 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Representations for Safer Policy Learning
Feb 27, 2025



Reinforcement learning algorithms typically necessitate extensive exploration of the state space to find optimal policies. However, in safety-critical applications, the risks associated with such exploration can lead to catastrophic consequences. Existing safe exploration methods attempt to mitigate this by imposing constraints, which often result in overly conservative behaviours and inefficient learning. Heavy penalties for early constraint violations can trap agents in local optima, deterring exploration of risky yet high-reward regions of the state space. To address this, we introduce a method that explicitly learns state-conditioned safety representations. By augmenting the state features with these safety representations, our approach naturally encourages safer exploration without being excessively cautious, resulting in more efficient and safer policy learning in safety-critical scenarios. Empirical evaluations across diverse environments show that our method significantly improves task performance while reducing constraint violations during training, underscoring its effectiveness in balancing exploration with safety.
Accelerating Quasi-Static Time Series Simulations with Foundation Models
Nov 13, 2024Quasi-static time series (QSTS) simulations have great potential for evaluating the grid's ability to accommodate the large-scale integration of distributed energy resources. However, as grids expand and operate closer to their limits, iterative power flow solvers, central to QSTS simulations, become computationally prohibitive and face increasing convergence issues. Neural power flow solvers provide a promising alternative, speeding up power flow computations by 3 to 4 orders of magnitude, though they are costly to train. In this paper, we envision how recently introduced grid foundation models could improve the economic viability of neural power flow solvers. Conceptually, these models amortize training costs by serving as a foundation for a range of grid operation and planning tasks beyond power flow solving, with only minimal fine-tuning required. We call for collaboration between the AI and power grid communities to develop and open-source these models, enabling all operators, even those with limited resources, to benefit from AI without building solutions from scratch.
A Perspective on Foundation Models for the Electric Power Grid
Jul 12, 2024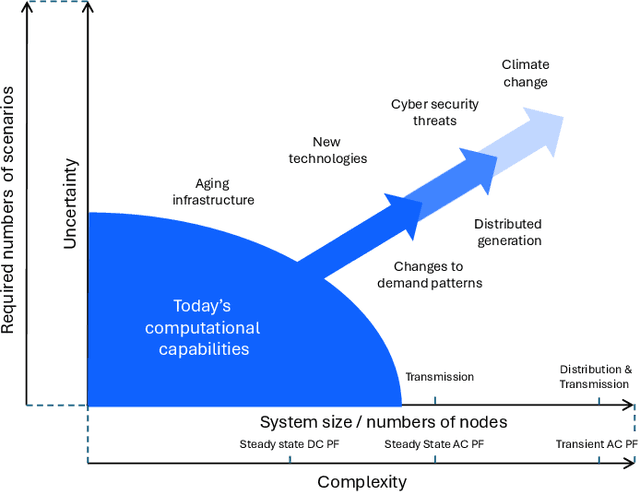
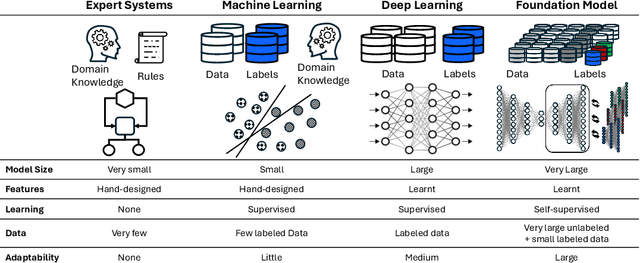
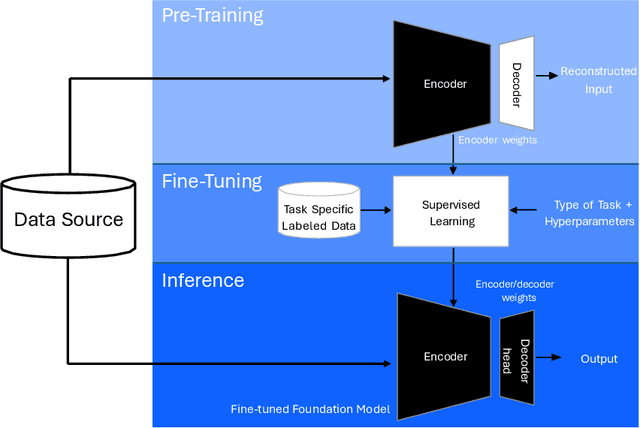
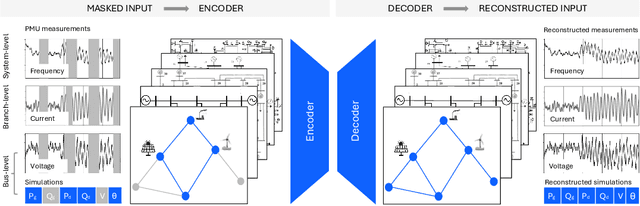
