 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical Vision World Model
Mar 03, 2025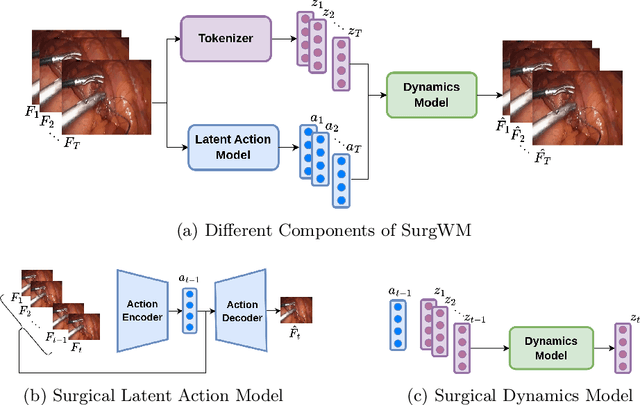
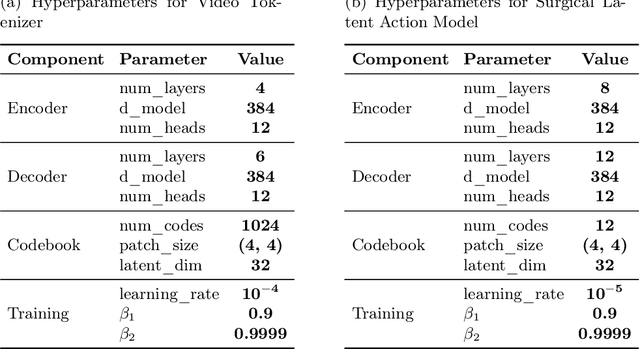
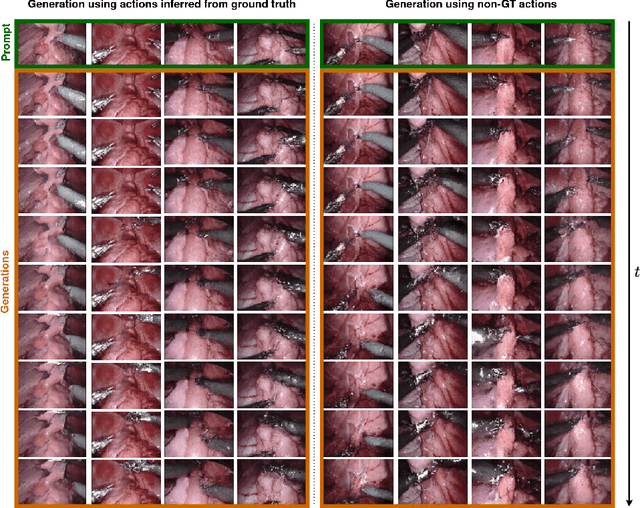
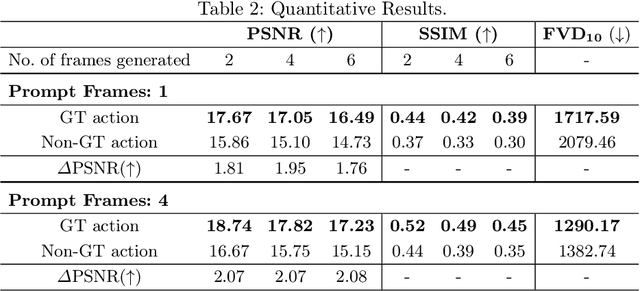
Realistic and interactive surgical simulation has the potential to facilitate crucial applications, such as medical professional training and autonomous surgical agent training. In the natural visual domain, world models have enabled action-controlled data generation, demonstrating the potential to train autonomous agents in interactive simulated environments when large-scale real data acquisition is infeasible. However, such works in the surgical domain have been limited to simplified computer simulations, and lack realism. Furthermore, existing literature in world models has predominantly dealt with action-labeled data, limiting their applicability to real-world surgical data, where obtaining action annotation is prohibitively expensive. Inspired by the recent success of Genie in leveraging unlabeled video game data to infer latent actions and enable action-controlled data generation, we propose the first surgical vision world model. The proposed model can generate action-controllable surgical data and the architecture design is verified with extensive experiments on the unlabeled SurgToolLoc-2022 dataset. Codes and implementation details are available at https://github.com/bhattarailab/Surgical-Vision-World-Model
ReCoRe: Regularized Contrastive Representation Learning of World Model
Dec 14, 2023


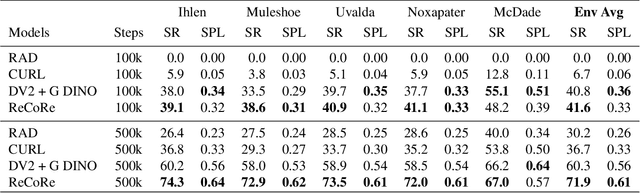
While recent model-free Reinforcement Learning (RL) methods have demonstrated human-level effectiveness in gaming environments, their success in everyday tasks like visual navigation has been limited, particularly under significant appearance variations. This limitation arises from (i) poor sample efficiency and (ii) over-fitting to training scenarios. To address these challenges, we present a world model that learns invariant features using (i) contrastive unsupervised learning and (ii) an intervention-invariant regularizer. Learning an explicit representation of the world dynamics i.e. a world model, improves sample efficiency while contrastive learning implicitly enforces learning of invariant features, which improves generalization. However, the naive integration of contrastive loss to world models fails due to