 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMPCVS: Deep Model Predictive Control for Visual Servoing
May 03, 2021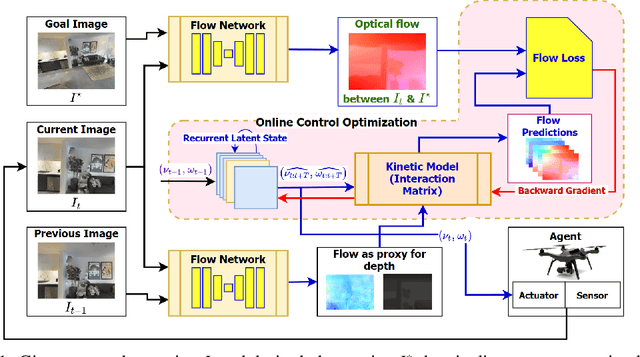
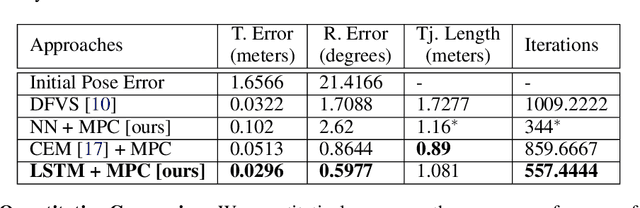

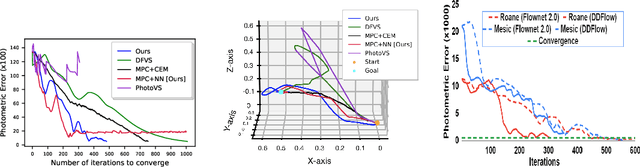
The simplicity of the visual servoing approach makes it an attractive option for tasks dealing with vision-based control of robots in many real-world applications. However, attaining precise alignment for unseen environments pose a challenge to existing visual servoing approaches. While classical approaches assume a perfect world, the recent data-driven approaches face issues when generalizing to novel environments. In this paper, we aim to combine the best of both worlds. We present a deep model predictive visual servoing framework that can achieve precise alignment with optimal trajectories and can generalize to novel environments. Our framework consists of a deep network for optical flow predictions, which are used along with a predictive model to forecast future optical flow. For generating an optimal set of velocities we present a control network that can be trained on the fly without any supervision. Through extensive simulations on photo-realistic indoor settings of the popular Habitat framework, we show significant performance gain due to the proposed formulation vis-a-vis recent state-of-the-art methods. Specifically, we show a faster convergence and an improved performance in trajectory length over recent approaches.
* Accepted at 4th Annual Conference on Robot Learning, CoRL 2020, Cambridge, MA, USA, November 16 - November 18, 2020
INFER: INtermediate representations for FuturE pRediction
Mar 26, 2019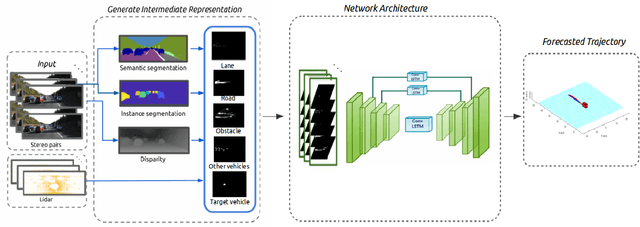
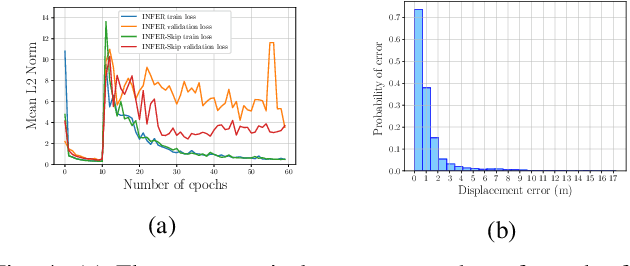
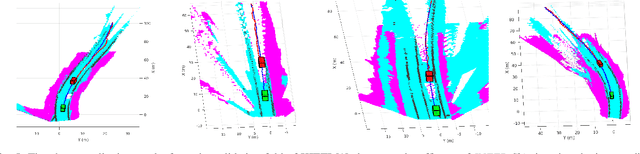
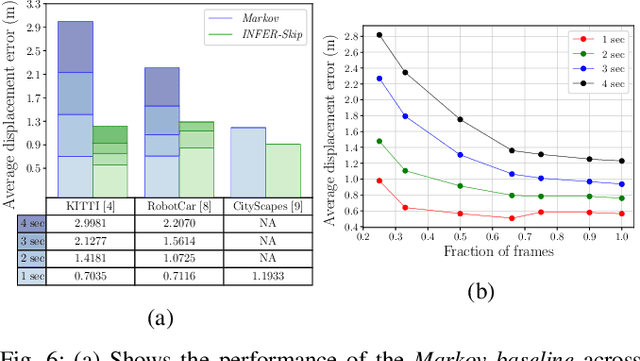
In urban driving scenarios, forecasting future trajectories of surrounding vehicles is of paramount importance. While several approaches for the problem have been proposed, the best-performing ones tend to require extremely detailed input representations (eg. image sequences). But, such methods do not generalize to datasets they have not been trained on. We propose intermediate representations that are particularly well-suited for future prediction. As opposed to using texture (color) information, we rely on semantics and train an autoregressive model to accurately predict future trajectories of traffic participants (vehicles) (see fig. above). We demonstrate that using semantics provides a significant boost over techniques that operate over raw pixel intensities/disparities. Uncharacteristic of state-of-the-art approaches, our representations and models generalize to completely different datasets, collected across several cities, and also across countries where people drive on opposite sides of the road (left-handed vs right-handed driving). Additionally, we demonstrate an application of our approach in multi-object tracking (data association). To foster further research in transferrable representations and ensure reproducibility, we release all our code and data.