 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowd-FM: Learned Optimal Selection of Conditional Flow Matching-generated Trajectories for Crowd Navigation
Feb 06, 2026Safe and computationally efficient local planning for mobile robots in dense, unstructured human crowds remains a fundamental challenge. Moreover, ensuring that robot trajectories are similar to how a human moves will increase the acceptance of the robot in human environments. In this paper, we present Crowd-FM, a learning-based approach to address both safety and human-likeness challenges. Our approach has two novel components. First, we train a Conditional Flow-Matching (CFM) policy over a dataset of optimally controlled trajectories to learn a set of collision-free primitives that a robot can choose at any given scenario. The chosen optimal control solver can generate multi-modal collision-free trajectories, allowing the CFM policy to learn a diverse set of maneuvers. Secondly, we learn a score function over a dataset of human demonstration trajectories that provides a human-likeness score for the flow primitives. At inference time, computing the optimal trajectory requires selecting the one with the highest score. Our approach improves the state-of-the-art by showing that our CFM policy alone can produce collision-free navigation with a higher success rate than existing learning-based baselines. Furthermore, when augmented with inference-time refinement, our approach can outperform even expensive optimisation-based planning approaches. Finally, we validate that our scoring network can select trajectories closer to the expert data than a manually designed cost function.
MonoMPC: Monocular Vision Based Navigation with Learned Collision Model and Risk-Aware Model Predictive Control
Aug 10, 2025Navigating unknown environments with a single RGB camera is challenging, as the lack of depth information prevents reliable collision-checking. While some methods use estimated depth to build collision maps, we found that depth estimates from vision foundation models are too noisy for zero-shot navigation in cluttered environments. We propose an alternative approach: instead of using noisy estimated depth for direct collision-checking, we use it as a rich context input to a learned collision model. This model predicts the distribution of minimum obstacle clearance that the robot can expect for a given control sequence. At inference, these predictions inform a risk-aware MPC planner that minimizes estimated collision risk. Our joint learning pipeline co-trains the collision model and risk metric using both safe and unsafe trajectories. Crucially, our joint-training ensures optimal variance in our collision model that improves navigation in highly cluttered environments. Consequently, real-world experiments show 9x and 7x improvements in success rates over NoMaD and the ROS stack, respectively. Ablation studies further validate the effectiveness of our design choices.
$π$-MPPI: A Projection-based Model Predictive Path Integral Scheme for Smooth Optimal Control of Fixed-Wing Aerial Vehicles
Apr 16, 2025Model Predictive Path Integral (MPPI) is a popular sampling-based Model Predictive Control (MPC) algorithm for nonlinear systems. It optimizes trajectories by sampling control sequences and averaging them. However, a key issue with MPPI is the non-smoothness of the optimal control sequence, leading to oscillations in systems like fixed-wing aerial vehicles (FWVs). Existing solutions use post-hoc smoothing, which fails to bound control derivatives. This paper introduces a new approach: we add a projection filter $\pi$ to minimally correct control samples, ensuring bounds on control magnitude and higher-order derivatives. The filtered samples are then averaged using MPPI, leading to our $\pi$-MPPI approach. We minimize computational overhead by using a neural accelerated custom optimizer for the projection filter. $\pi$-MPPI offers a simple way to achieve arbitrary smoothness in control sequences. While we focus on FWVs, this projection filter can be integrated into any MPPI pipeline. Applied to FWVs, $\pi$-MPPI is easier to tune than the baseline, resulting in smoother, more robust performance.
