 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCoRe: Regularized Contrastive Representation Learning of World Model
Dec 14, 2023


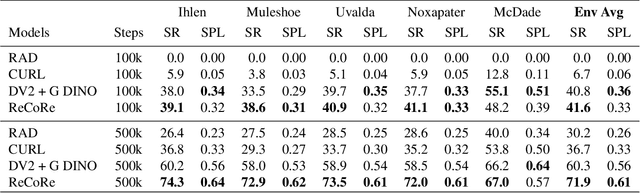
While recent model-free Reinforcement Learning (RL) methods have demonstrated human-level effectiveness in gaming environments, their success in everyday tasks like visual navigation has been limited, particularly under significant appearance variations. This limitation arises from (i) poor sample efficiency and (ii) over-fitting to training scenarios. To address these challenges, we present a world model that learns invariant features using (i) contrastive unsupervised learning and (ii) an intervention-invariant regularizer. Learning an explicit representation of the world dynamics i.e. a world model, improves sample efficiency while contrastive learning implicitly enforces learning of invariant features, which improves generalization. However, the naive integration of contrastive loss to world models fails due to a lack of supervisory signals to the visual encoder, as world-model-based RL methods independently optimize representation learning and agent policy. To overcome this issue, we propose an intervention-invariant regularizer in the form of an auxiliary task such as depth prediction, image denoising, etc., that explicitly enforces invariance to style-interventions. Our method outperforms current state-of-the-art model-based and model-free RL methods and significantly on out-of-distribution point navigation task evaluated on the iGibson benchmark. We further demonstrate that our approach, with only visual observations, outperforms recent language-guided foundation models for point navigation, which is essential for deployment on robots with limited computation capabilities. Finally, we demonstrate that our proposed model excels at the sim-to-real transfer of its perception module on Gibson benchmark.
LanGWM: Language Grounded World Model
Nov 29, 2023Recent advances in deep reinforcement learning have showcased its potential in tackling complex tasks. However, experiments on visual control tasks have revealed that state-of-the-art reinforcement learning models struggle with out-of-distribution generalization. Conversely, expressing higher-level concepts and global contexts is relatively easy using language. Building upon recent success of the large language models, our main objective is to improve the state abstraction technique in reinforcement learning by leveraging language for robust action selection. Specifically, we focus on learning language-grounded visual features to enhance the world model learning, a model-based reinforcement learning technique. To enforce our hypothesis explicitly, we mask out the bounding boxes of a few objects in the image observation and provide the text prompt as descriptions for these masked objects. Subsequently, we predict the masked objects along with the surrounding regions as pixel reconstruction, similar to the transformer-based masked autoencoder approach. Our proposed LanGWM: Language Grounded World Model achieves state-of-the-art performance in out-of-distribution test at the 100K interaction steps benchmarks of iGibson point navigation tasks. Furthermore, our proposed technique of explicit language-grounded visual representation learning has the potential to improve models for human-robot interaction because our extracted visual features are language grounded.
