 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffHuman: Probabilistic Photorealistic 3D Reconstruction of Humans
Mar 30, 2024

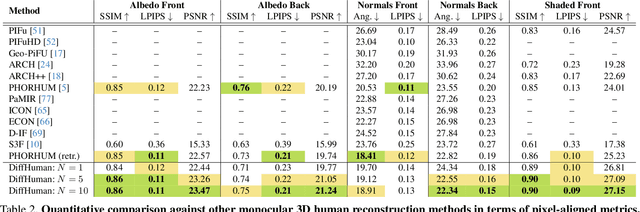

We present DiffHuman, a probabilistic method for photorealistic 3D human reconstruction from a single RGB image. Despite the ill-posed nature of this problem, most methods are deterministic and output a single solution, often resulting in a lack of geometric detail and blurriness in unseen or uncertain regions. In contrast, DiffHuman predicts a probability distribution over 3D reconstructions conditioned on an input 2D image, which allows us to sample multiple detailed 3D avatars that are consistent with the image. DiffHuman is implemented as a conditional diffusion model that denoises pixel-aligned 2D observations of an underlying 3D shape representation. During inference, we may sample 3D avatars by iteratively denoising 2D renders of the predicted 3D representation. Furthermore, we introduce a generator neural network that approximates rendering with considerably reduced runtime (55x speed up), resulting in a novel dual-branch diffusion framework. Our experiments show that DiffHuman can produce diverse and detailed reconstructions for the parts of the person that are unseen or uncertain in the input image, while remaining competitive with the state-of-the-art when reconstructing visible surfaces.
HuManiFlow: Ancestor-Conditioned Normalising Flows on SO(3) Manifolds for Human Pose and Shape Distribution Estimation
May 11, 2023Monocular 3D human pose and shape estimation is an ill-posed problem since multiple 3D solutions can explain a 2D image of a subject. Recent approaches predict a probability distribution over plausible 3D pose and shape parameters conditioned on the image. We show that these approaches exhibit a trade-off between three key properties: (i) accuracy - the likelihood of the ground-truth 3D solution under the predicted distribution, (ii) sample-input consistency - the extent to which 3D samples from the predicted distribution match the visible 2D image evidence, and (iii) sample diversity - the range of plausible 3D solutions modelled by the predicted distribution. Our method, HuManiFlow, predicts simultaneously accurate, consistent and diverse distributions. We use the human kinematic tree to factorise full body pose into ancestor-conditioned per-body-part pose distributions in an autoregressive manner. Per-body-part distributions are implemented using normalising flows that respect the manifold structure of SO(3), the Lie group of per-body-part poses. We show that ill-posed, but ubiquitous, 3D point estimate losses reduce sample diversity, and employ only probabilistic training losses. Code is available at: https://github.com/akashsengupta1997/HuManiFlow.
Probabilistic Estimation of 3D Human Shape and Pose with a Semantic Local Parametric Model
Nov 30, 2021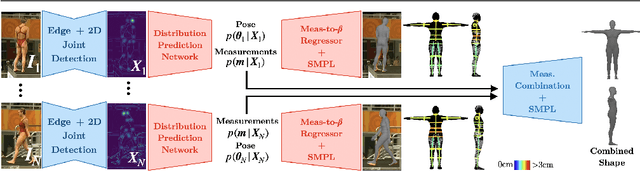
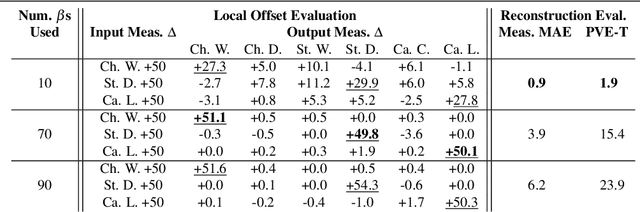

