 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple means Faster: Real-Time Human Motion Forecasting in Monocular First Person Videos on CPU
Paper and Code
Nov 10, 2020
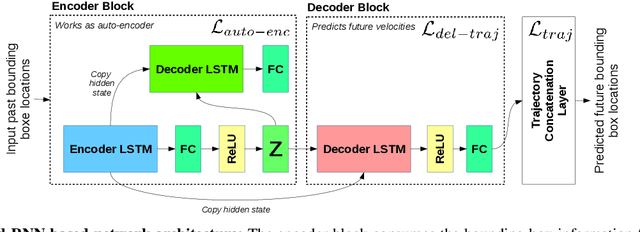

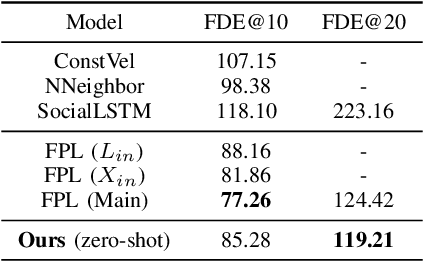
We present a simple, fast, and light-weight RNN based framework for forecasting future locations of humans in first person monocular videos. The primary motivation for this work was to design a network which could accurately predict future trajectories at a very high rate on a CPU. Typical applications of such a system would be a social robot or a visual assistance system for all, as both cannot afford to have high compute power to avoid getting heavier, less power efficient, and costlier. In contrast to many previous methods which rely on multiple type of cues such as camera ego-motion or 2D pose of the human, we show that a carefully designed network model which relies solely on bounding boxes can not only perform better but also predicts trajectories at a very high rate while being quite low in size of approximately 17 MB. Specifically, we demonstrate that having an auto-encoder in the encoding phase of the past information and a regularizing layer in the end boosts the accuracy of predictions with negligible overhead. We experiment with three first person video datasets: CityWalks, FPL and JAAD. Our simple method trained on CityWalks surpasses the prediction accuracy of state-of-the-art method (STED) while being 9.6x faster on a CPU (STED runs on a GPU). We also demonstrate that our model can transfer zero-shot or after just 15% fine-tuning to other similar datasets and perform on par with the state-of-the-art methods on such datasets (FPL and DTP). To the best of our knowledge, we are the first to accurately forecast trajectories at a very high prediction rate of 78 trajectories per second on CPU.