 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBirdSLAM: Monocular Multibody SLAM in Bird's-Eye View
Nov 15, 2020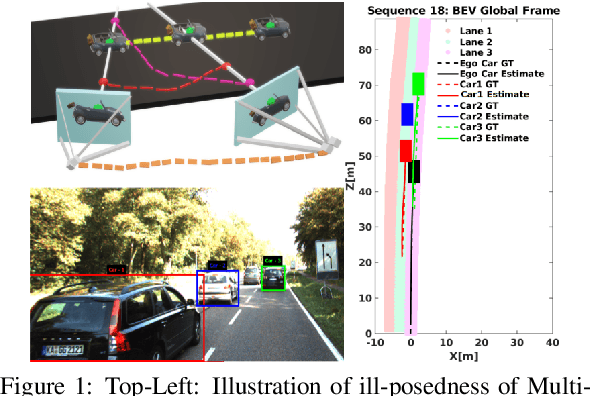
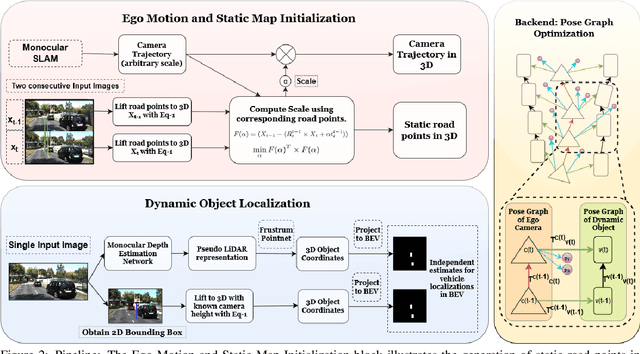
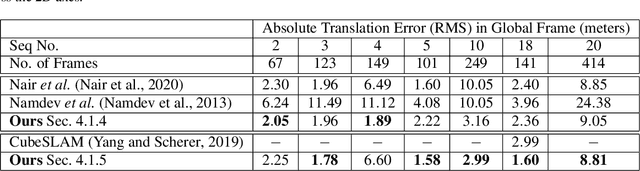
In this paper, we present BirdSLAM, a novel simultaneous localization and mapping (SLAM) system for the challenging scenario of autonomous driving platforms equipped with only a monocular camera. BirdSLAM tackles challenges faced by other monocular SLAM systems (such as scale ambiguity in monocular reconstruction, dynamic object localization, and uncertainty in feature representation) by using an orthographic (bird's-eye) view as the configuration space in which localization and mapping are performed. By assuming only the height of the ego-camera above the ground, BirdSLAM leverages single-view metrology cues to accurately localize the ego-vehicle and all other traffic participants in bird's-eye view. We demonstrate that our system outperforms prior work that uses strictly greater information, and highlight the relevance of each design decision via an ablation analysis.
MonoLayout: Amodal scene layout from a single image
Feb 19, 2020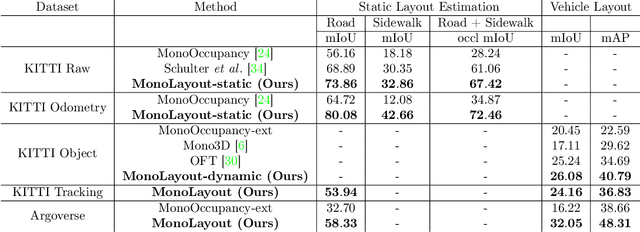
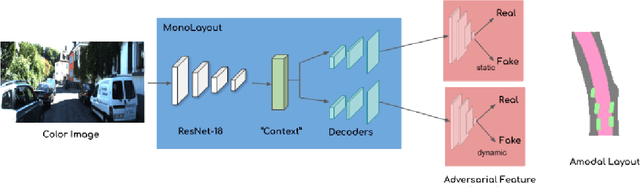
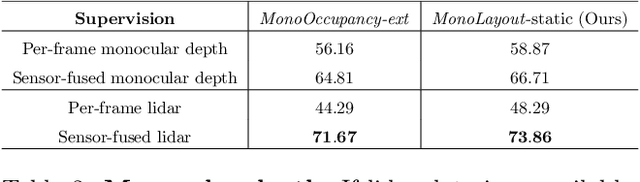
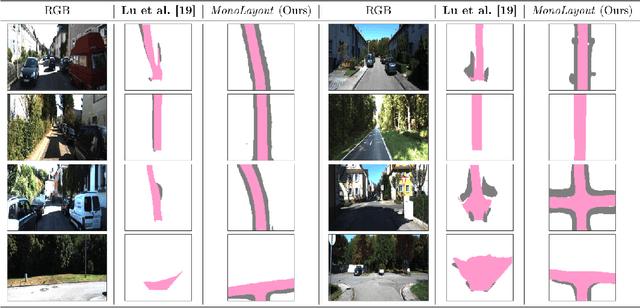
In this paper, we address the novel, highly challenging problem of estimating the layout of a complex urban driving scenario. Given a single color image captured from a driving platform, we aim to predict the bird's-eye view layout of the road and other traffic participants. The estimated layout should reason beyond what is visible in the image, and compensate for the loss of 3D information due to projection. We dub this problem amodal scene layout estimation, which involves "hallucinating" scene layout for even parts of the world that are occluded in the image. To this end, we present MonoLayout, a deep neural network for real-time amodal scene layout estimation from a single image. We represent scene layout as a multi-channel semantic occupancy grid, and leverage adversarial feature learning to hallucinate plausible completions for occluded image parts. Due to the lack of fair baseline methods, we extend several state-of-the-art approaches for road-layout estimation