 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time 6-DoF Pose Estimation by an Event-based Camera using Active LED Markers
Oct 25, 2023



Real-time applications for autonomous operations depend largely on fast and robust vision-based localization systems. Since image processing tasks require processing large amounts of data, the computational resources often limit the performance of other processes. To overcome this limitation, traditional marker-based localization systems are widely used since they are easy to integrate and achieve reliable accuracy. However, classical marker-based localization systems significantly depend on standard cameras with low frame rates, which often lack accuracy due to motion blur. In contrast, event-based cameras provide high temporal resolution and a high dynamic range, which can be utilized for fast localization tasks, even under challenging visual conditions. This paper proposes a simple but effective event-based pose estimation system using active LED markers (ALM) for fast and accurate pose estimation. The proposed algorithm is able to operate in real time with a latency below \SI{0.5}{\milli\second} while maintaining output rates of \SI{3}{\kilo \hertz}. Experimental results in static and dynamic scenarios are presented to demonstrate the performance of the proposed approach in terms of computational speed and absolute accuracy, using the OptiTrack system as the basis for measurement.
A CNN Based Approach for the Point-Light Photometric Stereo Problem
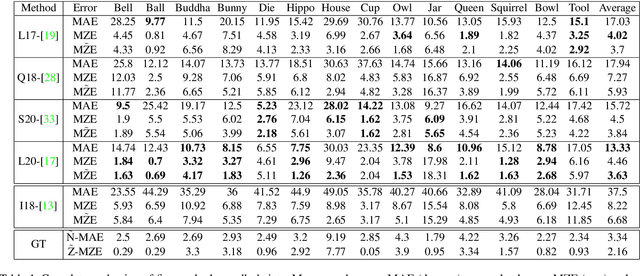
Oct 10, 2022Reconstructing the 3D shape of an object using several images under different light sources is a very challenging task, especially when realistic assumptions such as light propagation and attenuation, perspective viewing geometry and specular light reflection are considered. Many of works tackling Photometric Stereo (PS) problems often relax most of the aforementioned assumptions. Especially they ignore specular reflection and global illumination effects. In this work, we propose a CNN-based approach capable of handling these realistic assumptions by leveraging recent improvements of deep neural networks for far-field Photometric Stereo and adapt them to the point light setup. We achieve this by employing an iterative procedure of point-light PS for shape estimation which has two main steps. Firstly we train a per-pixel CNN to predict surface normals from reflectance samples. Secondly, we compute the depth by integrating the normal field in order to iteratively estimate light directions and attenuation which is used to compensate the input images to compute reflectance samples for the next iteration. Our approach sigificantly outperforms the state-of-the-art on the DiLiGenT real world dataset. Furthermore, in order to measure the performance of our approach for near-field point-light source PS data, we introduce LUCES the first real-world 'dataset for near-fieLd point light soUrCe photomEtric Stereo' of 14 objects of different materials were the effects of point light sources and perspective viewing are a lot more significant. Our approach also outperforms the competition on this dataset as well. Data and test code are available at the project page.
LUCES: A Dataset for Near-Field Point Light Source Photometric Stereo
Apr 27, 2021


Three-dimensional reconstruction of objects from shading information is a challenging task in computer vision. As most of the approaches facing the Photometric Stereo problem use simplified far-field assumptions, real-world scenarios have essentially more complex physical effects that need to be handled for accurately reconstructing the 3D shape. An increasing number of methods have been proposed to address the problem when point light sources are assumed to be nearby the target object. The proximity of the light sources complicates the modeling of the image formation as the light behaviour requires non-linear parameterisation to describe its propagation and attenuation. To understand the capability of the approaches dealing with this near-field scenario, the literature till now has used synthetically rendered photometric images or minimal and very customised real-world data. In order to fill the gap in evaluating near-field photometric stereo methods, we introduce LUCES the first real-world 'dataset for near-fieLd point light soUrCe photomEtric Stereo' of 14 objects of a varying of materials. A device counting 52 LEDs has been designed to lit each object positioned 10 to 30 centimeters away from the camera. Together with the raw images, in order to evaluate the 3D reconstructions, the dataset includes both normal and depth maps for comparing different features of the retrieved 3D geometry. Furthermore, we evaluate the performance of the latest near-field Photometric Stereo algorithms on the proposed dataset to assess the SOTA method with respect to actual close range effects and object materials.
