 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Multi-Concept Image Editing
Feb 24, 2026Editing images with diffusion models without training remains challenging. While recent optimisation-based methods achieve strong zero-shot edits from text, they struggle to preserve identity or capture details that language alone cannot express. Many visual concepts such as facial structure, material texture, or object geometry are impossible to express purely through text prompts alone. To address this gap, we introduce a training-free framework for concept-based image editing, which unifies Optimised DDS with LoRA-driven concept composition, where the training data of the LoRA represent the concept. Our approach enables combining and controlling multiple visual concepts directly within the diffusion process, integrating semantic guidance from text with low-level cues from pretrained concept adapters. We further refine DDS for stability and controllability through ordered timesteps, regularisation, and negative-prompt guidance. Quantitative and qualitative results demonstrate consistent improvements over existing training-free diffusion editing methods on InstructPix2Pix and ComposLoRA benchmarks. Code will be made publicly available.
LUCES-MV: A Multi-View Dataset for Near-Field Point Light Source Photometric Stereo
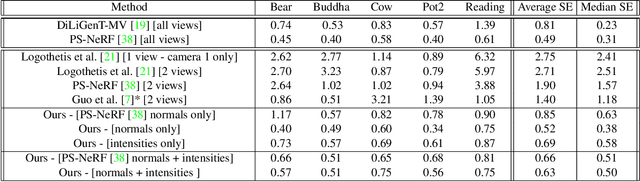
Dec 21, 2024The biggest improvements in Photometric Stereo (PS) field has recently come from adoption of differentiable volumetric rendering techniques such as NeRF or Neural SDF achieving impressive reconstruction error of 0.2mm on DiLiGenT-MV benchmark. However, while there are sizeable datasets for environment lit objects such as Digital Twin Catalogue (DTS), there are only several small Photometric Stereo datasets which often lack challenging objects (simple, smooth, untextured) and practical, small form factor (near-field) light setup. To address this, we propose LUCES-MV, the first real-world, multi-view dataset designed for near-field point light source photometric stereo. Our dataset includes 15 objects with diverse materials, each imaged under varying light conditions from an array of 15 LEDs positioned 30 to 40 centimeters from the camera center. To facilitate transparent end-to-end evaluation, our dataset provides not only ground truth normals and ground truth object meshes and poses but also light and camera calibration images. We evaluate state-of-the-art near-field photometric stereo algorithms, highlighting their strengths and limitations across different material and shape complexities. LUCES-MV dataset offers an important benchmark for developing more robust, accurate and scalable real-world Photometric Stereo based 3D reconstruction methods.
NPLMV-PS: Neural Point-Light Multi-View Photometric Stereo
May 20, 2024


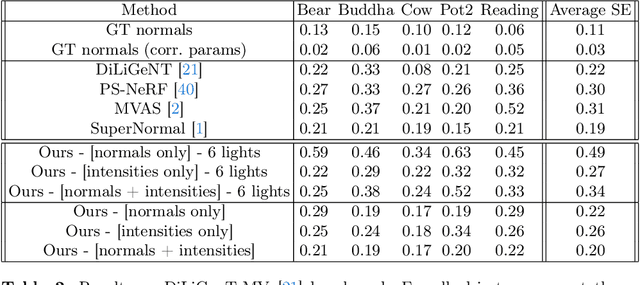
In this work we present a novel multi-view photometric stereo (PS) method. Like many works in 3D reconstruction we are leveraging neural shape representations and learnt renderers. However, our work differs from the state-of-the-art multi-view PS methods such as PS-NeRF or SuperNormal we explicity leverage per-pixel intensity renderings rather than relying mainly on estimated normals. We model point light attenuation and explicitly raytrace cast shadows in order to best approximate each points incoming radiance. This is used as input to a fully neural material renderer that uses minimal prior assumptions and it is jointly optimised with the surface. Finally, estimated normal and segmentation maps can also incorporated in order to maximise the surface accuracy. Our method is among the first to outperform the classical approach of DiLiGenT-MV and achieves average 0.2mm Chamfer distance for objects imaged at approx 1.5m distance away with approximate 400x400 resolution. Moreover, we show robustness to poor normals in low light count scenario, achieving 0.27mm Chamfer distance when pixel rendering is used instead of estimated normals.
VRS-NeRF: Visual Relocalization with Sparse Neural Radiance Field
Apr 14, 2024



Visual relocalization is a key technique to autonomous driving, robotics, and virtual/augmented reality. After decades of explorations, absolute pose regression (APR), scene coordinate regression (SCR), and hierarchical methods (HMs) have become the most popular frameworks. However, in spite of high efficiency, APRs and SCRs have limited accuracy especially in large-scale outdoor scenes; HMs are accurate but need to store a large number of 2D descriptors for matching, resulting in poor efficiency. In this paper, we propose an efficient and accurate framework, called VRS-NeRF, for visual relocalization with sparse neural radiance field. Precisely, we introduce an explicit geometric map (EGM) for 3D map representation and an implicit learning map (ILM) for sparse patches rendering. In this localization process, EGP provides priors of spare 2D points and ILM utilizes these sparse points to render patches with sparse NeRFs for matching. This allows us to discard a large number of 2D descriptors so as to reduce the map size. Moreover, rendering patches only for useful points rather than all pixels in the whole image reduces the rendering time significantly. This framework inherits the accuracy of HMs and discards their low efficiency. Experiments on 7Scenes, CambridgeLandmarks, and Aachen datasets show that our method gives much better accuracy than APRs and SCRs, and close performance to HMs but is much more efficient.
PRAM: Place Recognition Anywhere Model for Efficient Visual Localization
Apr 11, 2024