and vehicle occupancy estimation in bird's-eye view to the amodal setup for rigorous evaluation. By leveraging temporal sensor fusion to generate training labels, we significantly outperform current art over a number of datasets. On the KITTI and Argoverse datasets, we outperform all baselines by a significant margin. We also make all our annotations, and code publicly available. A video abstract of this paper is available https://www.youtube.com/watch?v=HcroGyo6yRQ .
Multi-object Monocular SLAM for Dynamic Environments
Feb 10, 2020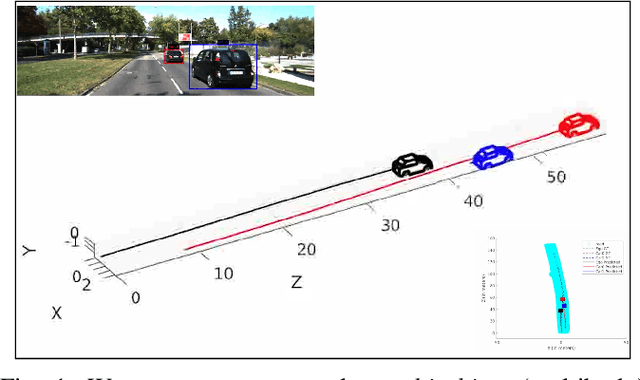
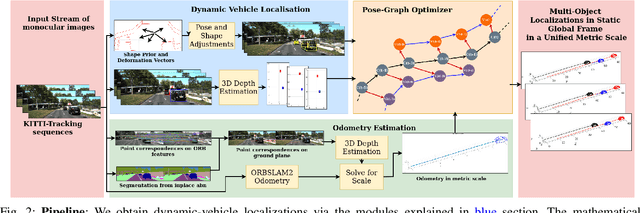
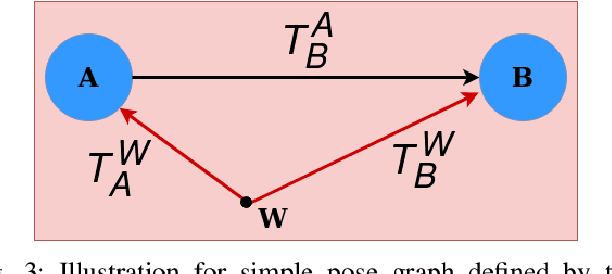
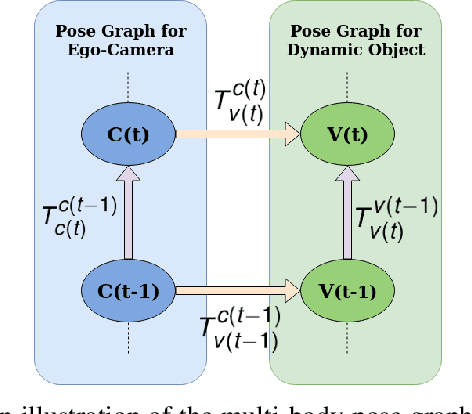
Multibody monocular SLAM in dynamic environments remains a long-standing challenge in terms of perception and state estimation. Although theoretical solutions exist, practice lags behind, predominantly due to the lack of robust perceptual and predictive models of dynamic participants. The quintessential challenge in Multi-body monocular SLAM in dynamic scenes stems from the problem of unobservability as it is not possible to triangulate a moving object from a moving monocular camera. Under restrictions of object motion the problem can be solved, however even here one is entailed to solve for the single family solution to the relative scale problem. The relative scale problem exists since the dynamic objects that get reconstructed with the monocular camera have a different scale vis a vis the scale space in which the stationary scene is reconstructed. We solve this rather intractable problem by reconstructing dynamic vehicles/participants in single view in metric scale through an object SLAM pipeline. Further, we lift the ego vehicle trajectory obtained from Monocular ORB-SLAM also into metric scales making use of ground plane features thereby resolving the relative scale problem. We present a multi pose-graph optimization formulation to estimate the pose and track dynamic objects in the environment. This optimization helps us reduce the average error in trajectories of multiple bodies in KITTI Tracking sequences. To the best of our knowledge, our method is the first practical monocular multi-body SLAM system to perform dynamic multi-object and ego localization in a unified framework in metric scale.