a lack of supervisory signals to the visual encoder, as world-model-based RL methods independently optimize representation learning and agent policy. To overcome this issue, we propose an intervention-invariant regularizer in the form of an auxiliary task such as depth prediction, image denoising, etc., that explicitly enforces invariance to style-interventions. Our method outperforms current state-of-the-art model-based and model-free RL methods and significantly on out-of-distribution point navigation task evaluated on the iGibson benchmark. We further demonstrate that our approach, with only visual observations, outperforms recent language-guided foundation models for point navigation, which is essential for deployment on robots with limited computation capabilities. Finally, we demonstrate that our proposed model excels at the sim-to-real transfer of its perception module on Gibson benchmark.
LanGWM: Language Grounded World Model
Nov 29, 2023Recent advances in deep reinforcement learning have showcased its potential in tackling complex tasks. However, experiments on visual control tasks have revealed that state-of-the-art reinforcement learning models struggle with out-of-distribution generalization. Conversely, expressing higher-level concepts and global contexts is relatively easy using language. Building upon recent success of the large language models, our main objective is to improve the state abstraction technique in reinforcement learning by leveraging language for robust action selection. Specifically, we focus on learning language-grounded visual features to enhance the world model learning, a model-based reinforcement learning technique. To enforce our hypothesis explicitly, we mask out the bounding boxes of a few objects in the image observation and provide the text prompt as descriptions for these masked objects. Subsequently, we predict the masked objects along with the surrounding regions as pixel reconstruction, similar to the transformer-based masked autoencoder approach. Our proposed LanGWM: Language Grounded World Model achieves state-of-the-art performance in out-of-distribution test at the 100K interaction steps benchmarks of iGibson point navigation tasks. Furthermore, our proposed technique of explicit language-grounded visual representation learning has the potential to improve models for human-robot interaction because our extracted visual features are language grounded.
