 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
Sep 17, 2025
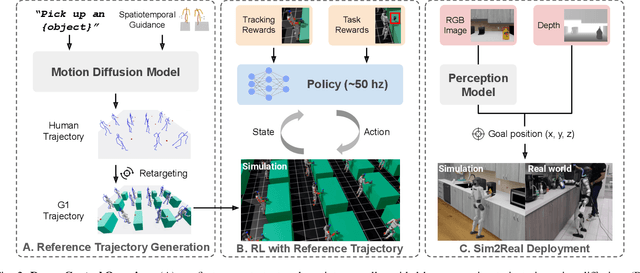

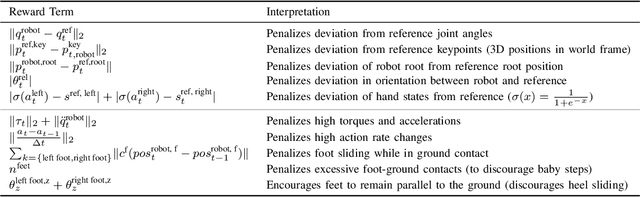
We introduce DreamControl, a novel methodology for learning autonomous whole-body humanoid skills. DreamControl leverages the strengths of diffusion models and Reinforcement Learning (RL): our core innovation is the use of a diffusion prior trained on human motion data, which subsequently guides an RL policy in simulation to complete specific tasks of interest (e.g., opening a drawer or picking up an object). We demonstrate that this human motion-informed prior allows RL to discover solutions unattainable by direct RL, and that diffusion models inherently promote natural looking motions, aiding in sim-to-real transfer. We validate DreamControl's effectiveness on a Unitree G1 robot across a diverse set of challenging tasks involving simultaneous lower and upper body control and object interaction.
ODIN: A Single Model for 2D and 3D Perception
Jan 04, 2024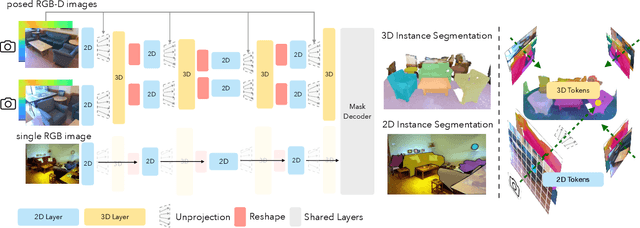
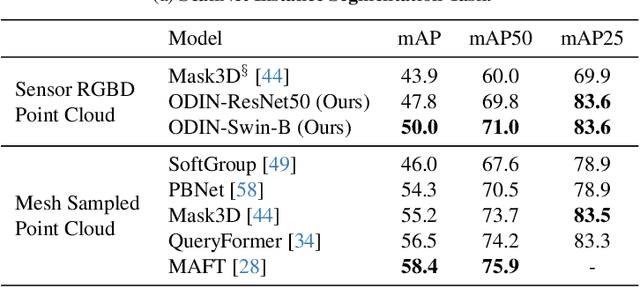
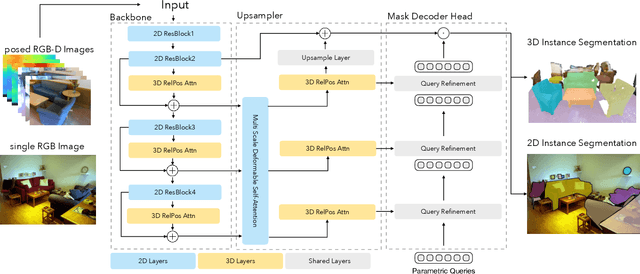
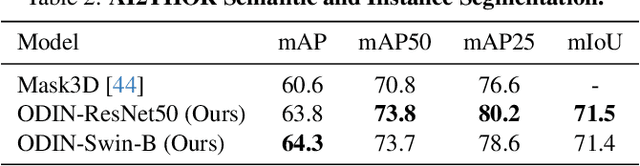
State-of-the-art models on contemporary 3D perception benchmarks like ScanNet consume and label dataset-provided 3D point clouds, obtained through post processing of sensed multiview RGB-D images. They are typically trained in-domain, forego large-scale 2D pre-training and outperform alternatives that featurize the posed RGB-D multiview images instead. The gap in performance between methods that consume posed images versus post-processed 3D point clouds has fueled the belief that 2D and 3D perception require distinct model architectures. In this paper, we challenge this view and propose ODIN (Omni-Dimensional INstance segmentation), a model that can segment and label both 2D RGB images and 3D point clouds, using a transformer architecture that alternates between 2D within-view and 3D cross-view information fusion. Our model differentiates 2D and 3D feature operations through the positional encodings of the tokens involved, which capture pixel coordinates for 2D patch tokens and 3D coordinates for 3D feature tokens. ODIN achieves state-of-the-art performance on ScanNet200, Matterport3D and AI2THOR 3D instance segmentation benchmarks, and competitive performance on ScanNet, S3DIS and COCO. It outperforms all previous works by a wide margin when the sensed 3D point cloud is used in place of the point cloud sampled from 3D mesh. When used as the 3D perception engine in an instructable embodied agent architecture, it sets a new state-of-the-art on the TEACh action-from-dialogue benchmark. Our code and checkpoints can be found at the project website: https://odin-seg.github.io.