MVRackLay: Monocular Multi-View Layout Estimation for Warehouse Racks and Shelves
Nov 30, 2022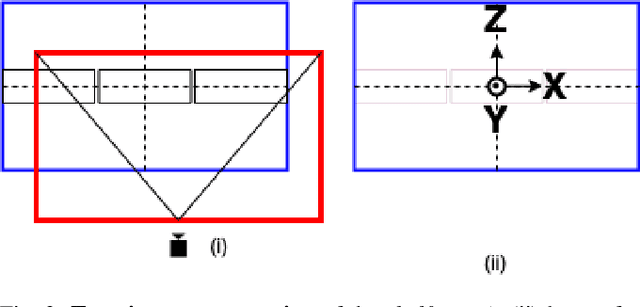
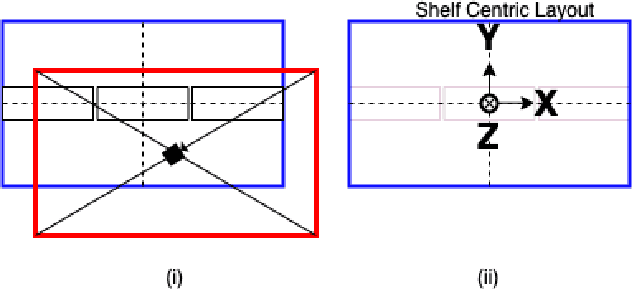
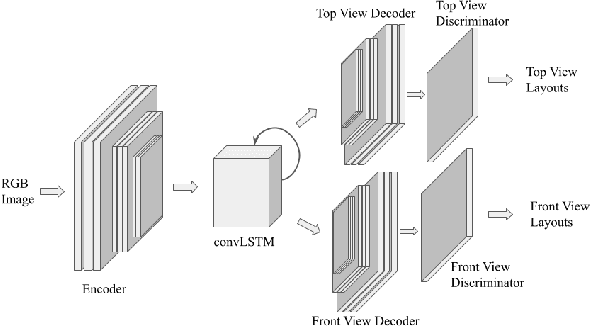
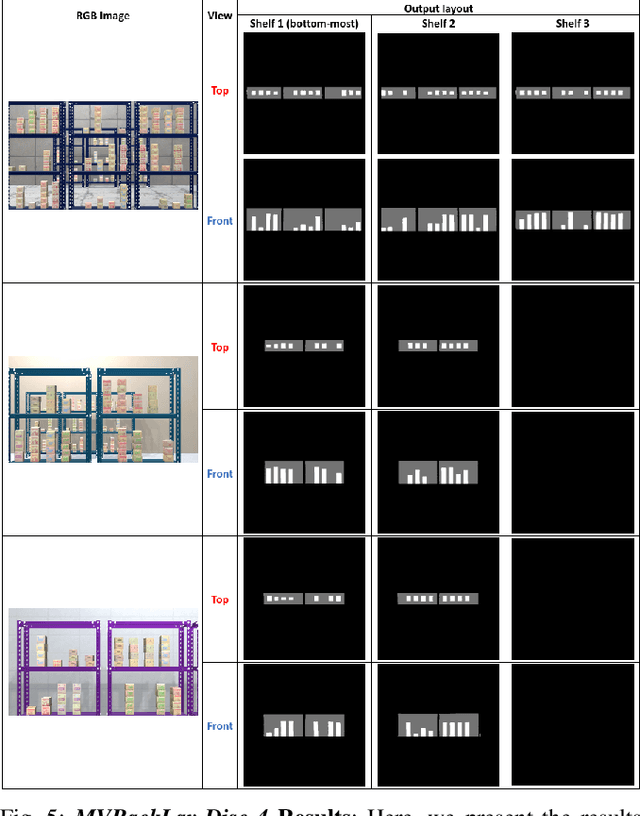
In this paper, we propose and showcase, for the first time, monocular multi-view layout estimation for warehouse racks and shelves. Unlike typical layout estimation methods, MVRackLay estimates multi-layered layouts, wherein each layer corresponds to the layout of a shelf within a rack. Given a sequence of images of a warehouse scene, a dual-headed Convolutional-LSTM architecture outputs segmented racks, the front and the top view layout of each shelf within a rack. With minimal effort, such an output is transformed into a 3D rendering of all racks, shelves and objects on the shelves, giving an accurate 3D depiction of the entire warehouse scene in terms of racks, shelves and the number of objects on each shelf. MVRackLay generalizes to a diverse set of warehouse scenes with varying number of objects on each shelf, number of shelves and in the presence of other such racks in the background. Further, MVRackLay shows superior performance vis-a-vis its single view counterpart, RackLay, in layout accuracy, quantized in terms of the mean IoU and mAP metrics. We also showcase a multi-view stitching of the 3D layouts resulting in a representation of the warehouse scene with respect to a global reference frame akin to a rendering of the scene from a SLAM pipeline. To the best of our knowledge, this is the first such work to portray a 3D rendering of a warehouse scene in terms of its semantic components - Racks, Shelves and Objects - all from a single monocular camera.
