 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine2Servo: Intelligent Visual Servoing with Diffusion-Driven Goal Generation for Robotic Tasks
Oct 16, 2024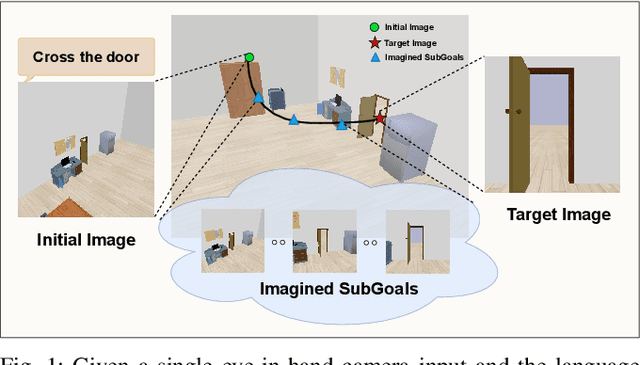
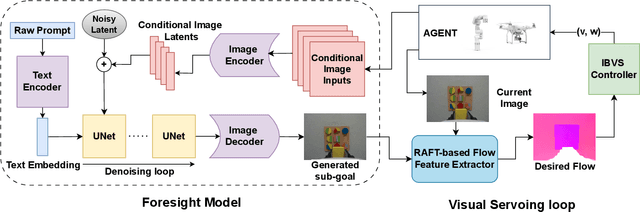
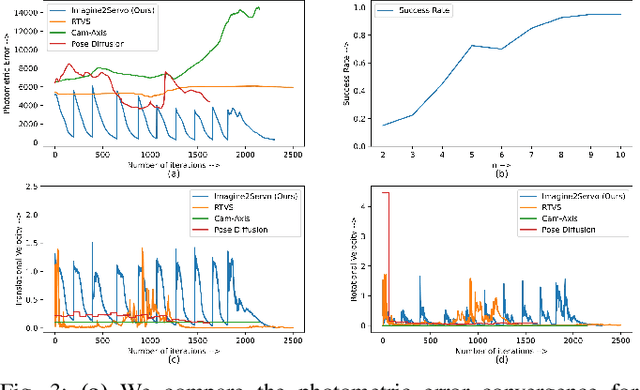

Visual servoing, the method of controlling robot motion through feedback from visual sensors, has seen significant advancements with the integration of optical flow-based methods. However, its application remains limited by inherent challenges, such as the necessity for a target image at test time, the requirement of substantial overlap between initial and target images, and the reliance on feedback from a single camera. This paper introduces Imagine2Servo, an innovative approach leveraging diffusion-based image editing techniques to enhance visual servoing algorithms by generating intermediate goal images. This methodology allows for the extension of visual servoing applications beyond traditional constraints, enabling tasks like long-range navigation and manipulation without predefined goal images. We propose a pipeline that synthesizes subgoal images grounded in the task at hand, facilitating servoing in scenarios with minimal initial and target image overlap and integrating multi-camera feedback for comprehensive task execution. Our contributions demonstrate a novel application of image generation to robotic control, significantly broadening the capabilities of visual servoing systems. Real-world experiments validate the effectiveness and versatility of the Imagine2Servo framework in accomplishing a variety of tasks, marking a notable advancement in the field of visual servoing.
