 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Representations for Safer Policy Learning
Feb 27, 2025



Reinforcement learning algorithms typically necessitate extensive exploration of the state space to find optimal policies. However, in safety-critical applications, the risks associated with such exploration can lead to catastrophic consequences. Existing safe exploration methods attempt to mitigate this by imposing constraints, which often result in overly conservative behaviours and inefficient learning. Heavy penalties for early constraint violations can trap agents in local optima, deterring exploration of risky yet high-reward regions of the state space. To address this, we introduce a method that explicitly learns state-conditioned safety representations. By augmenting the state features with these safety representations, our approach naturally encourages safer exploration without being excessively cautious, resulting in more efficient and safer policy learning in safety-critical scenarios. Empirical evaluations across diverse environments show that our method significantly improves task performance while reducing constraint violations during training, underscoring its effectiveness in balancing exploration with safety.
Sample Efficient Deep Reinforcement Learning via Uncertainty Estimation
Jan 05, 2022
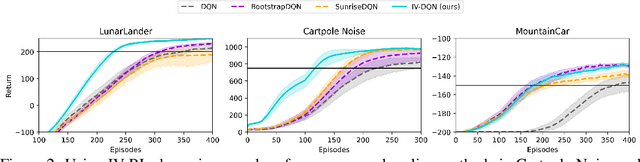
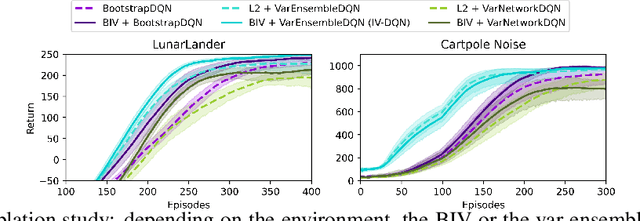
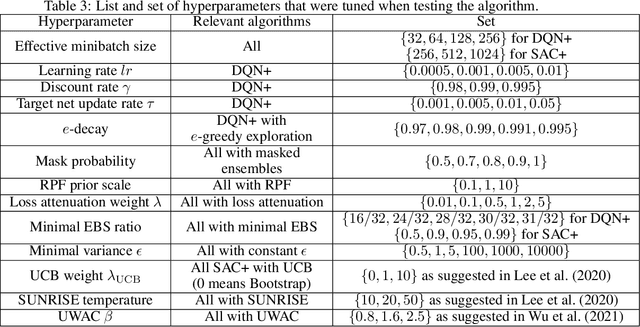
In model-free deep reinforcement learning (RL) algorithms, using noisy value estimates to supervise policy evaluation and optimization is detrimental to the sample efficiency. As this noise is heteroscedastic, its effects can be mitigated using uncertainty-based weights in the optimization process. Previous methods rely on sampled ensembles, which do not capture all aspects of uncertainty. We provide a systematic analysis of the sources of uncertainty in the noisy supervision that occurs in RL, and introduce inverse-variance RL, a Bayesian framework which combines probabilistic ensembles and Batch Inverse Variance weighting. We propose a method whereby two complementary uncertainty estimation methods account for both the Q-value and the environment stochasticity to better mitigate the negative impacts of noisy supervision. Our results show significant improvement in terms of sample efficiency on discrete and continuous control tasks.
