 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMessyKitchens: Contact-rich object-level 3D scene reconstruction
Mar 17, 2026Monocular 3D scene reconstruction has recently seen significant progress. Powered by the modern neural architectures and large-scale data, recent methods achieve high performance in depth estimation from a single image. Meanwhile, reconstructing and decomposing common scenes into individual 3D objects remains a hard challenge due to the large variety of objects, frequent occlusions and complex object relations. Notably, beyond shape and pose estimation of individual objects, applications in robotics and animation require physically-plausible scene reconstruction where objects obey physical principles of non-penetration and realistic contacts. In this work we advance object-level scene reconstruction along two directions. First, we introduceMessyKitchens, a new dataset with real-world scenes featuring cluttered environments and providing high-fidelity object-level ground truth in terms of 3D object shapes, poses and accurate object contacts. Second, we build on the recent SAM 3D approach for single-object reconstruction and extend it with Multi-Object Decoder (MOD) for joint object-level scene reconstruction. To validate our contributions, we demonstrate MessyKitchens to significantly improve previous datasets in registration accuracy and inter-object penetration. We also compare our multi-object reconstruction approach on three datasets and demonstrate consistent and significant improvements of MOD over the state of the art. Our new benchmark, code and pre-trained models will become publicly available on our project website: https://messykitchens.github.io/.
Exploring Social Motion Latent Space and Human Awareness for Effective Robot Navigation in Crowded Environments
Oct 11, 2023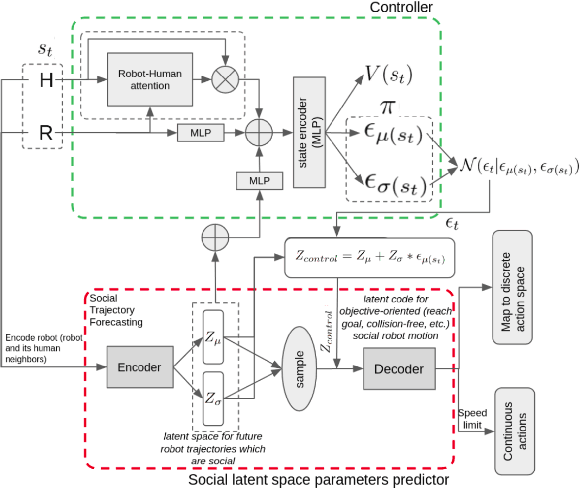
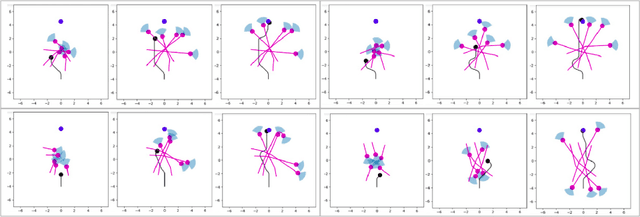
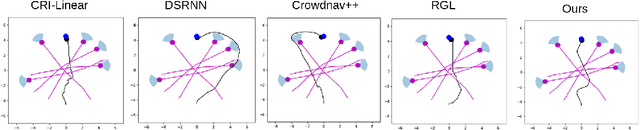
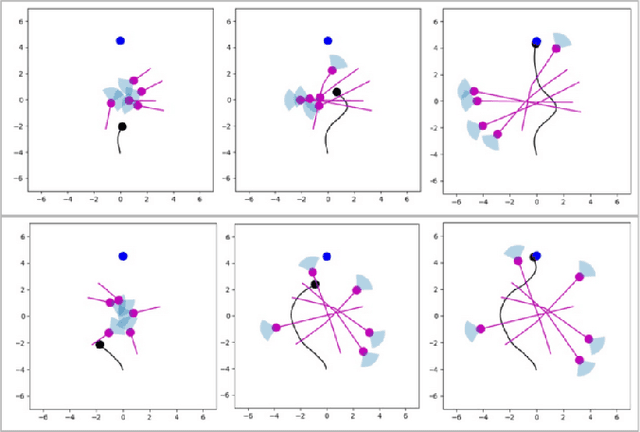
This work proposes a novel approach to social robot navigation by learning to generate robot controls from a social motion latent space. By leveraging this social motion latent space, the proposed method achieves significant improvements in social navigation metrics such as success rate, navigation time, and trajectory length while producing smoother (less jerk and angular deviations) and more anticipatory trajectories. The superiority of the proposed method is demonstrated through comparison with baseline models in various scenarios. Additionally, the concept of humans' awareness towards the robot is introduced into the social robot navigation framework, showing that incorporating human awareness leads to shorter and smoother trajectories owing to humans' ability to positively interact with the robot.