Contrastive Unsupervised Learning of World Model with Invariant Causal Features
Sep 29, 2022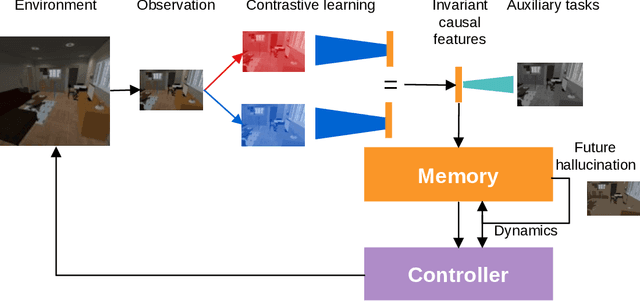
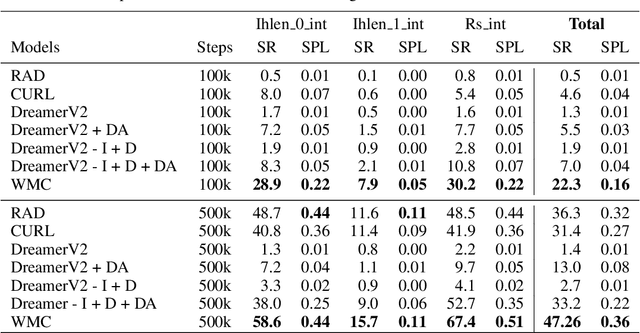
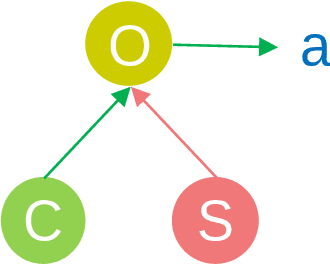
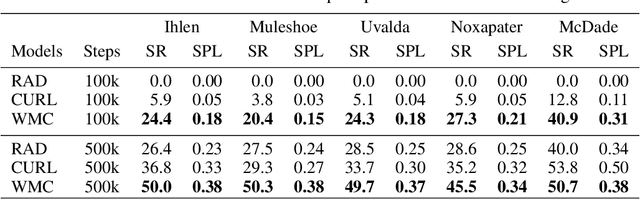
In this paper we present a world model, which learns causal features using the invariance principle. In particular, we use contrastive unsupervised learning to learn the invariant causal features, which enforces invariance across augmentations of irrelevant parts or styles of the observation. The world-model-based reinforcement learning methods independently optimize representation learning and the policy. Thus naive contrastive loss implementation collapses due to a lack of supervisory signals to the representation learning module. We propose an intervention invariant auxiliary task to mitigate this issue. Specifically, we utilize depth prediction to explicitly enforce the invariance and use data augmentation as style intervention on the RGB observation space. Our design leverages unsupervised representation learning to learn the world model with invariant causal features. Our proposed method significantly outperforms current state-of-the-art model-based and model-free reinforcement learning methods on out-of-distribution point navigation tasks on the iGibson dataset. Moreover, our proposed model excels at the sim-to-real transfer of our perception learning module. Finally, we evaluate our approach on the DeepMind control suite and enforce invariance only implicitly since depth is not available. Nevertheless, our proposed model performs on par with the state-of-the-art counterpart.
A Stochastic Bundle Method for Interpolating Networks
Jan 29, 2022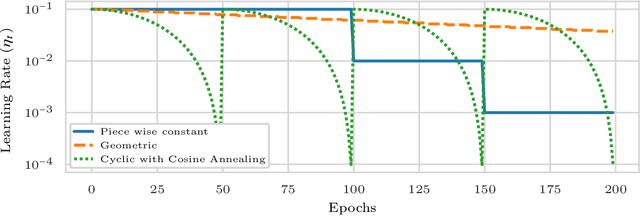
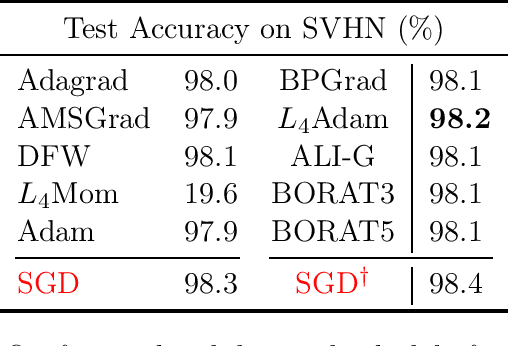
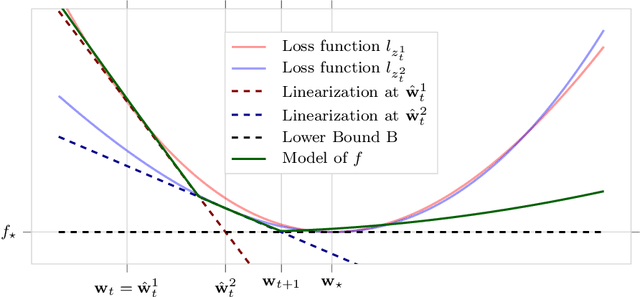
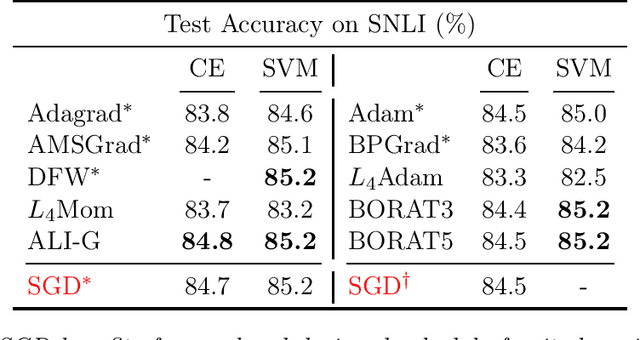