Contrastive Unsupervised Learning of World Model with Invariant Causal Features
Sep 29, 2022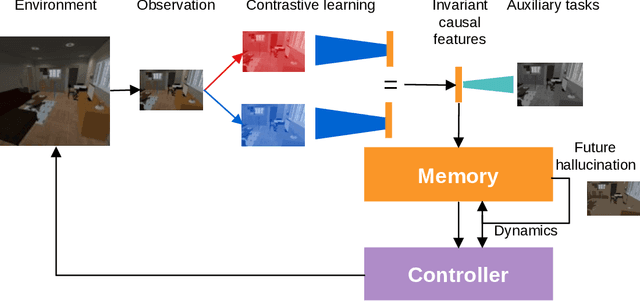
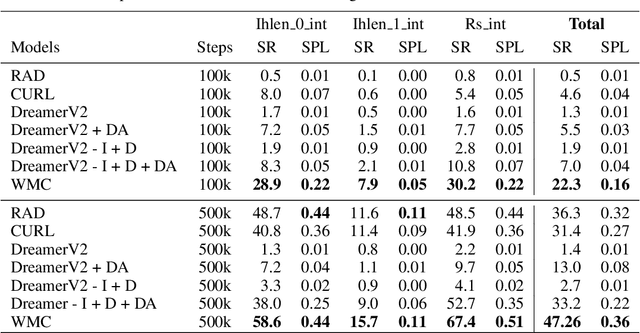
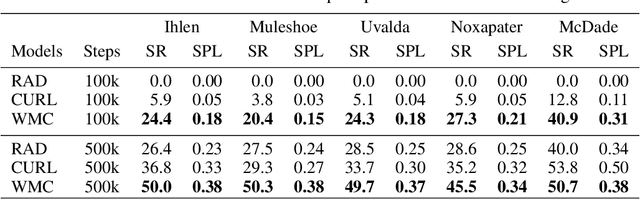
In this paper we present a world model, which learns causal features using the invariance principle. In particular, we use contrastive unsupervised learning to learn the invariant causal features, which enforces invariance across augmentations of irrelevant parts or styles of the observation. The world-model-based reinforcement learning methods independently optimize representation learning and the policy. Thus naive contrastive loss implementation collapses due to a lack of supervisory signals to the representation learning module. We propose an intervention invariant auxiliary task to mitigate this issue. Specifically, we utilize depth prediction to explicitly enforce the invariance and use data augmentation as style intervention on the RGB observation space. Our design leverages unsupervised representation learning to learn the world model with invariant causal features. Our proposed method significantly outperforms current state-of-the-art model-based and model-free reinforcement learning methods on out-of-distribution point navigation tasks on the iGibson dataset. Moreover, our proposed model excels at the sim-to-real transfer of our perception learning module. Finally, we evaluate our approach on the DeepMind control suite and enforce invariance only implicitly since depth is not available. Nevertheless, our proposed model performs on par with the state-of-the-art counterpart.
Flow Synthesis Based Visual Servoing Frameworks for Monocular Obstacle Avoidance Amidst High-Rises
Jul 07, 2022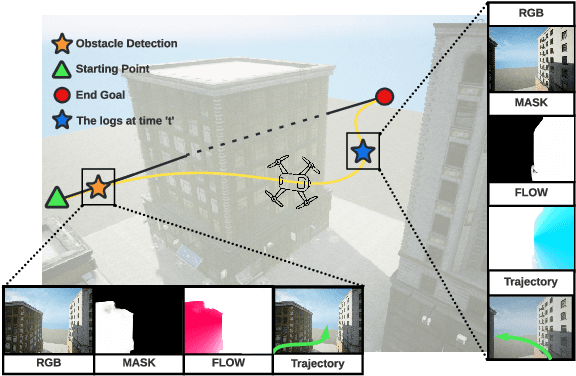
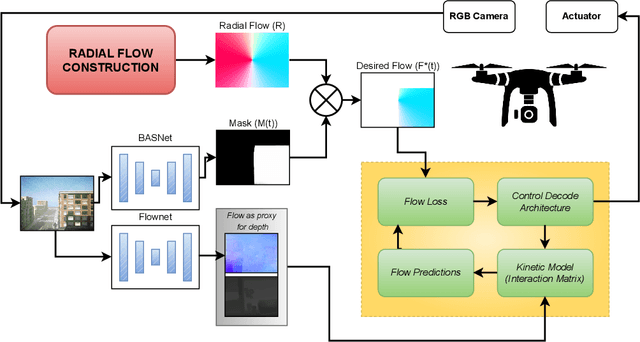

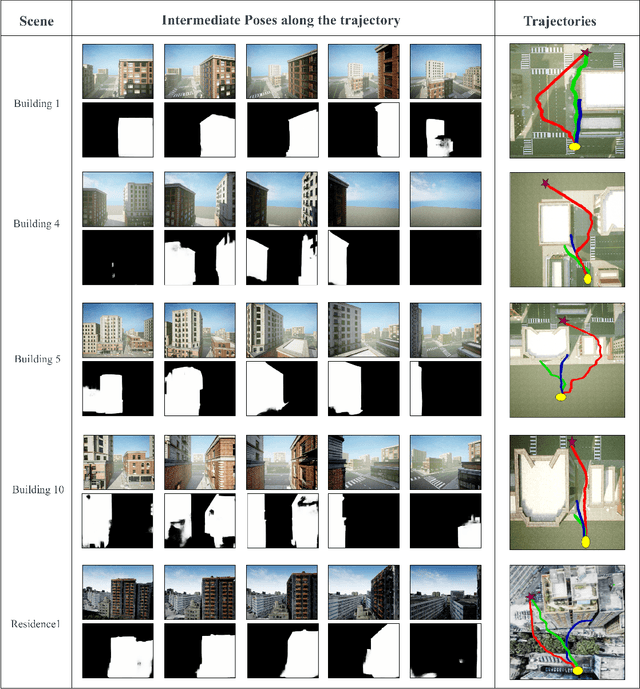