BirdSLAM: Monocular Multibody SLAM in Bird's-Eye View
Nov 15, 2020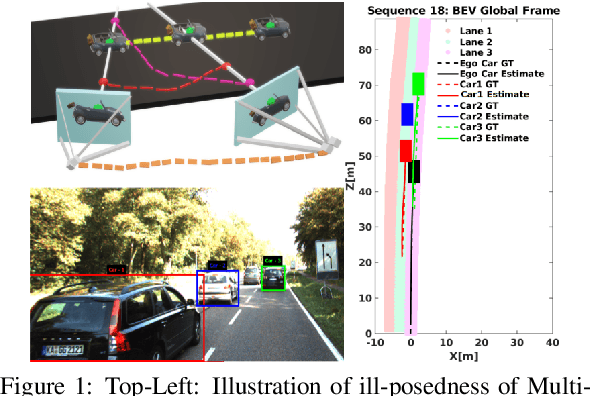
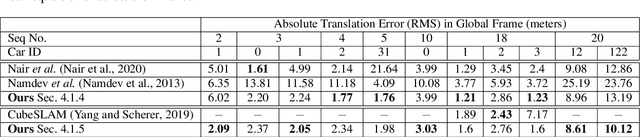
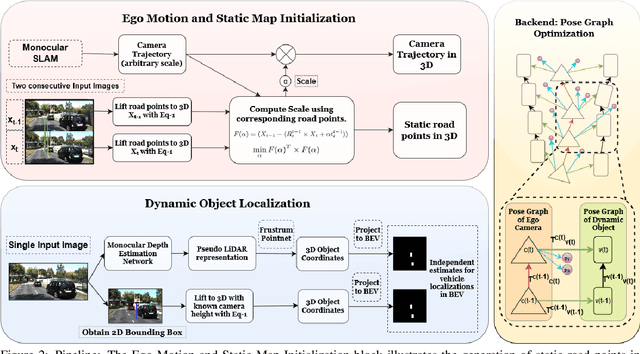
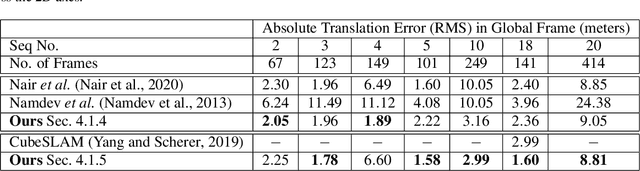
In this paper, we present BirdSLAM, a novel simultaneous localization and mapping (SLAM) system for the challenging scenario of autonomous driving platforms equipped with only a monocular camera. BirdSLAM tackles challenges faced by other monocular SLAM systems (such as scale ambiguity in monocular reconstruction, dynamic object localization, and uncertainty in feature representation) by using an orthographic (bird's-eye) view as the configuration space in which localization and mapping are performed. By assuming only the height of the ego-camera above the ground, BirdSLAM leverages single-view metrology cues to accurately localize the ego-vehicle and all other traffic participants in bird's-eye view. We demonstrate that our system outperforms prior work that uses strictly greater information, and highlight the relevance of each design decision via an ablation analysis.
Simple means Faster: Real-Time Human Motion Forecasting in Monocular First Person Videos on CPU
Nov 10, 2020
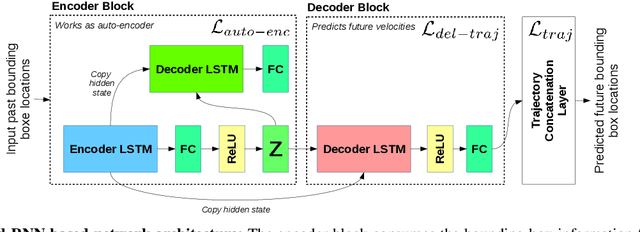

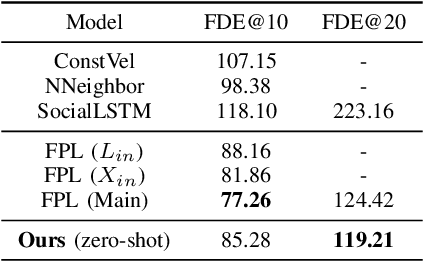
We present a simple, fast, and light-weight RNN based framework for forecasting future locations of humans in first person monocular videos. The primary motivation for this work was to design a network which could accurately predict future trajectories at a very high rate on a CPU. Typical applications of such a system would be a social robot or a visual assistance system for all, as both cannot afford to have high compute power to avoid getting heavier, less power efficient, and costlier. In contrast to many previous methods which rely on multiple type of cues such as camera ego-motion or 2D pose of the human, we show that a carefully designed network model which relies solely on bounding boxes can not only perform better but also predicts trajectories at a very high rate while being quite low in size of approximately 17 MB. Specifically, we demonstrate that having an auto-encoder in the encoding phase of the past information and a regularizing layer in the end boosts the accuracy of predictions with negligible overhead. We experiment with three first person video datasets: CityWalks, FPL and JAAD. Our simple method trained on CityWalks surpasses the prediction accuracy of state-of-the-art method (STED) while being 9.6x faster on a CPU (STED runs on a GPU). We also demonstrate that our model can transfer zero-shot or after just 15% fine-tuning to other similar datasets and perform on par with the state-of-the-art methods on such datasets (FPL and DTP). To the best of our knowledge, we are the first to accurately forecast trajectories at a very high prediction rate of 78 trajectories per second on CPU.