A CNN Based Approach for the Near-Field Photometric Stereo Problem
Sep 12, 2020
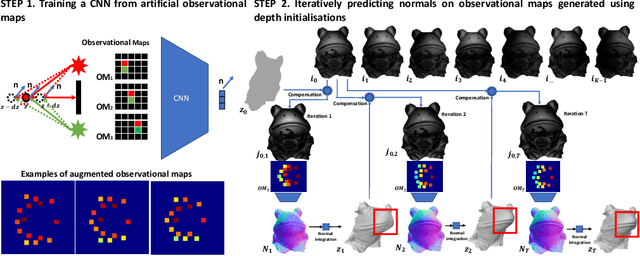
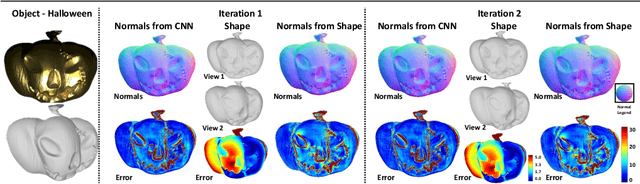
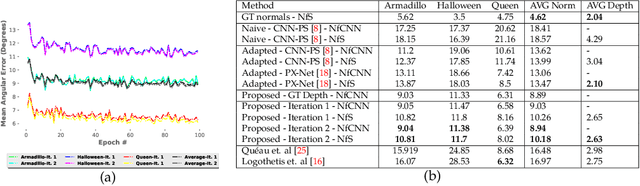
Reconstructing the 3D shape of an object using several images under different light sources is a very challenging task, especially when realistic assumptions such as light propagation and attenuation, perspective viewing geometry and specular light reflection are considered. Many of works tackling Photometric Stereo (PS) problems often relax most of the aforementioned assumptions. Especially they ignore specular reflection and global illumination effects. In this work, we propose the first CNN based approach capable of handling these realistic assumptions in Photometric Stereo. We leverage recent improvements of deep neural networks for far-field Photometric Stereo and adapt them to near field setup. We achieve this by employing an iterative procedure for shape estimation which has two main steps. Firstly we train a per-pixel CNN to predict surface normals from reflectance samples. Secondly, we compute the depth by integrating the normal field in order to iteratively estimate light directions and attenuation which is used to compensate the input images to compute reflectance samples for the next iteration. To the best of our knowledge this is the first near-field framework which is able to accurately predict 3D shape from highly specular objects. Our method outperforms competing state-of-the-art near-field Photometric Stereo approaches on both synthetic and real experiments.
Embodied Visual Navigation with Automatic Curriculum Learning in Real Environments
Sep 11, 2020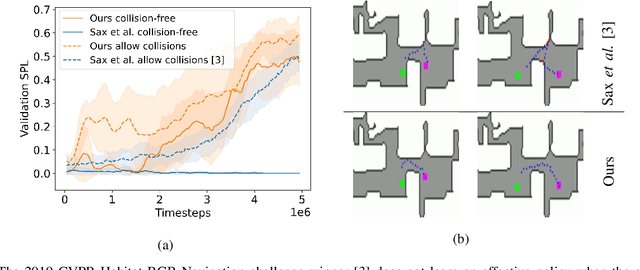
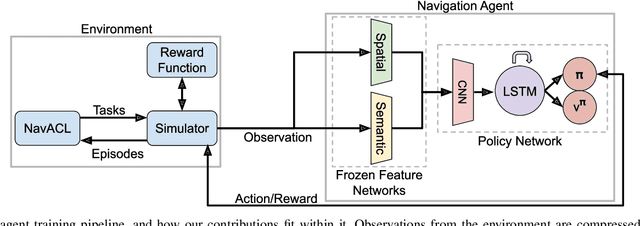
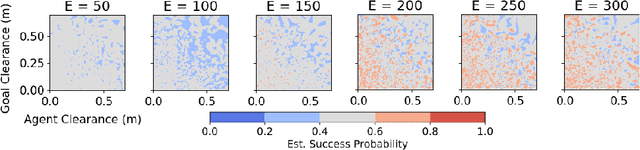
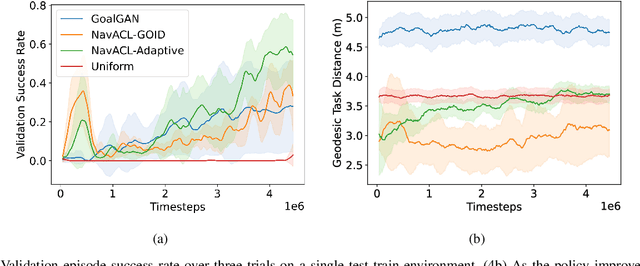
We present NavACL, a method of automatic curriculum learning tailored to the navigation task. NavACL is simple to train and efficiently selects relevant tasks using geometric features. In our experiments, deep reinforcement learning agents trained using NavACL in collision-free environments significantly outperform state-of-the-art agents trained with uniform sampling -- the current standard. Furthermore, our agents are able to navigate through unknown cluttered indoor environments to semantically-specified targets using only RGB images. Collision avoidance policies and frozen feature networks support transfer to unseen real-world environments, without any modification or retraining requirements. We evaluate our policies in simulation, and in the real world on a ground robot and a quadrotor drone. Videos of real-world results are available in the supplementary material
PX-NET: Simple, Efficient Pixel-Wise Training of Photometric Stereo Networks
Aug 11, 2020
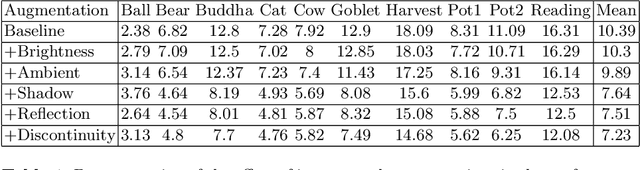
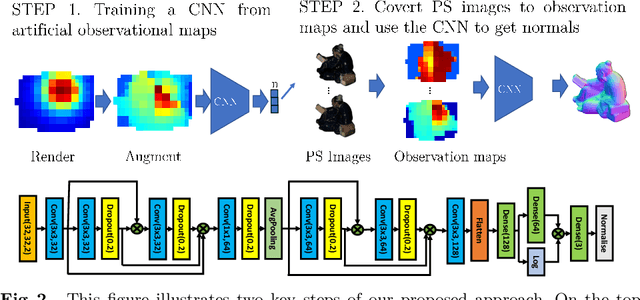