Foundation models (FMs) currently dominate news headlines. They employ advanced deep learning architectures to extract structural information autonomously from vast datasets through self-supervision. The resulting rich representations of complex systems and dynamics can be applied to many downstream applications. Therefore, FMs can find uses in electric power grids, challenged by the energy transition and climate change. In this paper, we call for the development of, and state why we believe in, the potential of FMs for electric grids. We highlight their strengths and weaknesses amidst the challenges of a changing grid. We argue that an FM learning from diverse grid data and topologies could unlock transformative capabilities, pioneering a new approach in leveraging AI to redefine how we manage complexity and uncertainty in the electric grid. Finally, we discuss a power grid FM concept, namely GridFM, based on graph neural networks and show how different downstream tasks benefit.
Multi-Agent Reinforcement Learning for Fast-Timescale Demand Response of Residential Loads
Jan 06, 2023To integrate high amounts of renewable energy resources, electrical power grids must be able to cope with high amplitude, fast timescale variations in power generation. Frequency regulation through demand response has the potential to coordinate temporally flexible loads, such as air conditioners, to counteract these variations. Existing approaches for discrete control with dynamic constraints struggle to provide satisfactory performance for fast timescale action selection with hundreds of agents. We propose a decentralized agent trained with multi-agent proximal policy optimization with localized communication. We explore two communication frameworks: hand-engineered, or learned through targeted multi-agent communication. The resulting policies perform well and robustly for frequency regulation, and scale seamlessly to arbitrary numbers of houses for constant processing times.
Sample Efficient Deep Reinforcement Learning via Uncertainty Estimation
Jan 05, 2022
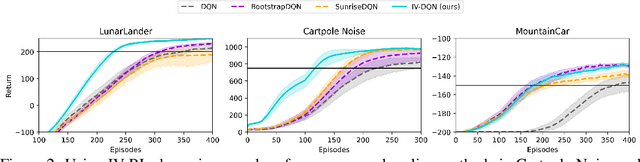
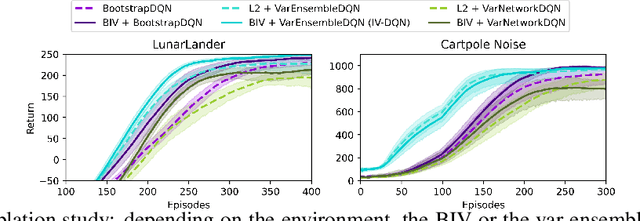
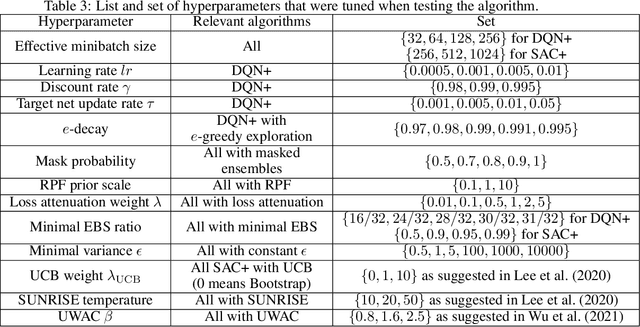
In model-free deep reinforcement learning (RL) algorithms, using noisy value estimates to supervise policy evaluation and optimization is detrimental to the sample efficiency. As this noise is heteroscedastic, its effects can be mitigated using uncertainty-based weights in the optimization process. Previous methods rely on sampled ensembles, which do not capture all aspects of uncertainty. We provide a systematic analysis of the sources of uncertainty in the noisy supervision that occurs in RL, and introduce inverse-variance RL, a Bayesian framework which combines probabilistic ensembles and Batch Inverse Variance weighting. We propose a method whereby two complementary uncertainty estimation methods account for both the Q-value and the environment stochasticity to better mitigate the negative impacts of noisy supervision. Our results show significant improvement in terms of sample efficiency on discrete and continuous control tasks.