Multi-object Monocular SLAM for Dynamic Environments
Feb 10, 2020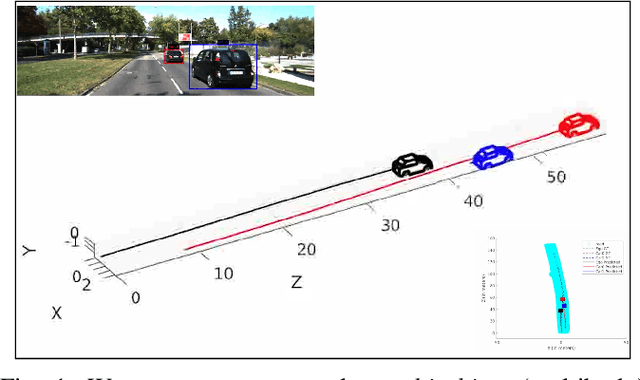
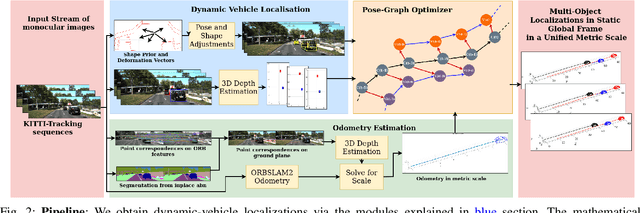
Multibody monocular SLAM in dynamic environments remains a long-standing challenge in terms of perception and state estimation. Although theoretical solutions exist, practice lags behind, predominantly due to the lack of robust perceptual and predictive models of dynamic participants. The quintessential challenge in Multi-body monocular SLAM in dynamic scenes stems from the problem of unobservability as it is not possible to triangulate a moving object from a moving monocular camera. Under restrictions of object motion the problem can be solved, however even here one is entailed to solve for the single family solution to the relative scale problem. The relative scale problem exists since the dynamic objects that get reconstructed with the monocular camera have a different scale vis a vis the scale space in which the stationary scene is reconstructed. We solve this rather intractable problem by reconstructing dynamic vehicles/participants in single view in metric scale through an object SLAM pipeline. Further, we lift the ego vehicle trajectory obtained from Monocular ORB-SLAM also into metric scales making use of ground plane features thereby resolving the relative scale problem. We present a multi pose-graph optimization formulation to estimate the pose and track dynamic objects in the environment. This optimization helps us reduce the average error in trajectories of multiple bodies in KITTI Tracking sequences. To the best of our knowledge, our method is the first practical monocular multi-body SLAM system to perform dynamic multi-object and ego localization in a unified framework in metric scale.
INFER: INtermediate representations for FuturE pRediction
Mar 26, 2019
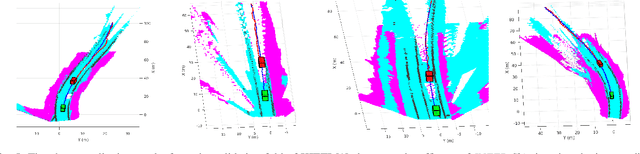
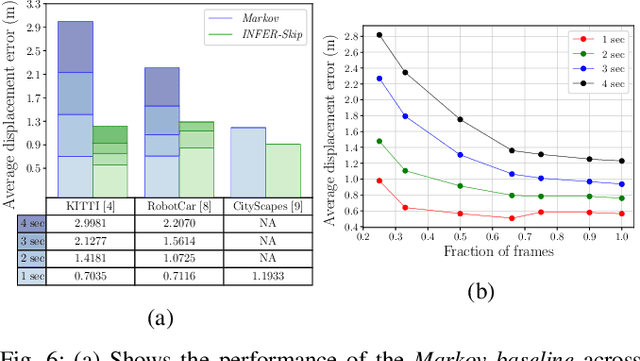
In urban driving scenarios, forecasting future trajectories of surrounding vehicles is of paramount importance. While several approaches for the problem have been proposed, the best-performing ones tend to require extremely detailed input representations (eg. image sequences). But, such methods do not generalize to datasets they have not been trained on. We propose intermediate representations that are particularly well-suited for future prediction. As opposed to using texture (color) information, we rely on semantics and train an autoregressive model to accurately predict future trajectories of traffic participants (vehicles) (see fig. above). We demonstrate that using semantics provides a significant boost over techniques that operate over raw pixel intensities/disparities. Uncharacteristic of state-of-the-art approaches, our representations and models generalize to completely different datasets, collected across several cities, and also across countries where people drive on opposite sides of the road (left-handed vs right-handed driving). Additionally, we demonstrate an application of our approach in multi-object tracking (data association). To foster further research in transferrable representations and ensure reproducibility, we release all our code and data.