$f$-Cal: Calibrated aleatoric uncertainty estimation from neural networks for robot perception
Sep 28, 2021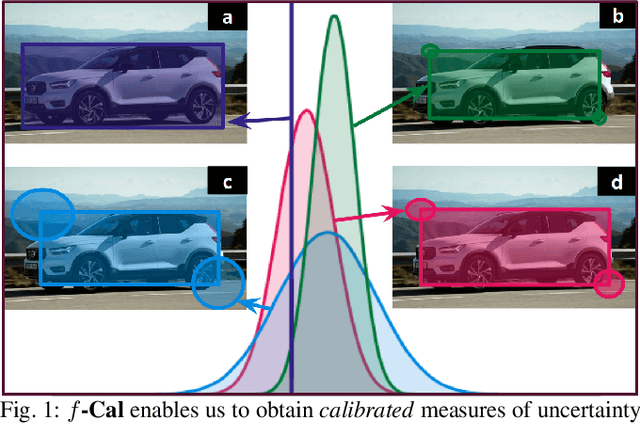
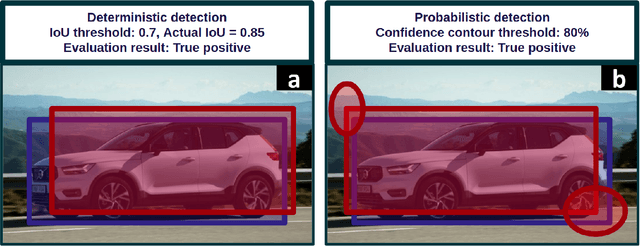
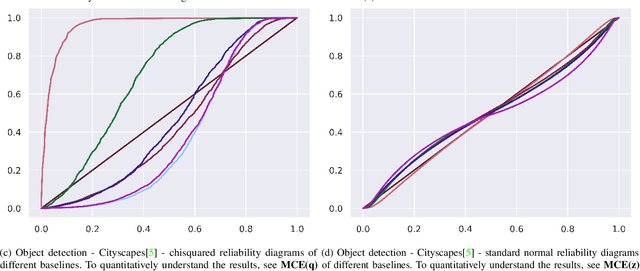
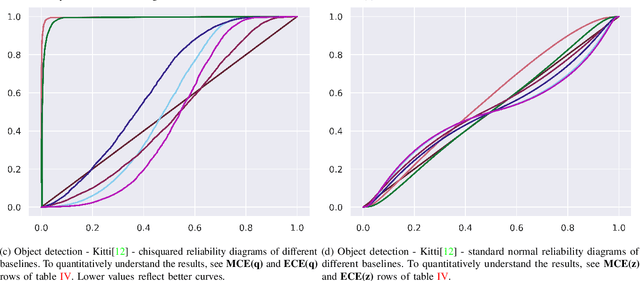
While modern deep neural networks are performant perception modules, performance (accuracy) alone is insufficient, particularly for safety-critical robotic applications such as self-driving vehicles. Robot autonomy stacks also require these otherwise blackbox models to produce reliable and calibrated measures of confidence on their predictions. Existing approaches estimate uncertainty from these neural network perception stacks by modifying network architectures, inference procedure, or loss functions. However, in general, these methods lack calibration, meaning that the predictive uncertainties do not faithfully represent the true underlying uncertainties (process noise). Our key insight is that calibration is only achieved by imposing constraints across multiple examples, such as those in a mini-batch; as opposed to existing approaches which only impose constraints per-sample, often leading to overconfident (thus miscalibrated) uncertainty estimates. By enforcing the distribution of outputs of a neural network to resemble a target distribution by minimizing an $f$-divergence, we obtain significantly better-calibrated models compared to prior approaches. Our approach, $f$-Cal, outperforms existing uncertainty calibration approaches on robot perception tasks such as object detection and monocular depth estimation over multiple real-world benchmarks.