Batch Inverse-Variance Weighting: Deep Heteroscedastic Regression
Jul 09, 2021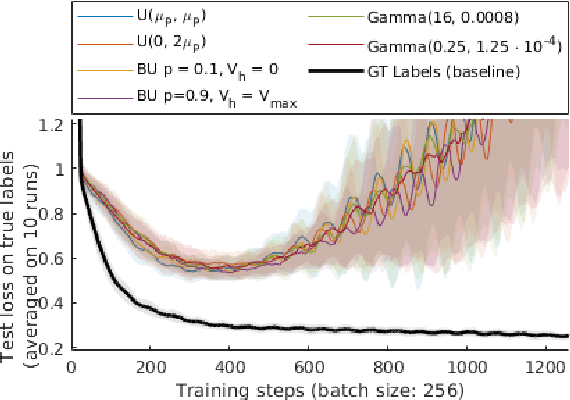
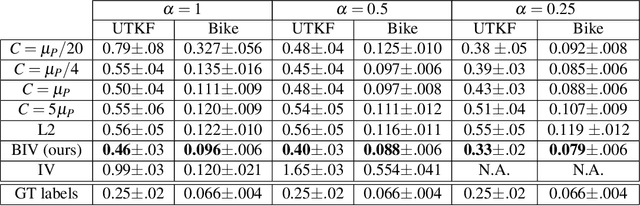
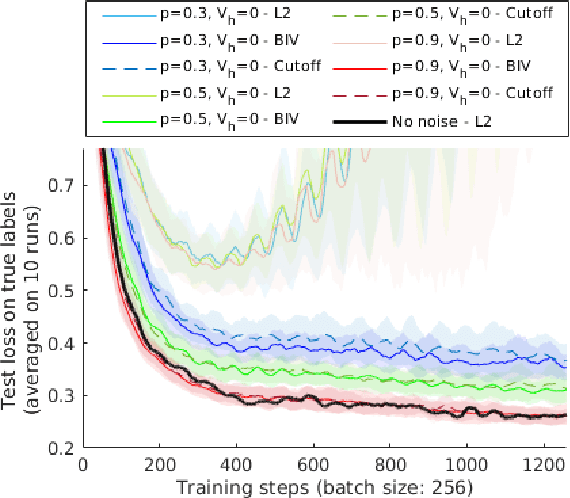
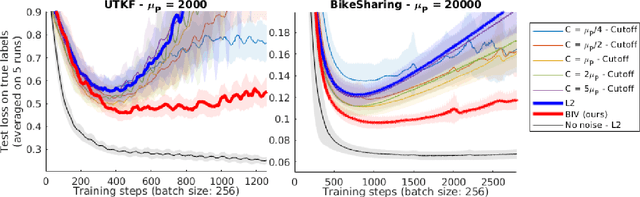
Heteroscedastic regression is the task of supervised learning where each label is subject to noise from a different distribution. This noise can be caused by the labelling process, and impacts negatively the performance of the learning algorithm as it violates the i.i.d. assumptions. In many situations however, the labelling process is able to estimate the variance of such distribution for each label, which can be used as an additional information to mitigate this impact. We adapt an inverse-variance weighted mean square error, based on the Gauss-Markov theorem, for parameter optimization on neural networks. We introduce Batch Inverse-Variance, a loss function which is robust to near-ground truth samples, and allows to control the effective learning rate. Our experimental results show that BIV improves significantly the performance of the networks on two noisy datasets, compared to L2 loss, inverse-variance weighting, as well as a filtering-based baseline.
