 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine2Servo: Intelligent Visual Servoing with Diffusion-Driven Goal Generation for Robotic Tasks
Oct 16, 2024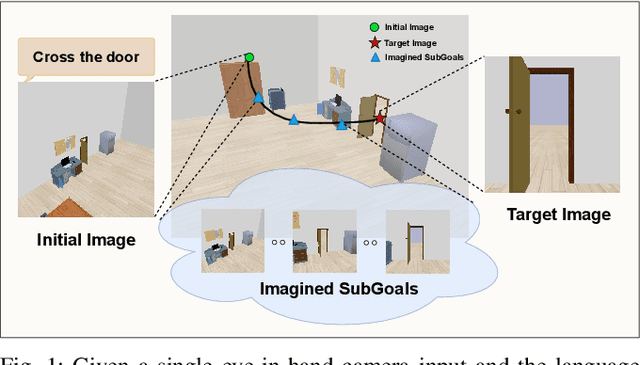
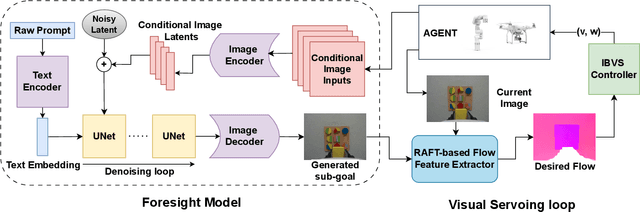
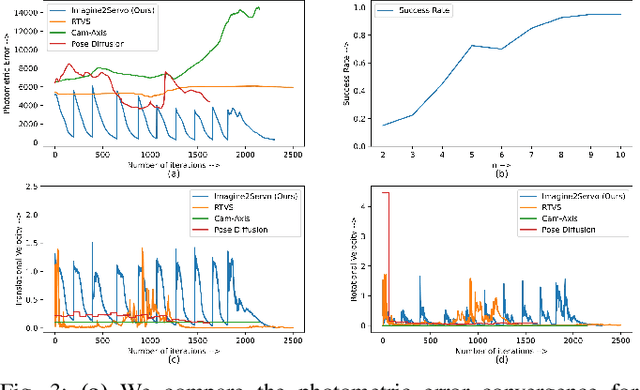

Visual servoing, the method of controlling robot motion through feedback from visual sensors, has seen significant advancements with the integration of optical flow-based methods. However, its application remains limited by inherent challenges, such as the necessity for a target image at test time, the requirement of substantial overlap between initial and target images, and the reliance on feedback from a single camera. This paper introduces Imagine2Servo, an innovative approach leveraging diffusion-based image editing techniques to enhance visual servoing algorithms by generating intermediate goal images. This methodology allows for the extension of visual servoing applications beyond traditional constraints, enabling tasks like long-range navigation and manipulation without predefined goal images. We propose a pipeline that synthesizes subgoal images grounded in the task at hand, facilitating servoing in scenarios with minimal initial and target image overlap and integrating multi-camera feedback for comprehensive task execution. Our contributions demonstrate a novel application of image generation to robotic control, significantly broadening the capabilities of visual servoing systems. Real-world experiments validate the effectiveness and versatility of the Imagine2Servo framework in accomplishing a variety of tasks, marking a notable advancement in the field of visual servoing.
On Time-Indexing as Inductive Bias in Deep RL for Sequential Manipulation Tasks
Jan 03, 2024While solving complex manipulation tasks, manipulation policies often need to learn a set of diverse skills to accomplish these tasks. The set of skills is often quite multimodal - each one may have a quite distinct distribution of actions and states. Standard deep policy-learning algorithms often model policies as deep neural networks with a single output head (deterministic or stochastic). This structure requires the network to learn to switch between modes internally, which can lead to lower sample efficiency and poor performance. In this paper we explore a simple structure which is conducive to skill learning required for so many of the manipulation tasks. Specifically, we propose a policy architecture that sequentially executes different action heads for fixed durations, enabling the learning of primitive skills such as reaching and grasping. Our empirical evaluation on the Metaworld tasks reveals that this simple structure outperforms standard policy learning methods, highlighting its potential for improved skill acquisition.