Beyond Pixels: Leveraging Geometry and Shape Cues for Online Multi-Object Tracking
Jul 27, 2018
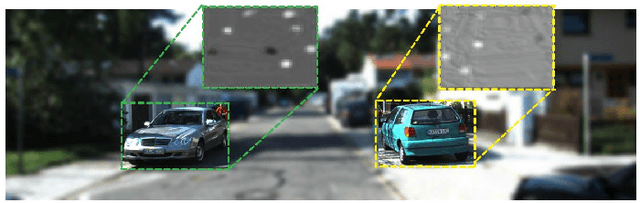
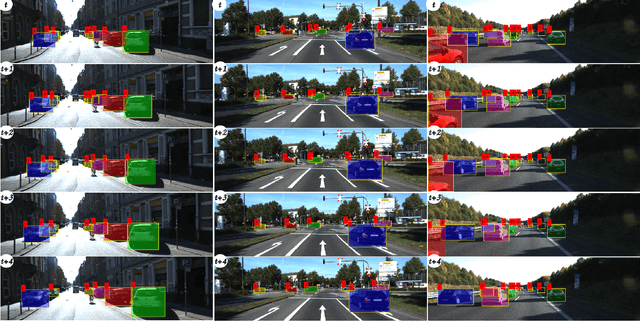

This paper introduces geometry and object shape and pose costs for multi-object tracking in urban driving scenarios. Using images from a monocular camera alone, we devise pairwise costs for object tracks, based on several 3D cues such as object pose, shape, and motion. The proposed costs are agnostic to the data association method and can be incorporated into any optimization framework to output the pairwise data associations. These costs are easy to implement, can be computed in real-time, and complement each other to account for possible errors in a tracking-by-detection framework. We perform an extensive analysis of the designed costs and empirically demonstrate consistent improvement over the state-of-the-art under varying conditions that employ a range of object detectors, exhibit a variety in camera and object motions, and, more importantly, are not reliant on the choice of the association framework. We also show that, by using the simplest of associations frameworks (two-frame Hungarian assignment), we surpass the state-of-the-art in multi-object-tracking on road scenes. More qualitative and quantitative results can be found at the following URL: https://junaidcs032.github.io/Geometry_ObjectShape_MOT/.
The Earth ain't Flat: Monocular Reconstruction of Vehicles on Steep and Graded Roads from a Moving Camera
Mar 06, 2018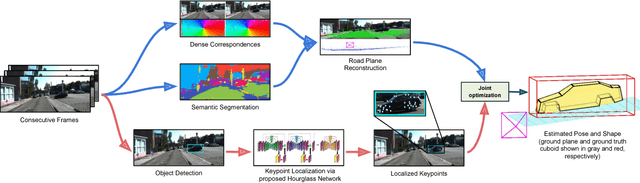
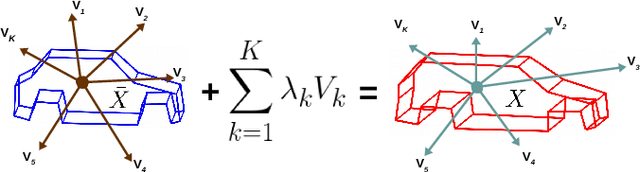

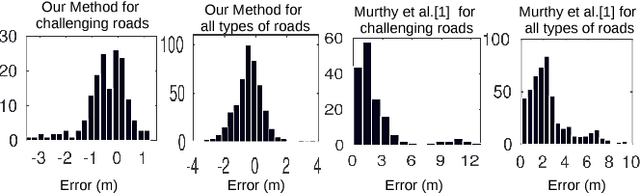
Accurate localization of other traffic participants is a vital task in autonomous driving systems. State-of-the-art systems employ a combination of sensing modalities such as RGB cameras and LiDARs for localizing traffic participants, but most such demonstrations have been confined to plain roads. We demonstrate, to the best of our knowledge, the first results for monocular object localization and shape estimation on surfaces that do not share the same plane with the moving monocular camera. We approximate road surfaces by local planar patches and use semantic cues from vehicles in the scene to initialize a local bundle-adjustment like procedure that simultaneously estimates the pose and shape of the vehicles, and the orientation of the local ground plane on which the vehicle stands as well. We evaluate the proposed approach on the KITTI and SYNTHIA-SF benchmarks, for a variety of road plane configurations. The proposed approach significantly improves the state-of-the-art for monocular object localization on arbitrarily-shaped roads.