We propose a novel flow synthesis based visual servoing framework enabling long-range obstacle avoidance for Micro Air Vehicles (MAV) flying amongst tall skyscrapers. Recent deep learning based frameworks use optical flow to do high-precision visual servoing. In this paper, we explore the question: can we design a surrogate flow for these high-precision visual-servoing methods, which leads to obstacle avoidance? We revisit the concept of saliency for identifying high-rise structures in/close to the line of attack amongst other competing skyscrapers and buildings as a collision obstacle. A synthesised flow is used to displace the salient object segmentation mask. This flow is so computed that the visual servoing controller maneuvers the MAV safely around the obstacle. In this approach, we use a multi-step Cross-Entropy Method (CEM) based servo control to achieve flow convergence, resulting in obstacle avoidance. We use this novel pipeline to successfully and persistently maneuver high-rises and reach the goal in simulated and photo-realistic real-world scenes. We conduct extensive experimentation and compare our approach with optical flow and short-range depth-based obstacle avoidance methods to demonstrate the proposed framework's merit. Additional Visualisation can be found at https://sites.google.com/view/monocular-obstacle/home
DeepMPCVS: Deep Model Predictive Control for Visual Servoing
May 03, 2021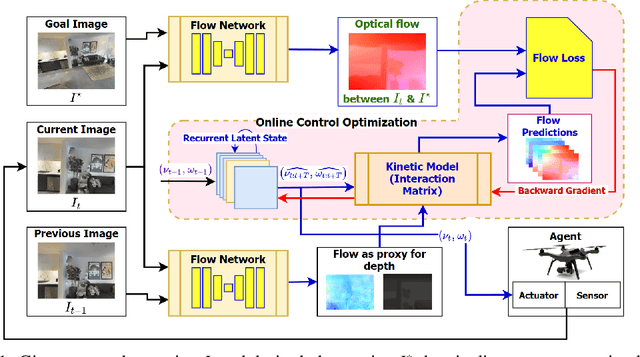
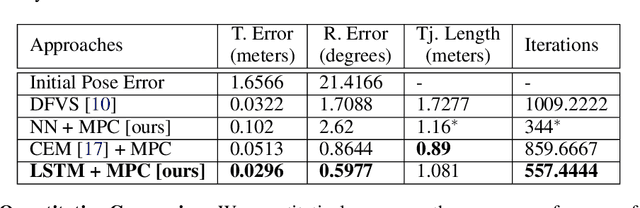

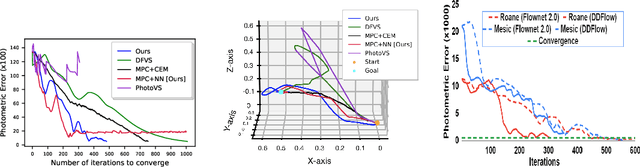
The simplicity of the visual servoing approach makes it an attractive option for tasks dealing with vision-based control of robots in many real-world applications. However, attaining precise alignment for unseen environments pose a challenge to existing visual servoing approaches. While classical approaches assume a perfect world, the recent data-driven approaches face issues when generalizing to novel environments. In this paper, we aim to combine the best of both worlds. We present a deep model predictive visual servoing framework that can achieve precise alignment with optimal trajectories and can generalize to novel environments. Our framework consists of a deep network for optical flow predictions, which are used along with a predictive model to forecast future optical flow. For generating an optimal set of velocities we present a control network that can be trained on the fly without any supervision. Through extensive simulations on photo-realistic indoor settings of the popular Habitat framework, we show significant performance gain due to the proposed formulation vis-a-vis recent state-of-the-art methods. Specifically, we show a faster convergence and an improved performance in trajectory length over recent approaches.