Deep Active Localization
Mar 05, 2019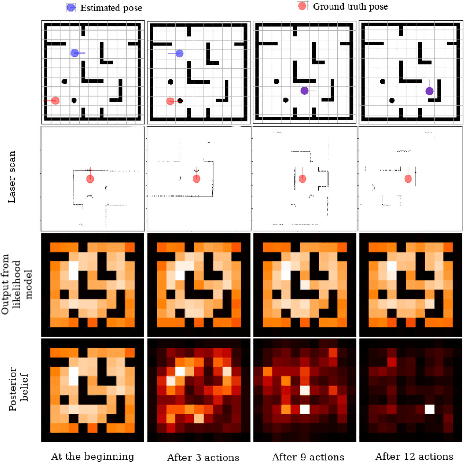
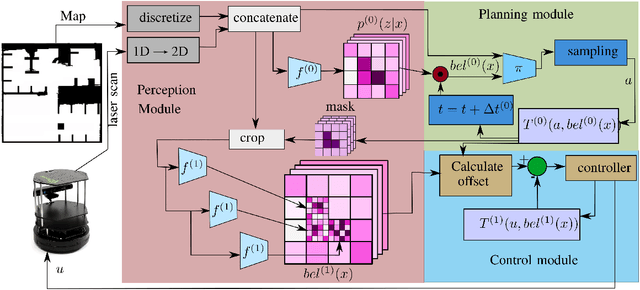
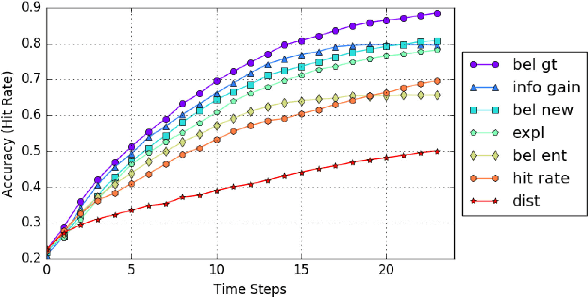
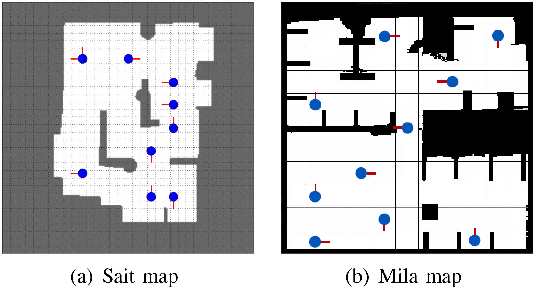
Active localization is the problem of generating robot actions that allow it to maximally disambiguate its pose within a reference map. Traditional approaches to this use an information-theoretic criterion for action selection and hand-crafted perceptual models. In this work we propose an end-to-end differentiable method for learning to take informative actions that is trainable entirely in simulation and then transferable to real robot hardware with zero refinement. The system is composed of two modules: a convolutional neural network for perception, and a deep reinforcement learned planning module. We introduce a multi-scale approach to the learned perceptual model since the accuracy needed to perform action selection with reinforcement learning is much less than the accuracy needed for robot control. We demonstrate that the resulting system outperforms using the traditional approach for either perception or planning. We also demonstrate our approaches robustness to different map configurations and other nuisance parameters through the use of domain randomization in training. The code is also compatible with the OpenAI gym framework, as well as the Gazebo simulator.