We propose a novel method for training deep neural networks that are capable of interpolation, that is, driving the empirical loss to zero. At each iteration, our method constructs a stochastic approximation of the learning objective. The approximation, known as a bundle, is a pointwise maximum of linear functions. Our bundle contains a constant function that lower bounds the empirical loss. This enables us to compute an automatic adaptive learning rate, thereby providing an accurate solution. In addition, our bundle includes linear approximations computed at the current iterate and other linear estimates of the DNN parameters. The use of these additional approximations makes our method significantly more robust to its hyperparameters. Based on its desirable empirical properties, we term our method Bundle Optimisation for Robust and Accurate Training (BORAT). In order to operationalise BORAT, we design a novel algorithm for optimising the bundle approximation efficiently at each iteration. We establish the theoretical convergence of BORAT in both convex and non-convex settings. Using standard publicly available data sets, we provide a thorough comparison of BORAT to other single hyperparameter optimisation algorithms. Our experiments demonstrate BORAT matches the state-of-the-art generalisation performance for these methods and is the most robust.
Embodied Visual Navigation with Automatic Curriculum Learning in Real Environments
Sep 11, 2020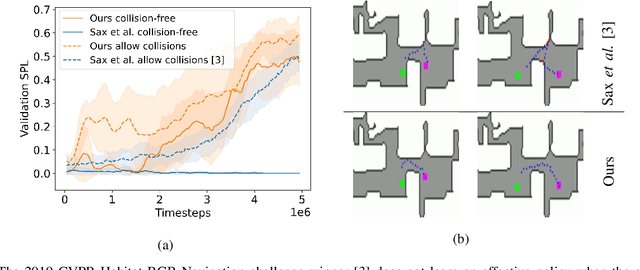
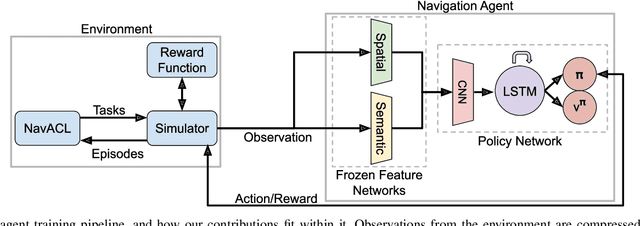
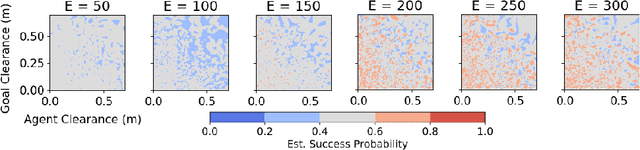
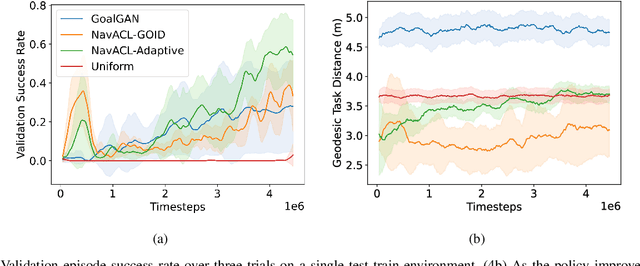
We present NavACL, a method of automatic curriculum learning tailored to the navigation task. NavACL is simple to train and efficiently selects relevant tasks using geometric features. In our experiments, deep reinforcement learning agents trained using NavACL in collision-free environments significantly outperform state-of-the-art agents trained with uniform sampling -- the current standard. Furthermore, our agents are able to navigate through unknown cluttered indoor environments to semantically-specified targets using only RGB images. Collision avoidance policies and frozen feature networks support transfer to unseen real-world environments, without any modification or retraining requirements. We evaluate our policies in simulation, and in the real world on a ground robot and a quadrotor drone. Videos of real-world results are available in the supplementary material