Swarm-Gen: Fast Generation of Diverse Feasible Swarm Behaviors
Jan 31, 2025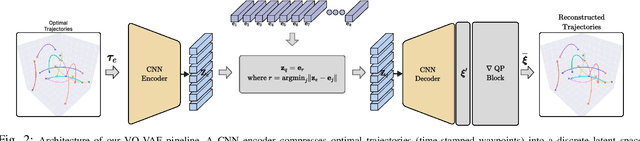
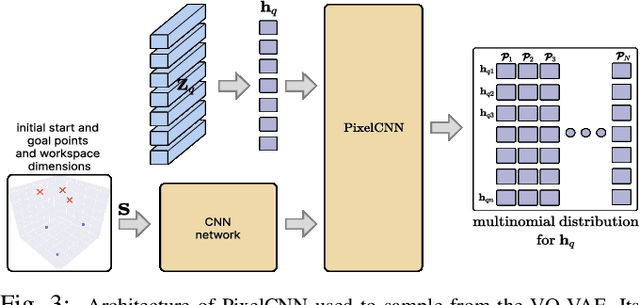

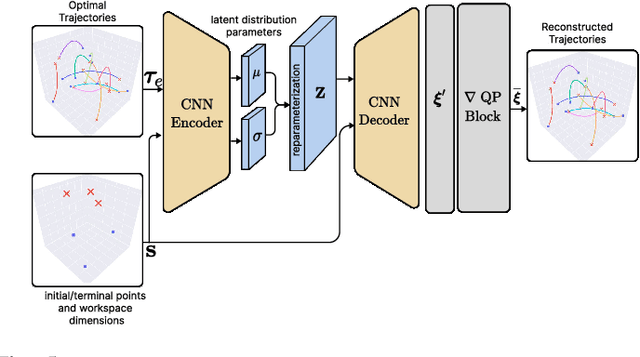
Coordination behavior in robot swarms is inherently multi-modal in nature. That is, there are numerous ways in which a swarm of robots can avoid inter-agent collisions and reach their respective goals. However, the problem of generating diverse and feasible swarm behaviors in a scalable manner remains largely unaddressed. In this paper, we fill this gap by combining generative models with a safety-filter (SF). Specifically, we sample diverse trajectories from a learned generative model which is subsequently projected onto the feasible set using the SF. We experiment with two choices for generative models, namely: Conditional Variational Autoencoder (CVAE) and Vector-Quantized Variational Autoencoder (VQ-VAE). We highlight the trade-offs these two models provide in terms of computation time and trajectory diversity. We develop a custom solver for our SF and equip it with a neural network that predicts context-specific initialization. Thecinitialization network is trained in a self-supervised manner, taking advantage of the differentiability of the SF solver. We provide two sets of empirical results. First, we demonstrate that we can generate a large set of multi-modal, feasible trajectories, simulating diverse swarm behaviors, within a few tens of milliseconds. Second, we show that our initialization network provides faster convergence of our SF solver vis-a-vis other alternative heuristics.
Trajectory Optimization Under Stochastic Dynamics Leveraging Maximum Mean Discrepancy
Jan 31, 2025



This paper addresses sampling-based trajectory optimization for risk-aware navigation under stochastic dynamics. Typically such approaches operate by computing $\tilde{N}$ perturbed rollouts around the nominal dynamics to estimate the collision risk associated with a sequence of control commands. We consider a setting where it is expensive to estimate risk using perturbed rollouts, for example, due to expensive collision-checks. We put forward two key contributions. First, we develop an algorithm that distills the statistical information from a larger set of rollouts to a reduced-set with sample size $N<<\tilde{N}$. Consequently, we estimate collision risk using just $N$ rollouts instead of $\tilde{N}$. Second, we formulate a novel surrogate for the collision risk that can leverage the distilled statistical information contained in the reduced-set. We formalize both algorithmic contributions using distribution embedding in Reproducing Kernel Hilbert Space (RKHS) and Maximum Mean Discrepancy (MMD). We perform extensive benchmarking to demonstrate that our MMD-based approach leads to safer trajectories at low sample regime than existing baselines using Conditional Value-at Risk (CVaR) based collision risk estimate.