Learning to Prevent Monocular SLAM Failure using Reinforcement Learning
Dec 23, 2018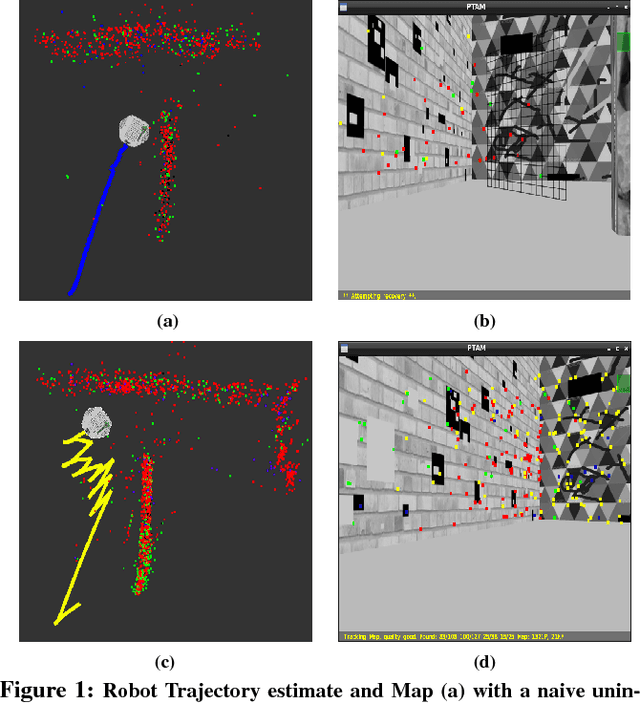

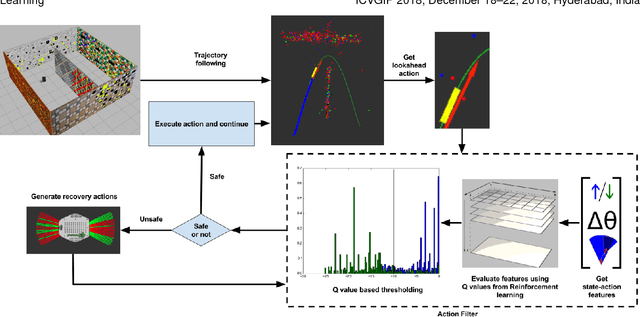
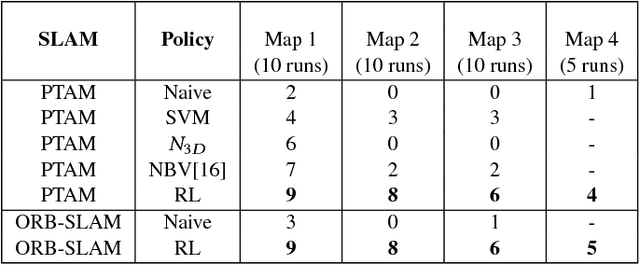
Monocular SLAM refers to using a single camera to estimate robot ego motion while building a map of the environment. While Monocular SLAM is a well studied problem, automating Monocular SLAM by integrating it with trajectory planning frameworks is particularly challenging. This paper presents a novel formulation based on Reinforcement Learning (RL) that generates fail safe trajectories wherein the SLAM generated outputs do not deviate largely from their true values. Quintessentially, the RL framework successfully learns the otherwise complex relation between perceptual inputs and motor actions and uses this knowledge to generate trajectories that do not cause failure of SLAM. We show systematically in simulations how the quality of the SLAM dramatically improves when trajectories are computed using RL. Our method scales effectively across Monocular SLAM frameworks in both simulation and in real world experiments with a mobile robot.