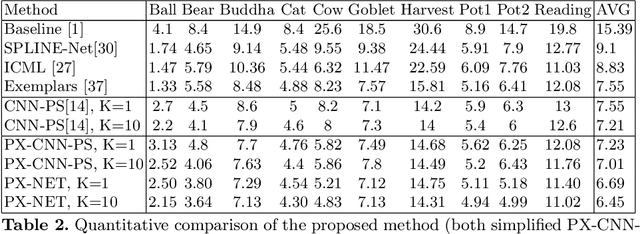
Retrieving accurate 3D reconstructions of objects from the way they reflect light is a very challenging task in computer vision. Despite more than four decades since the definition of the Photometric Stereo problem, most of the literature has had limited success when global illumination effects such as cast shadows, self-reflections and ambient light come into play, especially for specular surfaces. Recent approaches have leveraged the power of deep learning in conjunction with computer graphics in order to cope with the need of a vast number of training data in order to invert the image irradiance equation and retrieve the geometry of the object. However, rendering global illumination effects is a slow process which can limit the amount of training data that can be generated. In this work we propose a novel pixel-wise training procedure for normal prediction by replacing the training data of globally rendered images with independent per-pixel renderings. We show that robustness to global physical effects can be achieved via data-augmentation which greatly simplifies and speeds up the data creation procedure. Our network, PX-NET, achieves the state-of-the-art performance on synthetic datasets, as well as the Diligent real dataset.
A Differential Volumetric Approach to Multi-View Photometric Stereo
Nov 05, 2018
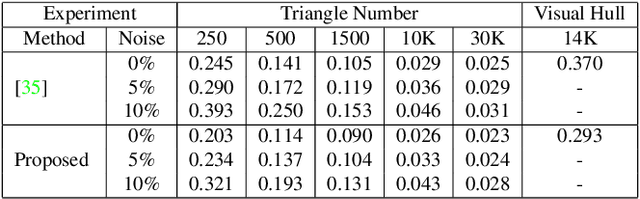

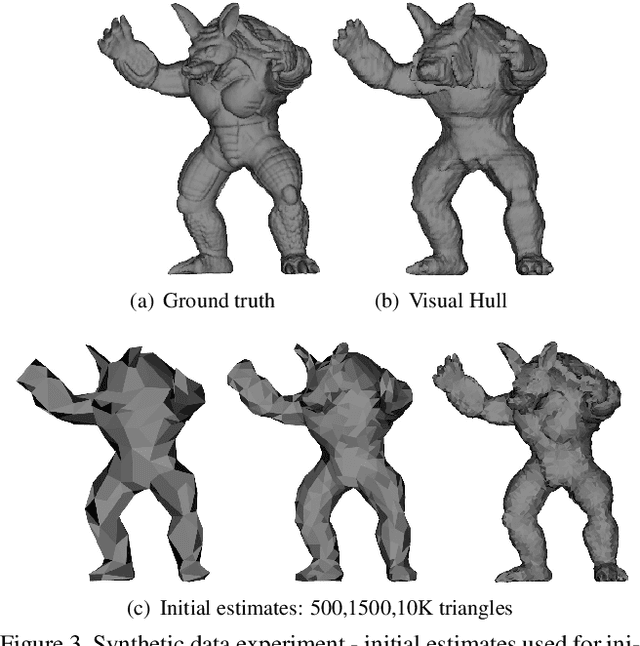
Highly accurate 3D volumetric reconstruction is still an open research topic where the main difficulties are usually related to merging rough estimations with high frequency details. One of the most promising methods is the fusion between multi-view stereo and photometric imaging 3D shape reconstruction techniques. However, beside the intrinsic difficulties that multi-view stereo and photometric stereo have to make them working reliably, supplementary problems raise when considered together. Most importantly, the projection of the fine details usually retrievable with photometric stereo onto the rough multi-view stereo reconstruction is difficult to handle. In this work, we present a volumetric approach to the multi-view photometric stereo problem defined by a unified differential model. The key to our method is the signed distance field parameterisation which avoids the complex step of re-projecting high frequency details as the parameterisation of the whole volume allows a photometric modeling on the volume itself efficiently dealing with occlusions, discontinuities, etc. The relation between the surface normals and the gradient of the signed distance field leads to a homogeneous linear partial differential equation. A variational optimisation is adopted in order to combine multiple images from multiple points of view in a single system avoiding the need of merging depth maps. Our approach is evaluated on synthetic and real data-sets and achieves state-of-the-art results.