* Accepted at 4th Annual Conference on Robot Learning, CoRL 2020, Cambridge, MA, USA, November 16 - November 18, 2020
Action-Conditional Recurrent Kalman Networks For Forward and Inverse Dynamics Learning
Nov 05, 2020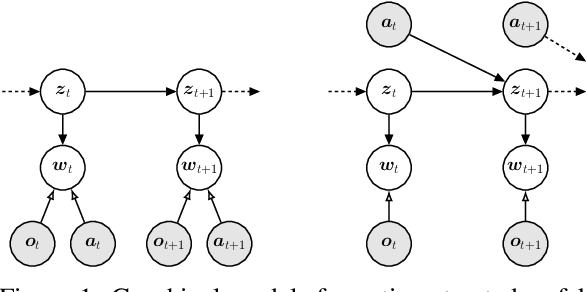

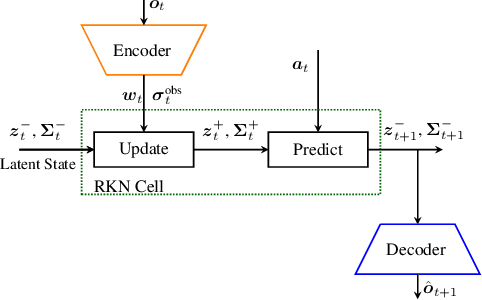

Estimating accurate forward and inverse dynamics models is a crucial component of model-based control for sophisticated robots such as robots driven by hydraulics, artificial muscles, or robots dealing with different contact situations. Analytic models to such processes are often unavailable or inaccurate due to complex hysteresis effects, unmodelled friction and stiction phenomena,and unknown effects during contact situations. A promising approach is to obtain spatio-temporal models in a data-driven way using recurrent neural networks, as they can overcome those issues. However, such models often do not meet accuracy demands sufficiently, degenerate in performance for the required high sampling frequencies and cannot provide uncertainty estimates. We adopt a recent probabilistic recurrent neural network architecture, called Re-current Kalman Networks (RKNs), to model learning by conditioning its transition dynamics on the control actions. RKNs outperform standard recurrent networks such as LSTMs on many state estimation tasks. Inspired by Kalman filters, the RKN provides an elegant way to achieve action conditioning within its recurrent cell by leveraging additive interactions between the current latent state and the action variables. We present two architectures, one for forward model learning and one for inverse model learning. Both architectures significantly outperform exist-ing model learning frameworks as well as analytical models in terms of prediction performance on a variety of real robot dynamics models.