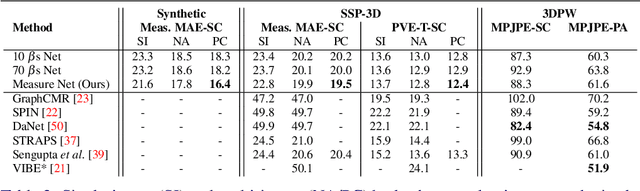
This paper addresses the problem of 3D human body shape and pose estimation from RGB images. Some recent approaches to this task predict probability distributions over human body model parameters conditioned on the input images. This is motivated by the ill-posed nature of the problem wherein multiple 3D reconstructions may match the image evidence, particularly when some parts of the body are locally occluded. However, body shape parameters in widely-used body models (e.g. SMPL) control global deformations over the whole body surface. Distributions over these global shape parameters are unable to meaningfully capture uncertainty in shape estimates associated with locally-occluded body parts. In contrast, we present a method that (i) predicts distributions over local body shape in the form of semantic body measurements and (ii) uses a linear mapping to transform a local distribution over body measurements to a global distribution over SMPL shape parameters. We show that our method outperforms the current state-of-the-art in terms of identity-dependent body shape estimation accuracy on the SSP-3D dataset, and a private dataset of tape-measured humans, by probabilistically-combining local body measurement distributions predicted from multiple images of a subject.
Hierarchical Kinematic Probability Distributions for 3D Human Shape and Pose Estimation from Images in the Wild
Oct 03, 2021
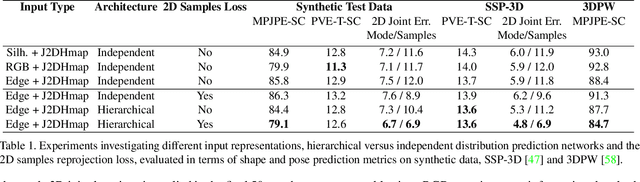
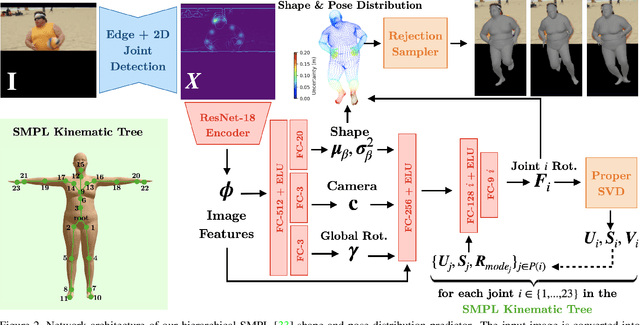
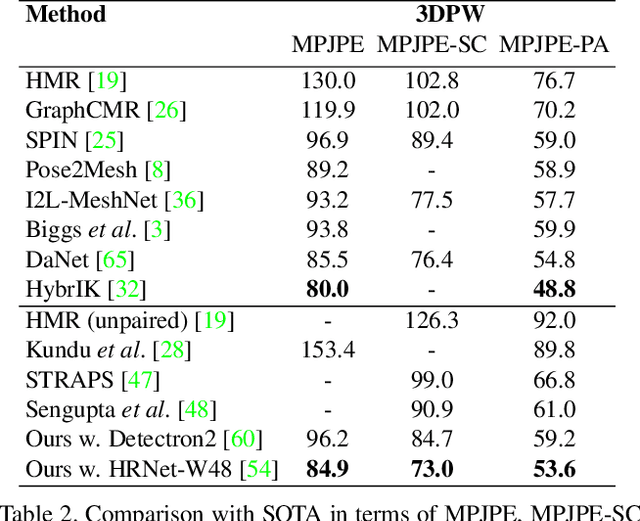
This paper addresses the problem of 3D human body shape and pose estimation from an RGB image. This is often an ill-posed problem, since multiple plausible 3D bodies may match the visual evidence present in the input - particularly when the subject is occluded. Thus, it is desirable to estimate a distribution over 3D body shape and pose conditioned on the input image instead of a single 3D reconstruction. We train a deep neural network to estimate a hierarchical matrix-Fisher distribution over relative 3D joint rotation matrices (i.e. body pose), which exploits the human body's kinematic tree structure, as well as a Gaussian distribution over SMPL body shape parameters. To further ensure that the predicted shape and pose distributions match the visual evidence in the input image, we implement a differentiable rejection sampler to impose a reprojection loss between ground-truth 2D joint coordinates and samples from the predicted distributions, projected onto the image plane. We show that our method is competitive with the state-of-the-art in terms of 3D shape and pose metrics on the SSP-3D and 3DPW datasets, while also yielding a structured probability distribution over 3D body shape and pose, with which we can meaningfully quantify prediction uncertainty and sample multiple plausible 3D reconstructions to explain a given input image. Code is available at https://github.com/akashsengupta1997/HierarchicalProbabilistic3DHuman .
Probabilistic 3D Human Shape and Pose Estimation from Multiple Unconstrained Images in the Wild
Mar 30, 2021
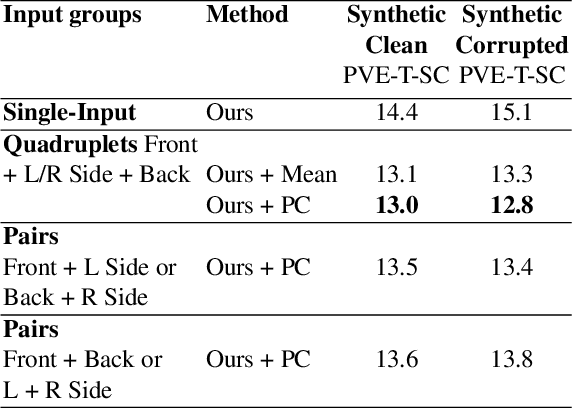
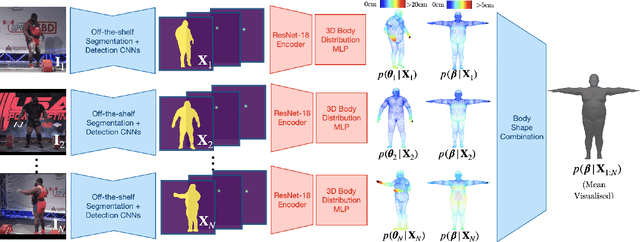
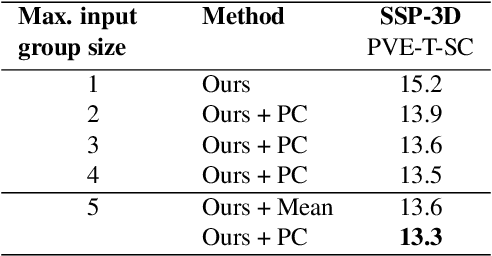
This paper addresses the problem of 3D human body shape and pose estimation from RGB images. Recent progress in this field has focused on single images, video or multi-view images as inputs. In contrast, we propose a new task: shape and pose estimation from a group of multiple images of a human subject, without constraints on subject pose, camera viewpoint or background conditions between images in the group. Our solution to this task predicts distributions over SMPL body shape and pose parameters conditioned on the input images in the group. We probabilistically combine predicted body shape distributions from each image to obtain a final multi-image shape prediction. We show that the additional body shape information present in multi-image input groups improves 3D human shape estimation metrics compared to single-image inputs on the SSP-3D dataset and a private dataset of tape-measured humans. In addition, predicting distributions over 3D bodies allows us to quantify pose prediction uncertainty, which is useful when faced with challenging input images with significant occlusion. Our method demonstrates meaningful pose uncertainty on the 3DPW dataset and is competitive with the state-of-the-art in terms of pose estimation metrics.
Synthetic Training for Accurate 3D Human Pose and Shape Estimation in the Wild
Sep 22, 2020