Humans localize themselves efficiently in known environments by first recognizing landmarks defined on certain objects and their spatial relationships, and then verifying the location by aligning detailed structures of recognized objects with those in the memory. Inspired by this, we propose the place recognition anywhere model (PRAM) to perform visual localization as efficiently as humans do. PRAM consists of two main components - recognition and registration. In detail, first of all, a self-supervised map-centric landmark definition strategy is adopted, making places in either indoor or outdoor scenes act as unique landmarks. Then, sparse keypoints extracted from images, are utilized as the input to a transformer-based deep neural network for landmark recognition; these keypoints enable PRAM to recognize hundreds of landmarks with high time and memory efficiency. Keypoints along with recognized landmark labels are further used for registration between query images and the 3D landmark map. Different from previous hierarchical methods, PRAM discards global and local descriptors, and reduces over 90% storage. Since PRAM utilizes recognition and landmark-wise verification to replace global reference search and exhaustive matching respectively, it runs 2.4 times faster than prior state-of-the-art approaches. Moreover, PRAM opens new directions for visual localization including multi-modality localization, map-centric feature learning, and hierarchical scene coordinate regression.
Task Agnostic Architecture for Algorithm Induction via Implicit Composition
Apr 03, 2024Different fields in applied machine learning such as computer vision, speech or natural language processing have been building domain-specialised solutions. Currently, we are witnessing an opposing trend towards developing more generalist architectures, driven by Large Language Models and multi-modal foundational models. These architectures are designed to tackle a variety of tasks, including those previously unseen and using inputs across multiple modalities. Taking this trend of generalization to the extreme suggests the possibility of a single deep network architecture capable of solving all tasks. This position paper aims to explore developing such a unified architecture and proposes a theoretical framework of how it could be constructed. Our proposal is based on the following assumptions. Firstly, tasks are solved by following a sequence of instructions, typically implemented in code for conventional computing hardware, which inherently operates sequentially. Second, recent Generative AI, especially Transformer-based models, demonstrate potential as an architecture capable of constructing algorithms for a wide range of domains. For example, GPT-4 shows exceptional capability at in-context learning of novel tasks which is hard to explain in any other way than the ability to compose novel solutions from fragments on previously learnt algorithms. Third, the observation that the main missing component in developing a truly generalised network is an efficient approach for self-consistent input of previously learnt sub-steps of an algorithm and their (implicit) composition during the network's internal forward pass. Our exploration delves into current capabilities and limitations of Transformer-based and other methods in efficient and correct algorithm composition and proposes a Transformer-like architecture as well as a discrete learning framework to overcome these limitations.
DiaLoc: An Iterative Approach to Embodied Dialog Localization
Mar 11, 2024Multimodal learning has advanced the performance for many vision-language tasks. However, most existing works in embodied dialog research focus on navigation and leave the localization task understudied. The few existing dialog-based localization approaches assume the availability of entire dialog prior to localizaiton, which is impractical for deployed dialog-based localization. In this paper, we propose DiaLoc, a new dialog-based localization framework which aligns with a real human operator behavior. Specifically, we produce an iterative refinement of location predictions which can visualize current pose believes after each dialog turn. DiaLoc effectively utilizes the multimodal data for multi-shot localization, where a fusion encoder fuses vision and dialog information iteratively. We achieve state-of-the-art results on embodied dialog-based localization task, in single-shot (+7.08% in Acc5@valUnseen) and multi-shot settings (+10.85% in Acc5@valUnseen). DiaLoc narrows the gap between simulation and real-world applications, opening doors for future research on collaborative localization and navigation.
Function-constrained Program Synthesis
Dec 04, 2023