MMD-OPT : Maximum Mean Discrepancy Based Sample Efficient Collision Risk Minimization for Autonomous Driving
Dec 12, 2024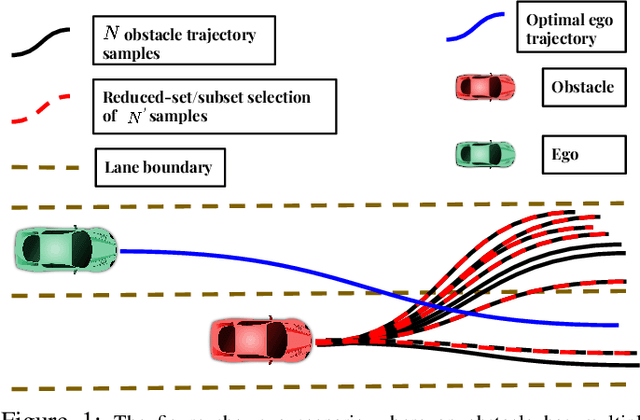
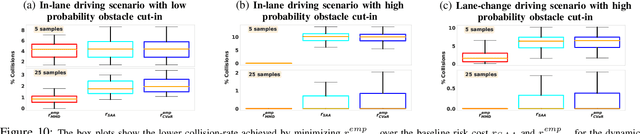
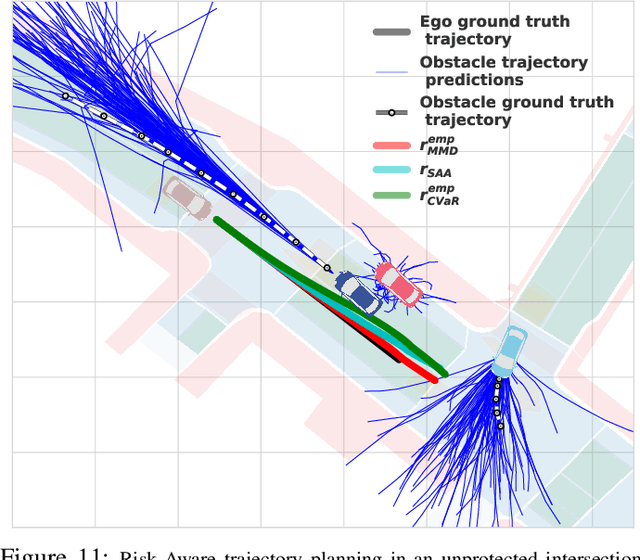
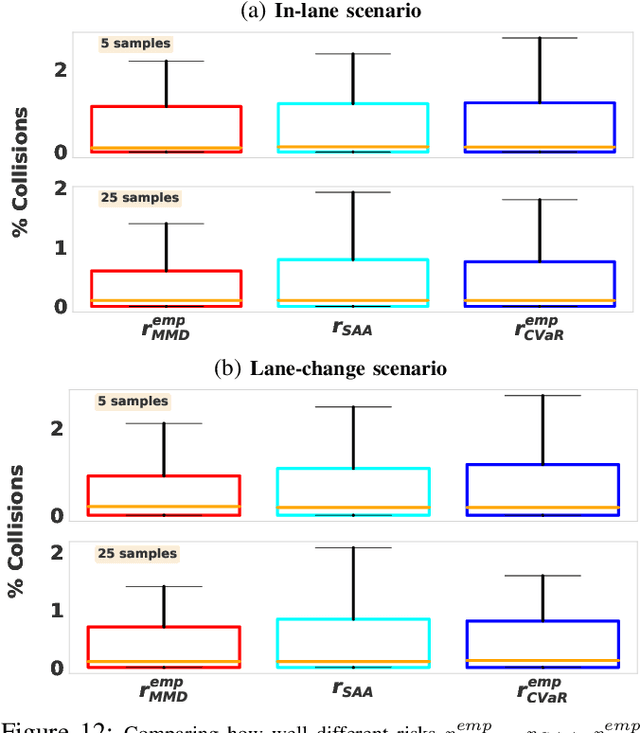
We propose MMD-OPT: a sample-efficient approach for minimizing the risk of collision under arbitrary prediction distribution of the dynamic obstacles. MMD-OPT is based on embedding distribution in Reproducing Kernel Hilbert Space (RKHS) and the associated Maximum Mean Discrepancy (MMD). We show how these two concepts can be used to define a sample efficient surrogate for collision risk estimate. We perform extensive simulations to validate the effectiveness of MMD-OPT on both synthetic and real-world datasets. Importantly, we show that trajectory optimization with our MMD-based collision risk surrogate leads to safer trajectories at low sample regimes than popular alternatives based on Conditional Value at Risk (CVaR).
DA-VIL: Adaptive Dual-Arm Manipulation with Reinforcement Learning and Variable Impedance Control
Oct 25, 2024



Dual-arm manipulation is an area of growing interest in the robotics community. Enabling robots to perform tasks that require the coordinated use of two arms, is essential for complex manipulation tasks such as handling large objects, assembling components, and performing human-like interactions. However, achieving effective dual-arm manipulation is challenging due to the need for precise coordination, dynamic adaptability, and the ability to manage interaction forces between the arms and the objects being manipulated. We propose a novel pipeline that combines the advantages of policy learning based on environment feedback and gradient-based optimization to learn controller gains required for the control outputs. This allows the robotic system to dynamically modulate its impedance in response to task demands, ensuring stability and dexterity in dual-arm operations. We evaluate our pipeline on a trajectory-tracking task involving a variety of large, complex objects with different masses and geometries. The performance is then compared to three other established methods for controlling dual-arm robots, demonstrating superior results.