MVRackLay: Monocular Multi-View Layout Estimation for Warehouse Racks and Shelves
Nov 30, 2022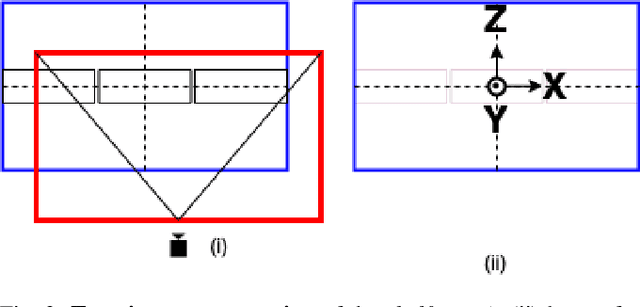
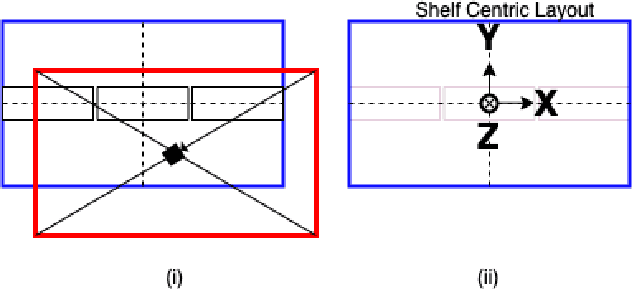
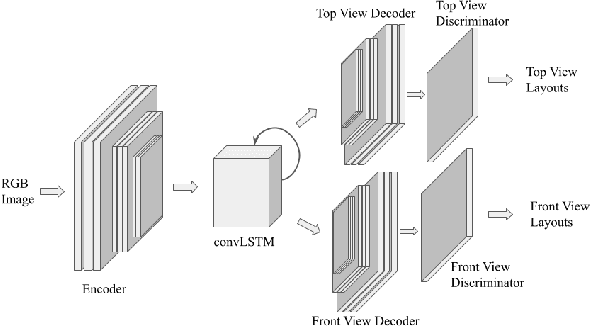
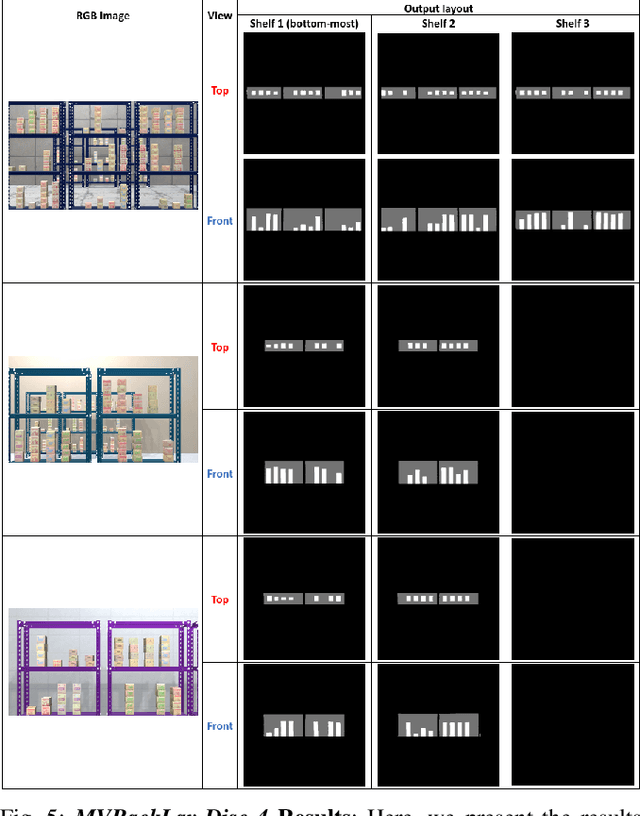
In this paper, we propose and showcase, for the first time, monocular multi-view layout estimation for warehouse racks and shelves. Unlike typical layout estimation methods, MVRackLay estimates multi-layered layouts, wherein each layer corresponds to the layout of a shelf within a rack. Given a sequence of images of a warehouse scene, a dual-headed Convolutional-LSTM architecture outputs segmented racks, the front and the top view layout of each shelf within a rack. With minimal effort, such an output is transformed into a 3D rendering of all racks, shelves and objects on the shelves, giving an accurate 3D depiction of the entire warehouse scene in terms of racks, shelves and the number of objects on each shelf. MVRackLay generalizes to a diverse set of warehouse scenes with varying number of objects on each shelf, number of shelves and in the presence of other such racks in the background. Further, MVRackLay shows superior performance vis-a-vis its single view counterpart, RackLay, in layout accuracy, quantized in terms of the mean IoU and mAP metrics. We also showcase a multi-view stitching of the 3D layouts resulting in a representation of the warehouse scene with respect to a global reference frame akin to a rendering of the scene from a SLAM pipeline. To the best of our knowledge, this is the first such work to portray a 3D rendering of a warehouse scene in terms of its semantic components - Racks, Shelves and Objects - all from a single monocular camera.