This work introduces (1) a technique that allows large language models (LLMs) to leverage user-provided code when solving programming tasks and (2) a method to iteratively generate modular sub-functions that can aid future code generation attempts when the initial code generated by the LLM is inadequate. Generating computer programs in general-purpose programming languages like Python poses a challenge for LLMs when instructed to use code provided in the prompt. Code-specific LLMs (e.g., GitHub Copilot, CodeLlama2) can generate code completions in real-time by drawing on all code available in a development environment. However, restricting code-specific LLMs to use only in-context code is not straightforward, as the model is not explicitly instructed to use the user-provided code and users cannot highlight precisely which snippets of code the model should incorporate into its context. Moreover, current systems lack effective recovery methods, forcing users to iteratively re-prompt the model with modified prompts until a sufficient solution is reached. Our method differs from traditional LLM-powered code-generation by constraining code-generation to an explicit function set and enabling recovery from failed attempts through automatically generated sub-functions. When the LLM cannot produce working code, we generate modular sub-functions to aid subsequent attempts at generating functional code. A by-product of our method is a library of reusable sub-functions that can solve related tasks, imitating a software team where efficiency scales with experience. We also introduce a new "half-shot" evaluation paradigm that provides tighter estimates of LLMs' coding abilities compared to traditional zero-shot evaluation. Our proposed evaluation method encourages models to output solutions in a structured format, decreasing syntax errors that can be mistaken for poor coding ability.
A Neural Height-Map Approach for the Binocular Photometric Stereo Problem
Nov 10, 2023
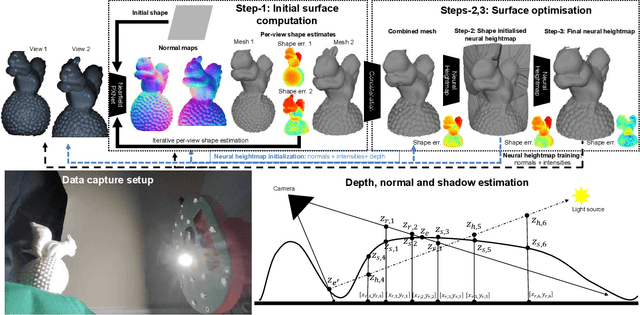
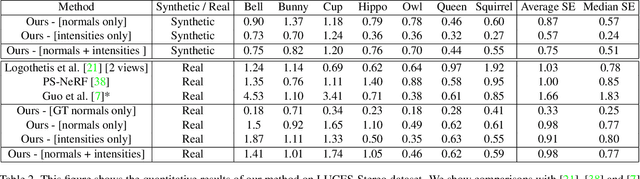
In this work we propose a novel, highly practical, binocular photometric stereo (PS) framework, which has same acquisition speed as single view PS, however significantly improves the quality of the estimated geometry. As in recent neural multi-view shape estimation frameworks such as NeRF, SIREN and inverse graphics approaches to multi-view photometric stereo (e.g. PS-NeRF) we formulate shape estimation task as learning of a differentiable surface and texture representation by minimising surface normal discrepancy for normals estimated from multiple varying light images for two views as well as discrepancy between rendered surface intensity and observed images. Our method differs from typical multi-view shape estimation approaches in two key ways. First, our surface is represented not as a volume but as a neural heightmap where heights of points on a surface are computed by a deep neural network. Second, instead of predicting an average intensity as PS-NeRF or introducing lambertian material assumptions as Guo et al., we use a learnt BRDF and perform near-field per point intensity rendering. Our method achieves the state-of-the-art performance on the DiLiGenT-MV dataset adapted to binocular stereo setup as well as a new binocular photometric stereo dataset - LUCES-ST.
Sparse Multi-Object Render-and-Compare
Oct 17, 2023
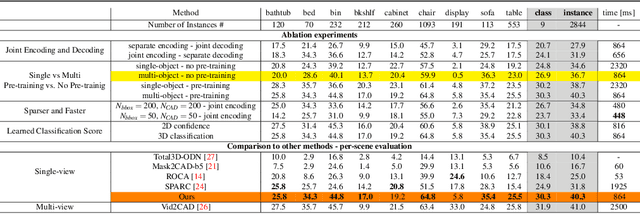
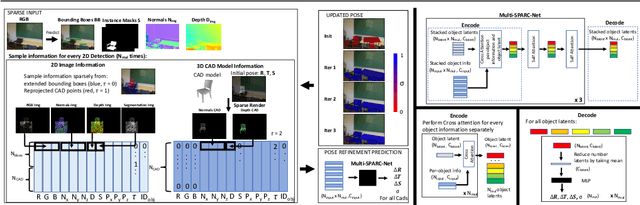

Reconstructing 3D shape and pose of static objects from a single image is an essential task for various industries, including robotics, augmented reality, and digital content creation. This can be done by directly predicting 3D shape in various representations or by retrieving CAD models from a database and predicting their alignments. Directly predicting 3D shapes often produces unrealistic, overly smoothed or tessellated shapes. Retrieving CAD models ensures realistic shapes but requires robust and accurate alignment. Learning to directly predict CAD model poses from image features is challenging and inaccurate. Works, such as ROCA, compute poses from predicted normalised object coordinates which can be more accurate but are susceptible to systematic failure. SPARC demonstrates that following a ''render-and-compare'' approach where a network iteratively improves upon its own predictions achieves accurate alignments. Nevertheless, it performs individual CAD alignment for every object detected in an image. This approach is slow when applied to many objects as the time complexity increases linearly with the number of objects and can not learn inter-object relations. Introducing a new network architecture Multi-SPARC we learn to perform CAD model alignments for multiple detected objects jointly. Compared to other single-view methods we achieve state-of-the-art performance on the challenging real-world dataset ScanNet. By improving the instance alignment accuracy from 31.8% to 40.3% we perform similar to state-of-the-art multi-view methods.