 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do LLM Preferences Predict Downstream Behavior?
Feb 21, 2026Preference-driven behavior in LLMs may be a necessary precondition for AI misalignment such as sandbagging: models cannot strategically pursue misaligned goals unless their behavior is influenced by their preferences. Yet prior work has typically prompted models explicitly to act in specific ways, leaving unclear whether observed behaviors reflect instruction-following capabilities vs underlying model preferences. Here we test whether this precondition for misalignment is present. Using entity preferences as a behavioral probe, we measure whether stated preferences predict downstream behavior in five frontier LLMs across three domains: donation advice, refusal behavior, and task performance. Conceptually replicating prior work, we first confirm that all five models show highly consistent preferences across two independent measurement methods. We then test behavioral consequences in a simulated user environment. We find that all five models give preference-aligned donation advice. All five models also show preference-correlated refusal patterns when asked to recommend donations, refusing more often for less-preferred entities. All preference-related behaviors that we observe here emerge without instructions to act on preferences. Results for task performance are mixed: on a question-answering benchmark (BoolQ), two models show small but significant accuracy differences favoring preferred entities; one model shows the opposite pattern; and two models show no significant relationship. On complex agentic tasks, we find no evidence of preference-driven performance differences. While LLMs have consistent preferences that reliably predict advice-giving behavior, these preferences do not consistently translate into downstream task performance.
TaskMet: Task-Driven Metric Learning for Model Learning
Dec 08, 2023



Deep learning models are often deployed in downstream tasks that the training procedure may not be aware of. For example, models solely trained to achieve accurate predictions may struggle to perform well on downstream tasks because seemingly small prediction errors may incur drastic task errors. The standard end-to-end learning approach is to make the task loss differentiable or to introduce a differentiable surrogate that the model can be trained on. In these settings, the task loss needs to be carefully balanced with the prediction loss because they may have conflicting objectives. We propose take the task loss signal one level deeper than the parameters of the model and use it to learn the parameters of the loss function the model is trained on, which can be done by learning a metric in the prediction space. This approach does not alter the optimal prediction model itself, but rather changes the model learning to emphasize the information important for the downstream task. This enables us to achieve the best of both worlds: a prediction model trained in the original prediction space while also being valuable for the desired downstream task. We validate our approach through experiments conducted in two main settings: 1) decision-focused model learning scenarios involving portfolio optimization and budget allocation, and 2) reinforcement learning in noisy environments with distracting states. The source code to reproduce our experiments is available at https://github.com/facebookresearch/taskmet
$f$-Cal: Calibrated aleatoric uncertainty estimation from neural networks for robot perception
Sep 28, 2021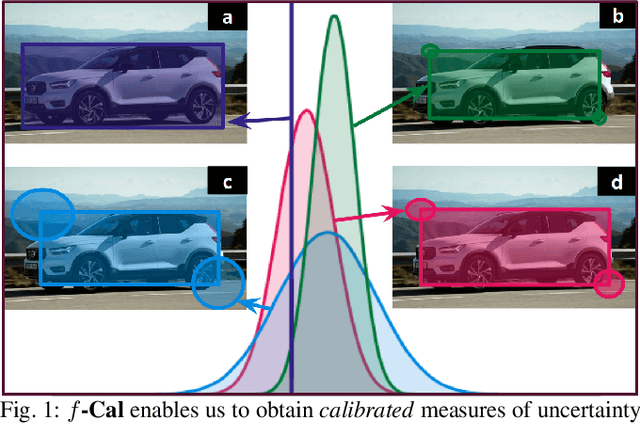
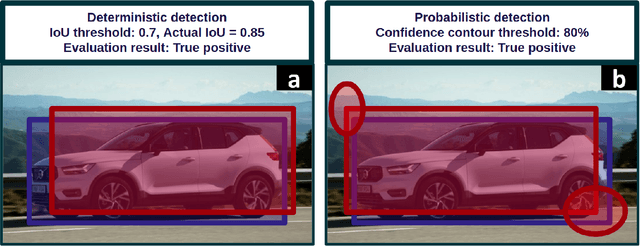
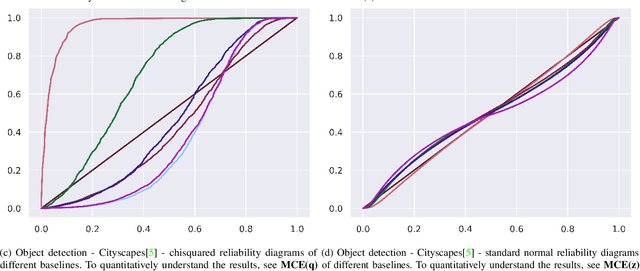
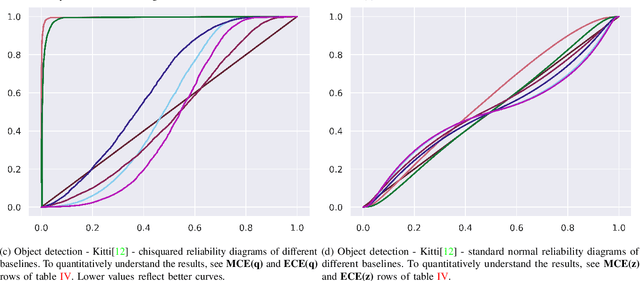
While modern deep neural networks are performant perception modules, performance (accuracy) alone is insufficient, particularly for safety-critical robotic applications such as self-driving vehicles. Robot autonomy stacks also require these otherwise blackbox models to produce reliable and calibrated measures of confidence on their predictions. Existing approaches estimate uncertainty from these neural network perception stacks by modifying network architectures, inference procedure, or loss functions. However, in general, these methods lack calibration, meaning that the predictive uncertainties do not faithfully represent the true underlying uncertainties (process noise). Our key insight is that calibration is only achieved by imposing constraints across multiple examples, such as those in a mini-batch; as opposed to existing approaches which only impose constraints per-sample, often leading to overconfident (thus miscalibrated) uncertainty estimates. By enforcing the distribution of outputs of a neural network to resemble a target distribution by minimizing an $f$-divergence, we obtain significantly better-calibrated models compared to prior approaches. Our approach, $f$-Cal, outperforms existing uncertainty calibration approaches on robot perception tasks such as object detection and monocular depth estimation over multiple real-world benchmarks.