sim-to-real policy transfer for contact-rich tasks. Existing methods primarily focus on vision-based sensors and emphasize image rendering quality while providing overly simplistic models of force and shear. Consequently, these models exhibit a large sim-to-real gap for many dexterous tasks. Here, we present HydroShear, a non-holonomic hydroelastic tactile simulator that advances the state-of-the-art by modeling: a) stick-slip transitions, b) path-dependent force and shear build up, and c) full SE(3) object-sensor interactions. HydroShear extends hydroelastic contact models using Signed Distance Functions (SDFs) to track the displacements of the on-surface points of an indenter during physical interaction with the sensor membrane. Our approach generates physics-based, computationally efficient force fields from arbitrary watertight geometries while remaining agnostic to the underlying physics engine. In experiments with GelSight Minis, HydroShear more faithfully reproduces real tactile shear compared to existing methods. This fidelity enables zero-shot sim-to-real transfer of reinforcement learning policies across four tasks: peg insertion, bin packing, book shelving for insertion, and drawer pulling for fine gripper control under slip. Our method achieves a 93% average success rate, outperforming policies trained on tactile images (34%) and alternative shear simulation methods (58%-61%).
TactAlign: Human-to-Robot Policy Transfer via Tactile Alignment
Feb 14, 2026Human demonstrations collected by wearable devices (e.g., tactile gloves) provide fast and dexterous supervision for policy learning, and are guided by rich, natural tactile feedback. However, a key challenge is how to transfer human-collected tactile signals to robots despite the differences in sensing modalities and embodiment. Existing human-to-robot (H2R) approaches that incorporate touch often assume identical tactile sensors, require paired data, and involve little to no embodiment gap between human demonstrator and the robots, limiting scalability and generality. We propose TactAlign, a cross-embodiment tactile alignment method that transfers human-collected tactile signals to a robot with different embodiment. TactAlign transforms human and robot tactile observations into a shared latent representation using a rectified flow, without paired datasets, manual labels, or privileged information. Our method enables low-cost latent transport guided by hand-object interaction-derived pseudo-pairs. We demonstrate that TactAlign improves H2R policy transfer across multiple contact-rich tasks (pivoting, insertion, lid closing), generalizes to unseen objects and tasks with human data (less than 5 minutes), and enables zero-shot H2R transfer on a highly dexterous tasks (light bulb screwing).
Visuo-Tactile World Models
Feb 05, 2026We introduce multi-task Visuo-Tactile World Models (VT-WM), which capture the physics of contact through touch reasoning. By complementing vision with tactile sensing, VT-WM better understands robot-object interactions in contact-rich tasks, avoiding common failure modes of vision-only models under occlusion or ambiguous contact states, such as objects disappearing, teleporting, or moving in ways that violate basic physics. Trained across a set of contact-rich manipulation tasks, VT-WM improves physical fidelity in imagination, achieving 33% better performance at maintaining object permanence and 29% better compliance with the laws of motion in autoregressive rollouts. Moreover, experiments show that grounding in contact dynamics also translates to planning. In zero-shot real-robot experiments, VT-WM achieves up to 35% higher success rates, with the largest gains in multi-step, contact-rich tasks. Finally, VT-WM demonstrates significant downstream versatility, effectively adapting its learned contact dynamics to a novel task and achieving reliable planning success with only a limited set of demonstrations.
Tactile Beyond Pixels: Multisensory Touch Representations for Robot Manipulation
Jun 17, 2025We present Sparsh-X, the first multisensory touch representations across four tactile modalities: image, audio, motion, and pressure. Trained on ~1M contact-rich interactions collected with the Digit 360 sensor, Sparsh-X captures complementary touch signals at diverse temporal and spatial scales. By leveraging self-supervised learning, Sparsh-X fuses these modalities into a unified representation that captures physical properties useful for robot manipulation tasks. We study how to effectively integrate real-world touch representations for both imitation learning and tactile adaptation of sim-trained policies, showing that Sparsh-X boosts policy success rates by 63% over an end-to-end model using tactile images and improves robustness by 90% in recovering object states from touch. Finally, we benchmark Sparsh-X ability to make inferences about physical properties, such as object-action identification, material-quantity estimation, and force estimation. Sparsh-X improves accuracy in characterizing physical properties by 48% compared to end-to-end approaches, demonstrating the advantages of multisensory pretraining for capturing features essential for dexterous manipulation.