CrowdSurfer: Sampling Optimization Augmented with Vector-Quantized Variational AutoEncoder for Dense Crowd Navigation
Sep 24, 2024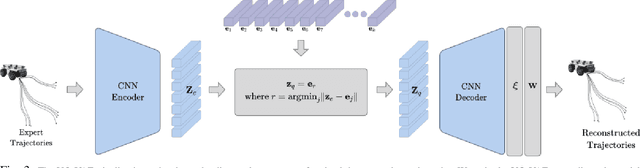
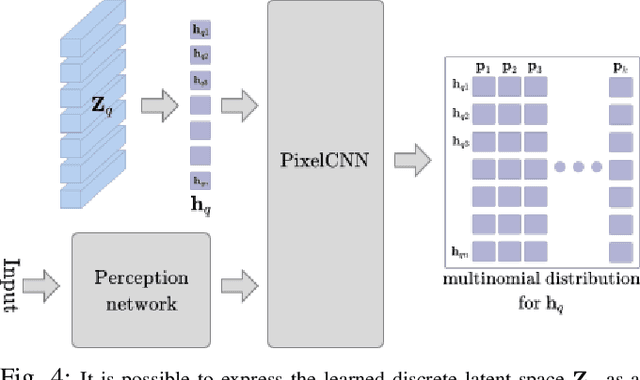
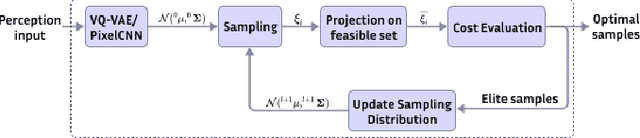
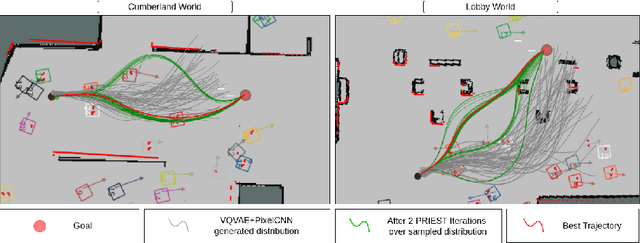
Navigation amongst densely packed crowds remains a challenge for mobile robots. The complexity increases further if the environment layout changes, making the prior computed global plan infeasible. In this paper, we show that it is possible to dramatically enhance crowd navigation by just improving the local planner. Our approach combines generative modelling with inference time optimization to generate sophisticated long-horizon local plans at interactive rates. More specifically, we train a Vector Quantized Variational AutoEncoder to learn a prior over the expert trajectory distribution conditioned on the perception input. At run-time, this is used as an initialization for a sampling-based optimizer for further refinement. Our approach does not require any sophisticated prediction of dynamic obstacles and yet provides state-of-the-art performance. In particular, we compare against the recent DRL-VO approach and show a 40% improvement in success rate and a 6% improvement in travel time.