DFVS: Deep Flow Guided Scene Agnostic Image Based Visual Servoing
Mar 08, 2020

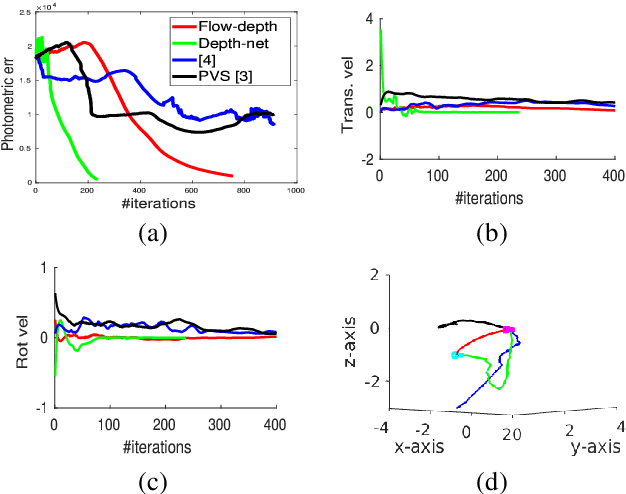
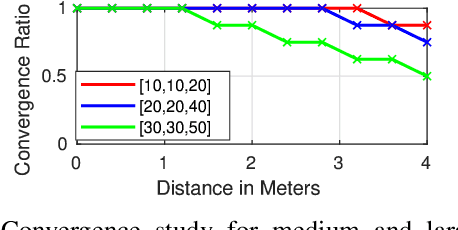
Existing deep learning based visual servoing approaches regress the relative camera pose between a pair of images. Therefore, they require a huge amount of training data and sometimes fine-tuning for adaptation to a novel scene. Furthermore, current approaches do not consider underlying geometry of the scene and rely on direct estimation of camera pose. Thus, inaccuracies in prediction of the camera pose, especially for distant goals, lead to a degradation in the servoing performance. In this paper, we propose a two-fold solution: (i) We consider optical flow as our visual features, which are predicted using a deep neural network. (ii) These flow features are then systematically integrated with depth estimates provided by another neural network using interaction matrix. We further present an extensive benchmark in a photo-realistic 3D simulation across diverse scenes to study the convergence and generalisation of visual servoing approaches. We show convergence for over 3m and 40 degrees while maintaining precise positioning of under 2cm and 1 degree on our challenging benchmark where the existing approaches that are unable to converge for majority of scenarios for over 1.5m and 20 degrees. Furthermore, we also evaluate our approach for a real scenario on an aerial robot. Our approach generalizes to novel scenarios producing precise and robust servoing performance for 6 degrees of freedom positioning tasks with even large camera transformations without any retraining or fine-tuning.
Recurrent Kalman Networks: Factorized Inference in High-Dimensional Deep Feature Spaces
May 17, 2019

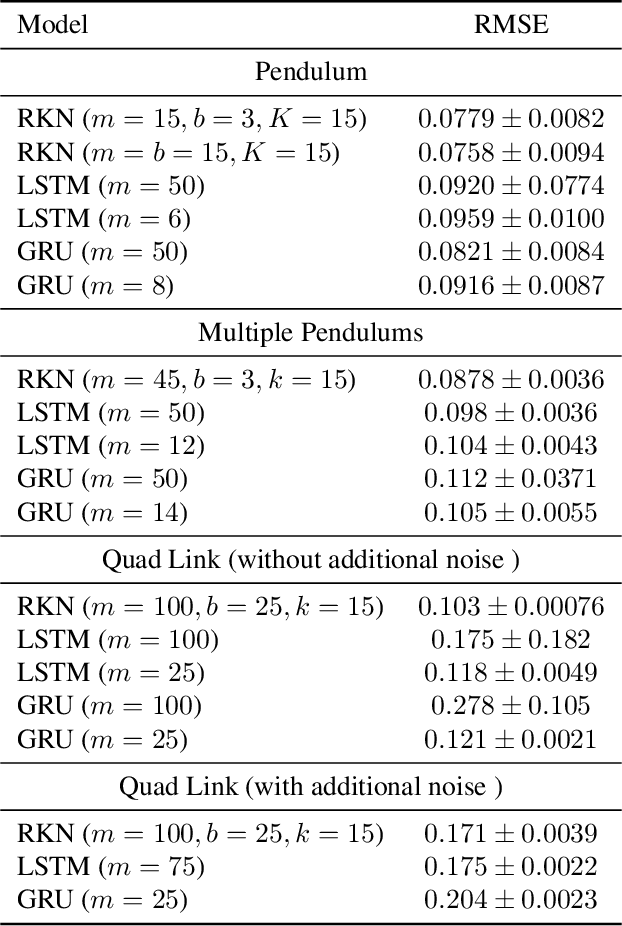
In order to integrate uncertainty estimates into deep time-series modelling, Kalman Filters (KFs) (Kalman et al., 1960) have been integrated with deep learning models, however, such approaches typically rely on approximate inference techniques such as variational inference which makes learning more complex and often less scalable due to approximation errors. We propose a new deep approach to Kalman filtering which can be learned directly in an end-to-end manner using backpropagation without additional approximations. Our approach uses a high-dimensional factorized latent state representation for which the Kalman updates simplify to scalar