Gen2Sim: Scaling up Robot Learning in Simulation with Generative Models
Oct 27, 2023Generalist robot manipulators need to learn a wide variety of manipulation skills across diverse environments. Current robot training pipelines rely on humans to provide kinesthetic demonstrations or to program simulation environments and to code up reward functions for reinforcement learning. Such human involvement is an important bottleneck towards scaling up robot learning across diverse tasks and environments. We propose Generation to Simulation (Gen2Sim), a method for scaling up robot skill learning in simulation by automating generation of 3D assets, task descriptions, task decompositions and reward functions using large pre-trained generative models of language and vision. We generate 3D assets for simulation by lifting open-world 2D object-centric images to 3D using image diffusion models and querying LLMs to determine plausible physics parameters. Given URDF files of generated and human-developed assets, we chain-of-thought prompt LLMs to map these to relevant task descriptions, temporal decompositions, and corresponding python reward functions for reinforcement learning. We show Gen2Sim succeeds in learning policies for diverse long horizon tasks, where reinforcement learning with non temporally decomposed reward functions fails. Gen2Sim provides a viable path for scaling up reinforcement learning for robot manipulators in simulation, both by diversifying and expanding task and environment development, and by facilitating the discovery of reinforcement-learned behaviors through temporal task decomposition in RL. Our work contributes hundreds of simulated assets, tasks and demonstrations, taking a step towards fully autonomous robotic manipulation skill acquisition in simulation.
DeepMPCVS: Deep Model Predictive Control for Visual Servoing
May 03, 2021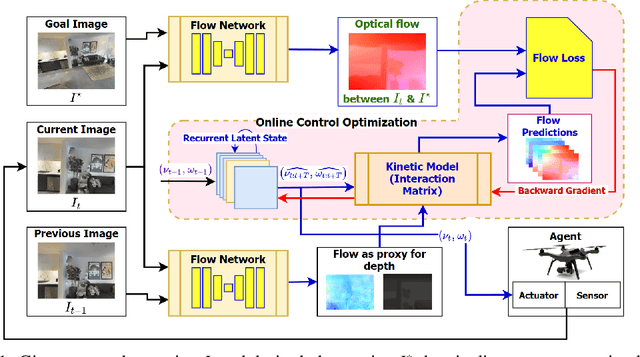
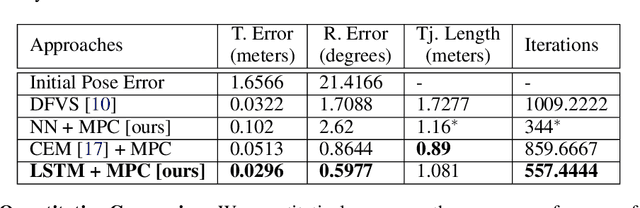

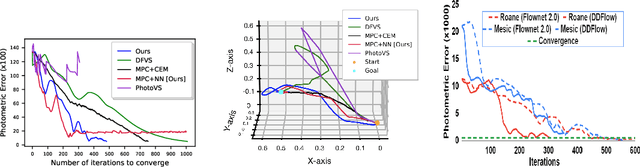
The simplicity of the visual servoing approach makes it an attractive option for tasks dealing with vision-based control of robots in many real-world applications. However, attaining precise alignment for unseen environments pose a challenge to existing visual servoing approaches. While classical approaches assume a perfect world, the recent data-driven approaches face issues when generalizing to novel environments. In this paper, we aim to combine the best of both worlds. We present a deep model predictive visual servoing framework that can achieve precise alignment with optimal trajectories and can generalize to novel environments. Our framework consists of a deep network for optical flow predictions, which are used along with a predictive model to forecast future optical flow. For generating an optimal set of velocities we present a control network that can be trained on the fly without any supervision. Through extensive simulations on photo-realistic indoor settings of the popular Habitat framework, we show significant performance gain due to the proposed formulation vis-a-vis recent state-of-the-art methods. Specifically, we show a faster convergence and an improved performance in trajectory length over recent approaches.
* Accepted at 4th Annual Conference on Robot Learning, CoRL 2020, Cambridge, MA, USA, November 16 - November 18, 2020