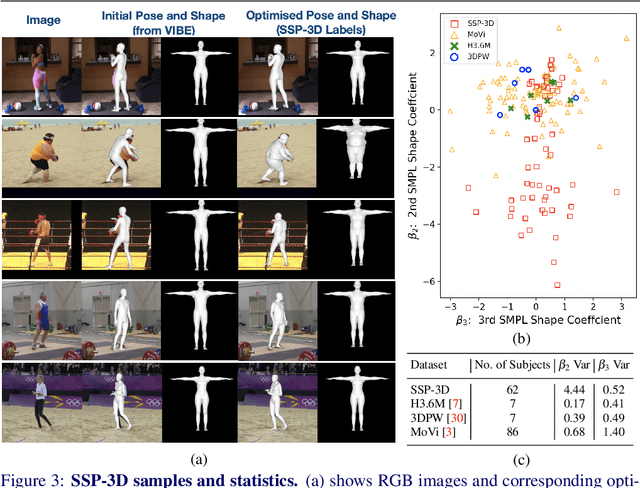

This paper addresses the problem of monocular 3D human shape and pose estimation from an RGB image. Despite great progress in this field in terms of pose prediction accuracy, state-of-the-art methods often predict inaccurate body shapes. We suggest that this is primarily due to the scarcity of in-the-wild training data with diverse and accurate body shape labels. Thus, we propose STRAPS (Synthetic Training for Real Accurate Pose and Shape), a system that utilises proxy representations, such as silhouettes and 2D joints, as inputs to a shape and pose regression neural network, which is trained with synthetic training data (generated on-the-fly during training using the SMPL statistical body model) to overcome data scarcity. We bridge the gap between synthetic training inputs and noisy real inputs, which are predicted by keypoint detection and segmentation CNNs at test-time, by using data augmentation and corruption during training. In order to evaluate our approach, we curate and provide a challenging evaluation dataset for monocular human shape estimation, Sports Shape and Pose 3D (SSP-3D). It consists of RGB images of tightly-clothed sports-persons with a variety of body shapes and corresponding pseudo-ground-truth SMPL shape and pose parameters, obtained via multi-frame optimisation. We show that STRAPS outperforms other state-of-the-art methods on SSP-3D in terms of shape prediction accuracy, while remaining competitive with the state-of-the-art on pose-centric datasets and metrics.