operations and thus avoids hard to backpropagate, computationally heavy and potentially unstable matrix inversions. Moreover, we use locally linear dynamic models to efficiently propagate the latent state to the next time step. The resulting network architecture, which we call Recurrent Kalman Network (RKN), can be used for any time-series data, similar to a LSTM (Hochreiter & Schmidhuber, 1997) but uses an explicit representation of uncertainty. As shown by our experiments, the RKN obtains much more accurate uncertainty estimates than an LSTM or Gated Recurrent Units (GRUs) (Cho et al., 2014) while also showing a slightly improved prediction performance and outperforms various recent generative models on an image imputation task.
Combining Method of Alternating Projections and Augmented Lagrangian for Task Constrained Trajectory Optimization
Mar 10, 2018
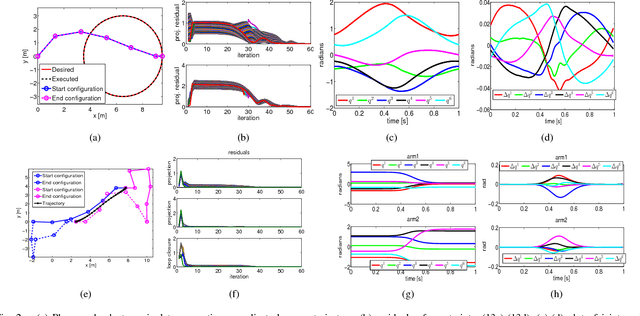

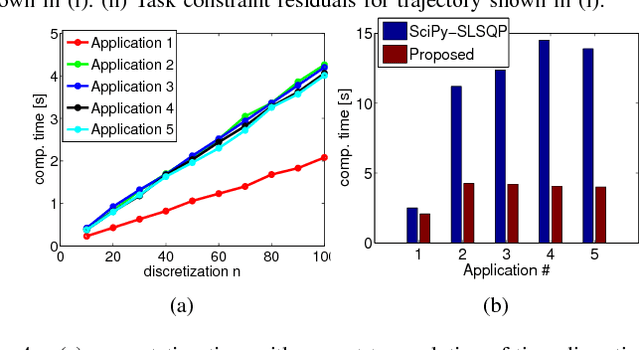
Motion planning for manipulators under task space constraints is difficult as it constrains the joint configurations to always lie on an implicitly defined manifold. It is possible to view task constrained motion planning as an optimization problem with non-linear equality constraints which can be solved by general non-linear optimization techniques. In this paper, we present a novel custom optimizer which exploits the underlying structure present in many task constraints. At the core of our approach are some simple reformulations, which when coupled with the \emph{method of alternating projection}, leads to an efficient convex optimization based routine for computing a feasible solution to the task constraints. We subsequently build on this result and use the concept of Augmented Lagrangian to guide the feasible solutions towards those which also minimize the user defined cost function. We show that the proposed optimizer is fully distributive and thus, can be easily parallelized. We validate our formulation on some common robotic benchmark problems. In particular, we show that the proposed optimizer achieves cyclic motion in the joint space corresponding to a similar nature trajectory in the task space. Furthermore, as a baseline, we compare the proposed optimizer with an off-the-shelf non-linear solver provide in open source package SciPy. We show that for similar task constraint residuals and smoothness cost, it can be upto more than three times faster than the SciPy alternative.