Differentiable-Optimization Based Neural Policy for Occlusion-Aware Target Tracking
Jun 20, 2024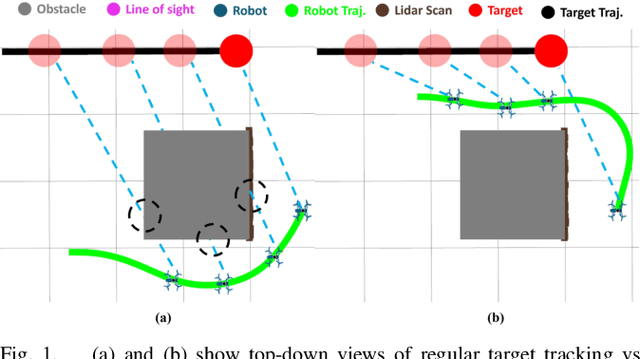
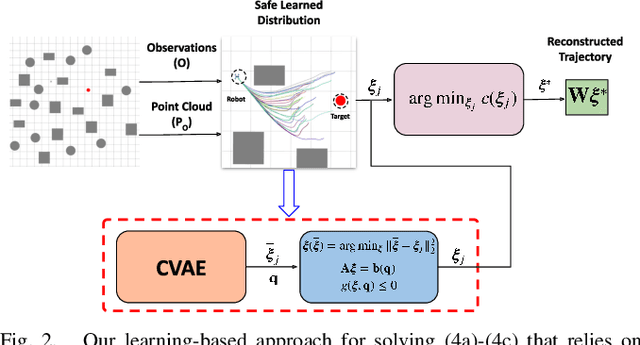
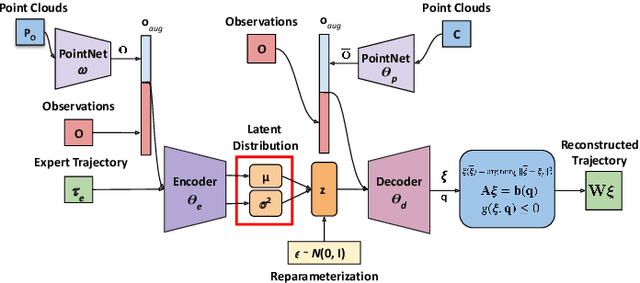

Tracking a target in cluttered and dynamic environments is challenging but forms a core component in applications like aerial cinematography. The obstacles in the environment not only pose collision risk but can also occlude the target from the field-of-view of the robot. Moreover, the target future trajectory may be unknown and only its current state can be estimated. In this paper, we propose a learned probabilistic neural policy for safe, occlusion-free target tracking. The core novelty of our work stems from the structure of our policy network that combines generative modeling based on Conditional Variational Autoencoder (CVAE) with differentiable optimization layers. The role of the CVAE is to provide a base trajectory distribution which is then projected onto a learned feasible set through the optimization layer. Furthermore, both the weights of the CVAE network and the parameters of the differentiable optimization can be learned in an end-to-end fashion through demonstration trajectories. We improve the state-of-the-art (SOTA) in the following respects. We show that our learned policy outperforms existing SOTA in terms of occlusion/collision avoidance capabilities and computation time. Second, we present an extensive ablation showing how different components of our learning pipeline contribute to the overall tracking task. We also demonstrate the real-time performance of our approach on resource-constrained hardware such as NVIDIA Jetson TX2. Finally, our learned policy can also be viewed as a reactive planner for navigation in highly cluttered environments.