Self-supervised perception for tactile skin covered dexterous hands
May 16, 2025We present Sparsh-skin, a pre-trained encoder for magnetic skin sensors distributed across the fingertips, phalanges, and palm of a dexterous robot hand. Magnetic tactile skins offer a flexible form factor for hand-wide coverage with fast response times, in contrast to vision-based tactile sensors that are restricted to the fingertips and limited by bandwidth. Full hand tactile perception is crucial for robot dexterity. However, a lack of general-purpose models, challenges with interpreting magnetic flux and calibration have limited the adoption of these sensors. Sparsh-skin, given a history of kinematic and tactile sensing across a hand, outputs a latent tactile embedding that can be used in any downstream task. The encoder is self-supervised via self-distillation on a variety of unlabeled hand-object interactions using an Allegro hand sensorized with Xela uSkin. In experiments across several benchmark tasks, from state estimation to policy learning, we find that pretrained Sparsh-skin representations are both sample efficient in learning downstream tasks and improve task performance by over 41% compared to prior work and over 56% compared to end-to-end learning.
Geometric Retargeting: A Principled, Ultrafast Neural Hand Retargeting Algorithm
Mar 10, 2025We introduce Geometric Retargeting (GeoRT), an ultrafast, and principled neural hand retargeting algorithm for teleoperation, developed as part of our recent Dexterity Gen (DexGen) system. GeoRT converts human finger keypoints to robot hand keypoints at 1KHz, achieving state-of-the-art speed and accuracy with significantly fewer hyperparameters. This high-speed capability enables flexible postprocessing, such as leveraging a foundational controller for action correction like DexGen. GeoRT is trained in an unsupervised manner, eliminating the need for manual annotation of hand pairs. The core of GeoRT lies in novel geometric objective functions that capture the essence of retargeting: preserving motion fidelity, ensuring configuration space (C-space) coverage, maintaining uniform response through high flatness, pinch correspondence and preventing self-collisions. This approach is free from intensive test-time optimization, offering a more scalable and practical solution for real-time hand retargeting.
OTTER: A Vision-Language-Action Model with Text-Aware Visual Feature Extraction
Mar 05, 2025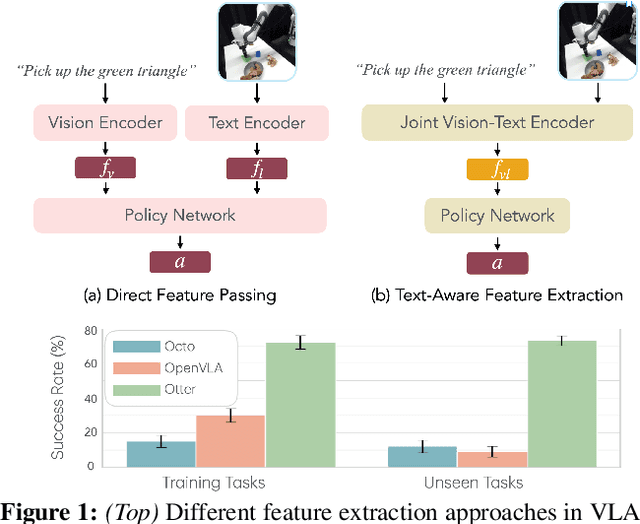
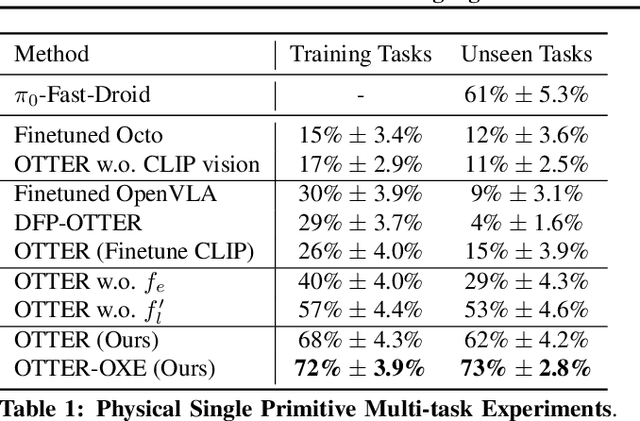
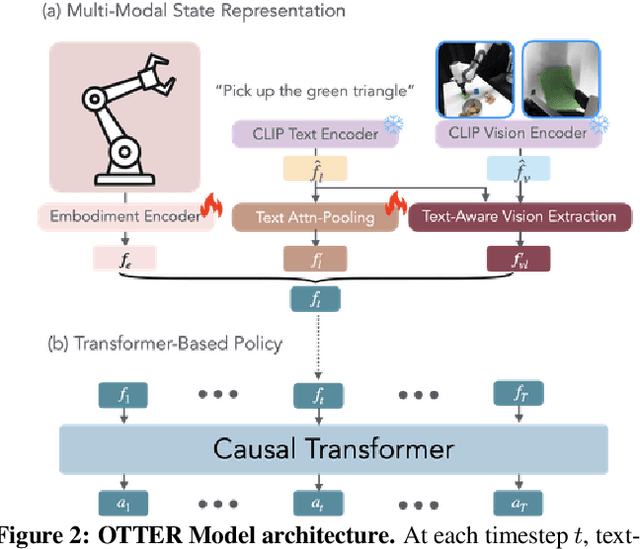
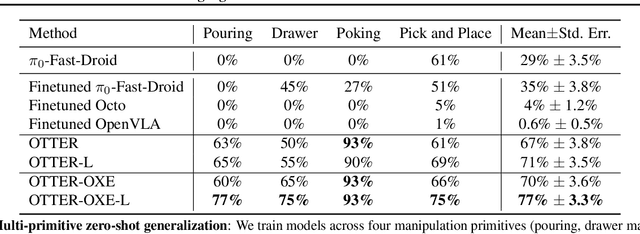
Vision-Language-Action (VLA) models aim to predict robotic actions based on visual observations and language instructions. Existing approaches require fine-tuning pre-trained visionlanguage models (VLMs) as visual and language features are independently fed into downstream policies, degrading the pre-trained semantic alignments. We propose OTTER, a novel VLA architecture that leverages these existing alignments through explicit, text-aware visual feature extraction. Instead of processing all visual features, OTTER selectively extracts and passes only task-relevant visual features that are semantically aligned with the language instruction to the policy transformer. This allows OTTER to keep the pre-trained vision-language encoders frozen. Thereby, OTTER preserves and utilizes the rich semantic understanding learned from large-scale pre-training, enabling strong zero-shot generalization capabilities. In simulation and real-world experiments, OTTER significantly outperforms existing VLA models, demonstrating strong zeroshot generalization to novel objects and environments. Video, code, checkpoints, and dataset: https://ottervla.github.io/.