Flow Synthesis Based Visual Servoing Frameworks for Monocular Obstacle Avoidance Amidst High-Rises
Jul 07, 2022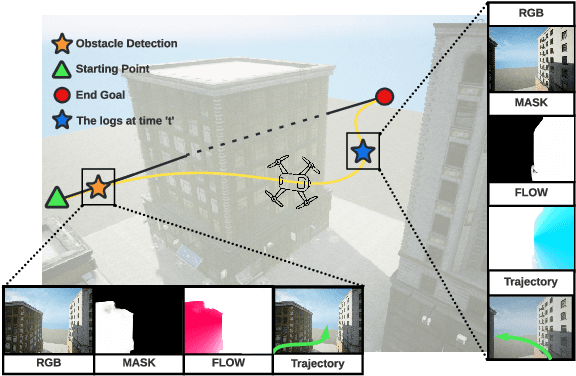
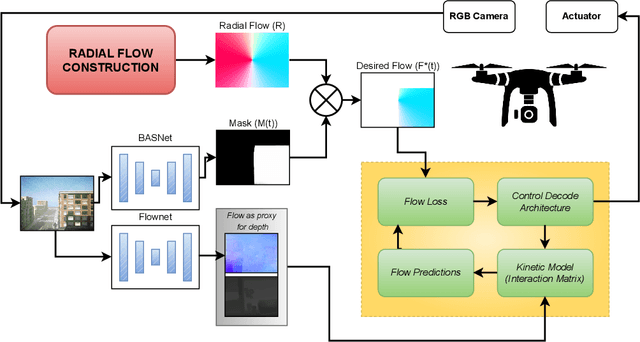

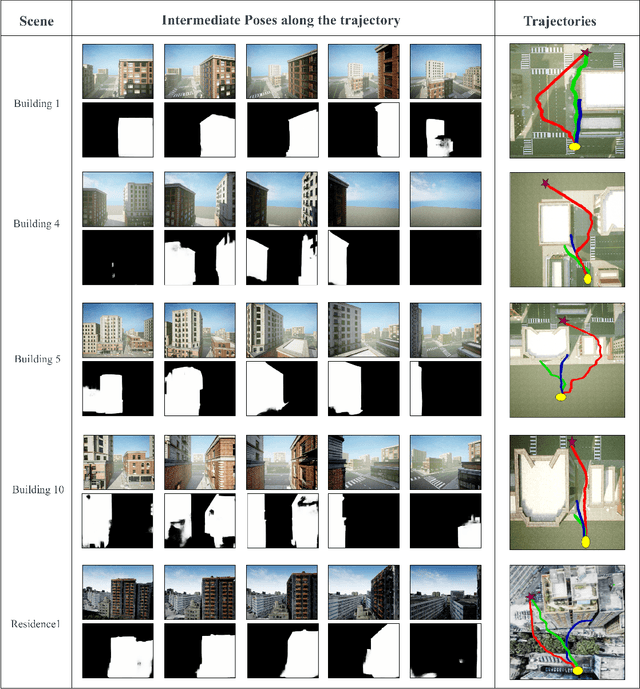
We propose a novel flow synthesis based visual servoing framework enabling long-range obstacle avoidance for Micro Air Vehicles (MAV) flying amongst tall skyscrapers. Recent deep learning based frameworks use optical flow to do high-precision visual servoing. In this paper, we explore the question: can we design a surrogate flow for these high-precision visual-servoing methods, which leads to obstacle avoidance? We revisit the concept of saliency for identifying high-rise structures in/close to the line of attack amongst other competing skyscrapers and buildings as a collision obstacle. A synthesised flow is used to displace the salient object segmentation mask. This flow is so computed that the visual servoing controller maneuvers the MAV safely around the obstacle. In this approach, we use a multi-step Cross-Entropy Method (CEM) based servo control to achieve flow convergence, resulting in obstacle avoidance. We use this novel pipeline to successfully and persistently maneuver high-rises and reach the goal in simulated and photo-realistic real-world scenes. We conduct extensive experimentation and compare our approach with optical flow and short-range depth-based obstacle avoidance methods to demonstrate the proposed framework's merit. Additional Visualisation can be found at https://sites.google.com/view/monocular-obstacle/home