AutoLay: Benchmarking amodal layout estimation for autonomous driving
Aug 20, 2021


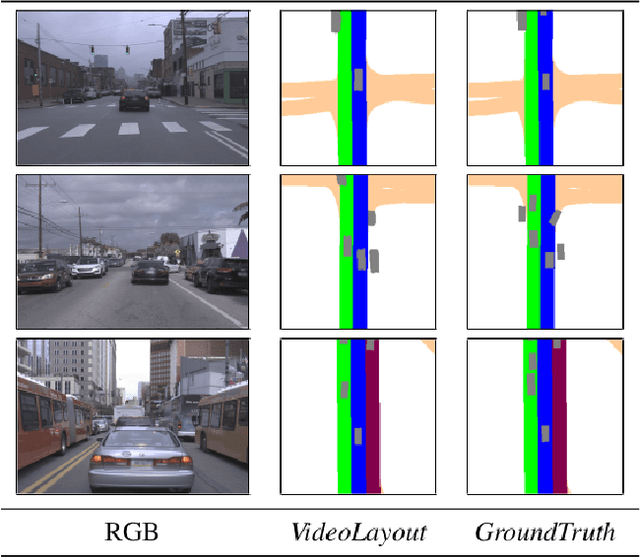
Given an image or a video captured from a monocular camera, amodal layout estimation is the task of predicting semantics and occupancy in bird's eye view. The term amodal implies we also reason about entities in the scene that are occluded or truncated in image space. While several recent efforts have tackled this problem, there is a lack of standardization in task specification, datasets, and evaluation protocols. We address these gaps with AutoLay, a dataset and benchmark for amodal layout estimation from monocular images. AutoLay encompasses driving imagery from two popular datasets: KITTI and Argoverse. In addition to fine-grained attributes such as lanes, sidewalks, and vehicles, we also provide semantically annotated 3D point clouds. We implement several baselines and bleeding edge approaches, and release our data and code.
MonoLayout: Amodal scene layout from a single image
Feb 19, 2020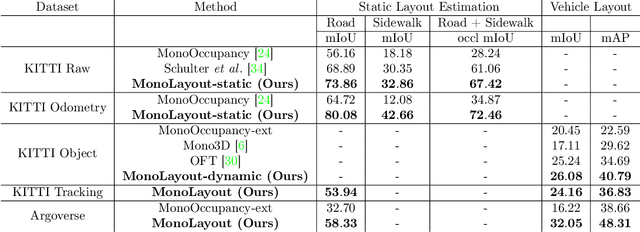
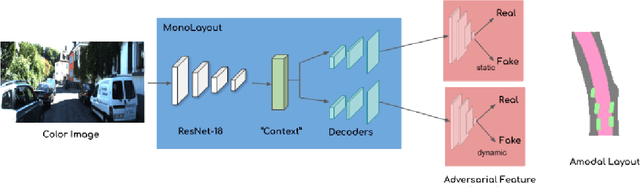
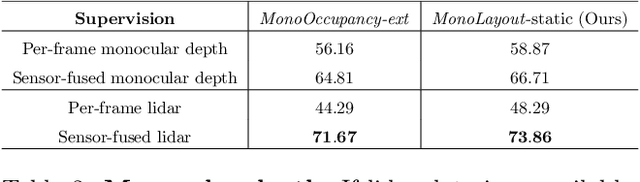
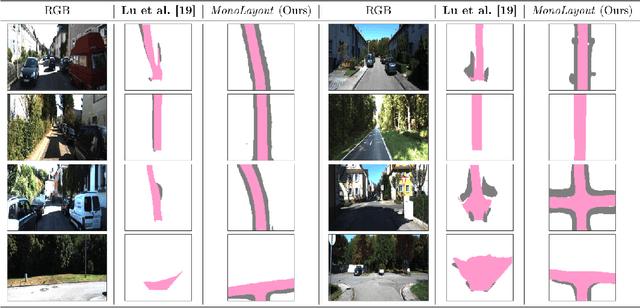
In this paper, we address the novel, highly challenging problem of estimating the layout of a complex urban driving scenario. Given a single color image captured from a driving platform, we aim to predict the bird's-eye view layout of the road and other traffic participants. The estimated layout should reason beyond what is visible in the image, and compensate for the loss of 3D information due to projection. We dub this problem amodal scene layout estimation, which involves "hallucinating" scene layout for even parts of the world that are occluded in the image. To this end, we present MonoLayout, a deep neural network for real-time amodal scene layout estimation from a single image. We represent scene layout as a multi-channel semantic occupancy grid, and leverage adversarial feature learning to hallucinate plausible completions for occluded image parts. Due to the lack of fair baseline methods, we extend several state-of-the-art approaches for road-layout estimation and vehicle occupancy estimation in bird's-eye view to the amodal setup for rigorous evaluation. By leveraging temporal sensor fusion to generate training labels, we significantly outperform current art over a number of datasets. On the KITTI and Argoverse datasets, we outperform all baselines by a significant margin. We also make all our annotations, and code publicly available. A video abstract of this paper is available https://www.youtube.com/watch?v=HcroGyo6yRQ .