DexterityGen: Foundation Controller for Unprecedented Dexterity
Feb 06, 2025



Teaching robots dexterous manipulation skills, such as tool use, presents a significant challenge. Current approaches can be broadly categorized into two strategies: human teleoperation (for imitation learning) and sim-to-real reinforcement learning. The first approach is difficult as it is hard for humans to produce safe and dexterous motions on a different embodiment without touch feedback. The second RL-based approach struggles with the domain gap and involves highly task-specific reward engineering on complex tasks. Our key insight is that RL is effective at learning low-level motion primitives, while humans excel at providing coarse motion commands for complex, long-horizon tasks. Therefore, the optimal solution might be a combination of both approaches. In this paper, we introduce DexterityGen (DexGen), which uses RL to pretrain large-scale dexterous motion primitives, such as in-hand rotation or translation. We then leverage this learned dataset to train a dexterous foundational controller. In the real world, we use human teleoperation as a prompt to the controller to produce highly dexterous behavior. We evaluate the effectiveness of DexGen in both simulation and real world, demonstrating that it is a general-purpose controller that can realize input dexterous manipulation commands and significantly improves stability by 10-100x measured as duration of holding objects across diverse tasks. Notably, with DexGen we demonstrate unprecedented dexterous skills including diverse object reorientation and dexterous tool use such as pen, syringe, and screwdriver for the first time.
Sparsh: Self-supervised touch representations for vision-based tactile sensing
Oct 31, 2024In this work, we introduce general purpose touch representations for the increasingly accessible class of vision-based tactile sensors. Such sensors have led to many recent advances in robot manipulation as they markedly complement vision, yet solutions today often rely on task and sensor specific handcrafted perception models. Collecting real data at scale with task centric ground truth labels, like contact forces and slip, is a challenge further compounded by sensors of various form factor differing in aspects like lighting and gel markings. To tackle this we turn to self-supervised learning (SSL) that has demonstrated remarkable performance in computer vision. We present Sparsh, a family of SSL models that can support various vision-based tactile sensors, alleviating the need for custom labels through pre-training on 460k+ tactile images with masking and self-distillation in pixel and latent spaces. We also build TacBench, to facilitate standardized benchmarking across sensors and models, comprising of six tasks ranging from comprehending tactile properties to enabling physical perception and manipulation planning. In evaluations, we find that SSL pre-training for touch representation outperforms task and sensor-specific end-to-end training by 95.1% on average over TacBench, and Sparsh (DINO) and Sparsh (IJEPA) are the most competitive, indicating the merits of learning in latent space for tactile images. Project page: https://sparsh-ssl.github.io/