Bi-level Trajectory Optimization on Uneven Terrains with Differentiable Wheel-Terrain Interaction Model
Apr 11, 2024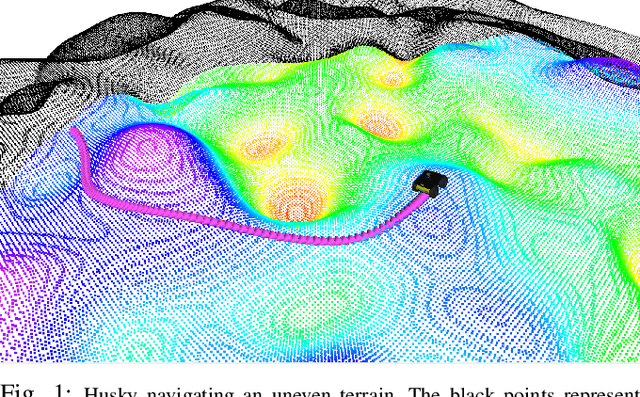
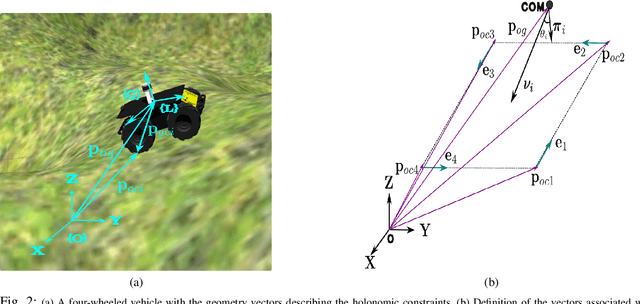
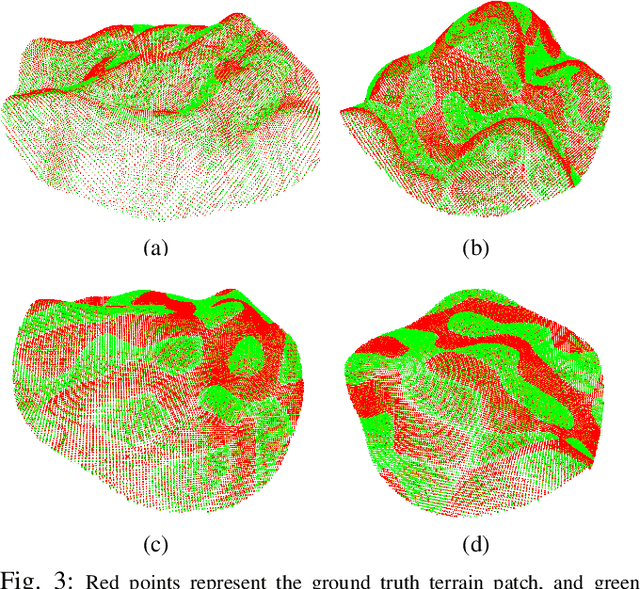
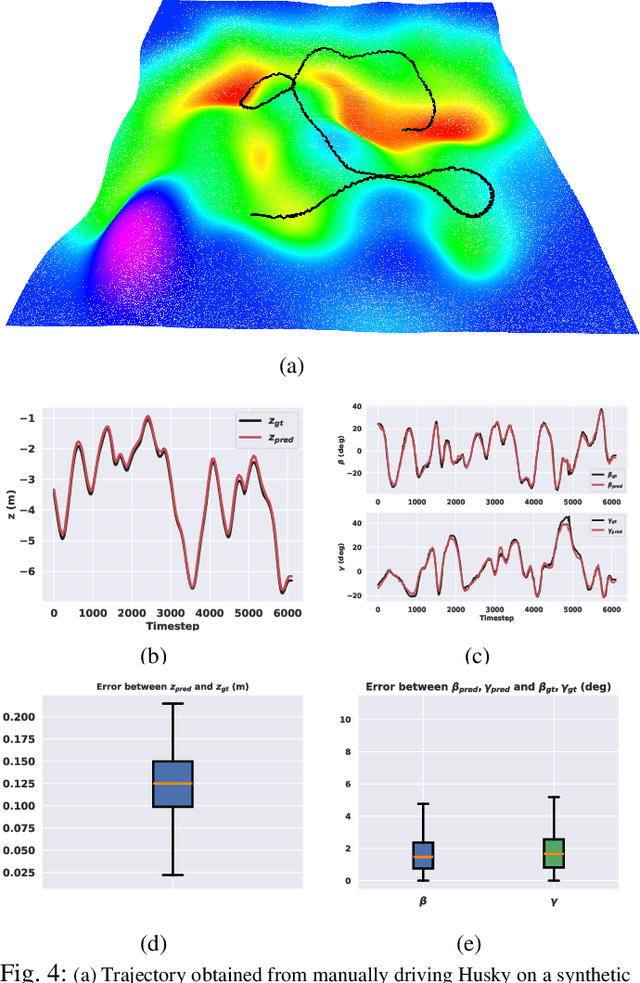
Navigation of wheeled vehicles on uneven terrain necessitates going beyond the 2D approaches for trajectory planning. Specifically, it is essential to incorporate the full 6dof variation of vehicle pose and its associated stability cost in the planning process. To this end, most recent works aim to learn a neural network model to predict the vehicle evolution. However, such approaches are data-intensive and fraught with generalization issues. In this paper, we present a purely model-based approach that just requires the digital elevation information of the terrain. Specifically, we express the wheel-terrain interaction and 6dof pose prediction as a non-linear least squares (NLS) problem. As a result, trajectory planning can be viewed as a bi-level optimization. The inner optimization layer predicts the pose on the terrain along a given trajectory, while the outer layer deforms the trajectory itself to reduce the stability and kinematic costs of the pose. We improve the state-of-the-art in the following respects. First, we show that our NLS based pose prediction closely matches the output from a high-fidelity physics engine. This result coupled with the fact that we can query gradients of the NLS solver, makes our pose predictor, a differentiable wheel-terrain interaction model. We further leverage this differentiability to efficiently solve the proposed bi-level trajectory optimization problem. Finally, we perform extensive experiments, and comparison with a baseline to showcase the effectiveness of our approach in obtaining smooth, stable trajectories.