Multi-Document Summarization using Distributed Bag-of-Words Model
Jun 11, 2018



As the number of documents on the web is growing exponentially, multi-document summarization is becoming more and more important since it can provide the main ideas in a document set in short time. In this paper, we present an unsupervised centroid-based document-level reconstruction framework using distributed bag of words model. Specifically, our approach selects summary sentences in order to minimize the reconstruction error between the summary and the documents. We apply sentence selection and beam search, to further improve the performance of our model. Experimental results on two different datasets show significant performance gains compared with the state-of-the-art baselines.
BASS Net: Band-Adaptive Spectral-Spatial Feature Learning Neural Network for Hyperspectral Image Classification
Dec 02, 2016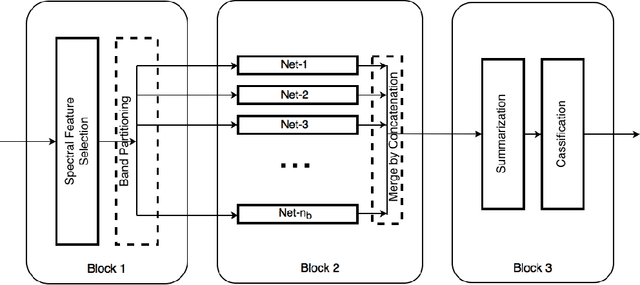
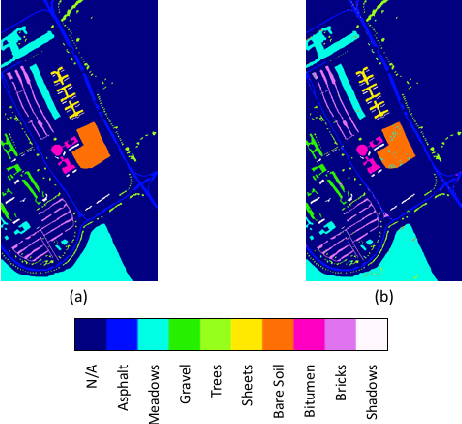
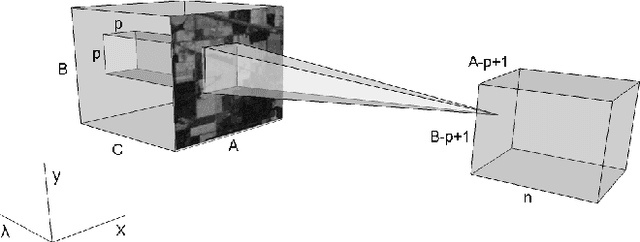
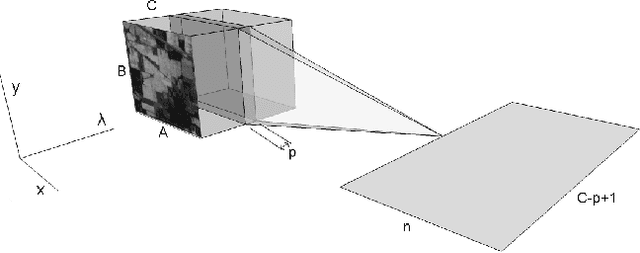
Deep learning based landcover classification algorithms have recently been proposed in literature. In hyperspectral images (HSI) they face the challenges of large dimensionality, spatial variability of spectral signatures and scarcity of labeled data. In this article we propose an end-to-end deep learning architecture that extracts band specific spectral-spatial features and performs landcover classification. The architecture has fewer independent connection weights and thus requires lesser number of training data. The method is found to outperform the highest reported accuracies on popular hyperspectral image data sets.