 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstant 3D Human Avatar Generation using Image Diffusion Models
Jun 11, 2024
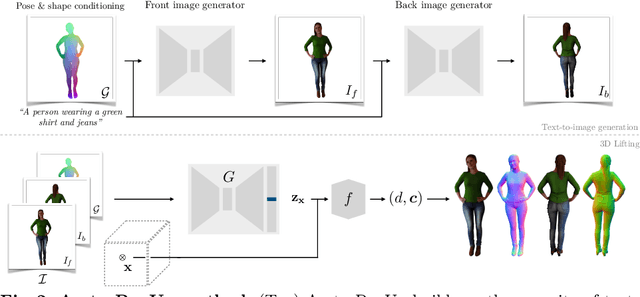
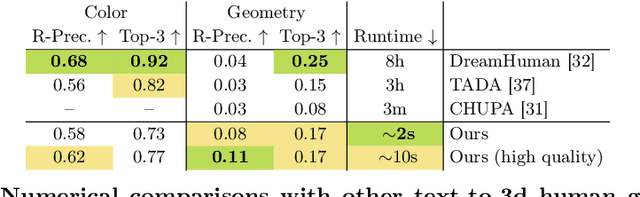
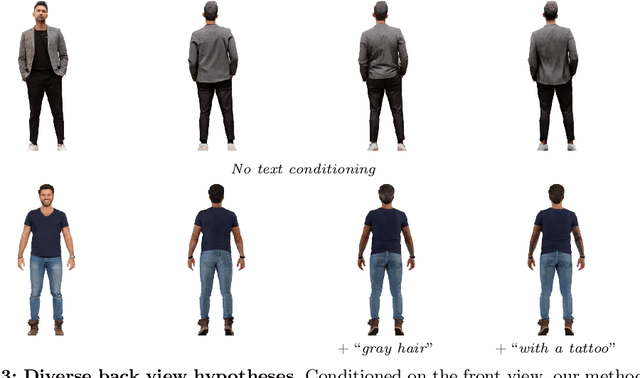
We present AvatarPopUp, a method for fast, high quality 3D human avatar generation from different input modalities, such as images and text prompts and with control over the generated pose and shape. The common theme is the use of diffusion-based image generation networks that are specialized for each particular task, followed by a 3D lifting network. We purposefully decouple the generation from the 3D modeling which allow us to leverage powerful image synthesis priors, trained on billions of text-image pairs. We fine-tune latent diffusion networks with additional image conditioning to solve tasks such as image generation and back-view prediction, and to support qualitatively different multiple 3D hypotheses. Our partial fine-tuning approach allows to adapt the networks for each task without inducing catastrophic forgetting. In our experiments, we demonstrate that our method produces accurate, high-quality 3D avatars with diverse appearance that respect the multimodal text, image, and body control signals. Our approach can produce a 3D model in as few as 2 seconds, a four orders of magnitude speedup w.r.t. the vast majority of existing methods, most of which solve only a subset of our tasks, and with fewer controls, thus enabling applications that require the controlled 3D generation of human avatars at scale. The project website can be found at https://www.nikoskolot.com/avatarpopup/.
DiffHuman: Probabilistic Photorealistic 3D Reconstruction of Humans
Mar 30, 2024

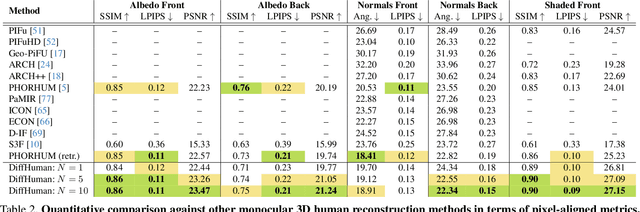

We present DiffHuman, a probabilistic method for photorealistic 3D human reconstruction from a single RGB image. Despite the ill-posed nature of this problem, most methods are deterministic and output a single solution, often resulting in a lack of geometric detail and blurriness in unseen or uncertain regions. In contrast, DiffHuman predicts a probability distribution over 3D reconstructions conditioned on an input 2D image, which allows us to sample multiple detailed 3D avatars that are consistent with the image. DiffHuman is implemented as a conditional diffusion model that denoises pixel-aligned 2D observations of an underlying 3D shape representation. During inference, we may sample 3D avatars by iteratively denoising 2D renders of the predicted 3D representation. Furthermore, we introduce a generator neural network that approximates rendering with considerably reduced runtime (55x speed up), resulting in a novel dual-branch diffusion framework. Our experiments show that DiffHuman can produce diverse and detailed reconstructions for the parts of the person that are unseen or uncertain in the input image, while remaining competitive with the state-of-the-art when reconstructing visible surfaces.
VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
Mar 13, 2024We propose VLOGGER, a method for audio-driven human video generation from a single input image of a person, which builds on the success of recent generative diffusion models. Our method consists of 1) a stochastic human-to-3d-motion diffusion model, and 2) a novel diffusion-based architecture that augments text-to-image models with both spatial and temporal controls. This supports the generation of high quality video of variable length, easily controllable through high-level representations of human faces and bodies. In contrast to previous work, our method does not require training for each person, does not rely on face detection and cropping, generates the complete image (not just the face or the lips), and considers a broad spectrum of scenarios (e.g. visible torso or diverse subject identities) that are critical to correctly synthesize humans who communicate. We also curate MENTOR, a new and diverse dataset with 3d pose and expression annotations, one order of magnitude larger than previous ones (800,000 identities) and with dynamic gestures, on which we train and ablate our main technical contributions. VLOGGER outperforms state-of-the-art methods in three public benchmarks, considering image quality, identity preservation and temporal consistency while also generating upper-body gestures. We analyze the performance of VLOGGER with respect to multiple diversity metrics, showing that our architectural choices and the use of MENTOR benefit training a fair and unbiased model at scale. Finally we show applications in video editing and personalization.
Score Distillation Sampling with Learned Manifold Corrective
Jan 10, 2024



Score Distillation Sampling (SDS) is a recent but already widely popular method that relies on an image diffusion model to control optimization problems using text prompts. In this paper, we conduct an in-depth analysis of the SDS loss function, identify an inherent problem with its formulation, and propose a surprisingly easy but effective fix. Specifically, we decompose the loss into different factors and isolate the component responsible for noisy gradients. In the original formulation, high text guidance is used to account for the noise, leading to unwanted side effects. Instead, we train a shallow network mimicking the timestep-dependent denoising deficiency of the image diffusion model in order to effectively factor it out. We demonstrate the versatility and the effectiveness of our novel loss formulation through several qualitative and quantitative experiments, including optimization-based image synthesis and editing, zero-shot image translation network training, and text-to-3D synthesis.
SPHEAR: Spherical Head Registration for Complete Statistical 3D Modeling
Nov 04, 2023



We present \emph{SPHEAR}, an accurate, differentiable parametric statistical 3D human head model, enabled by a novel 3D registration method based on spherical embeddings. We shift the paradigm away from the classical Non-Rigid Registration methods, which operate under various surface priors, increasing reconstruction fidelity and minimizing required human intervention. Additionally, SPHEAR is a \emph{complete} model that allows not only to sample diverse synthetic head shapes and facial expressions, but also gaze directions, high-resolution color textures, surface normal maps, and hair cuts represented in detail, as strands. SPHEAR can be used for automatic realistic visual data generation, semantic annotation, and general reconstruction tasks. Compared to state-of-the-art approaches, our components are fast and memory efficient, and experiments support the validity of our design choices and the accuracy of registration, reconstruction and generation techniques.
DreamHuman: Animatable 3D Avatars from Text
Jun 15, 2023



We present DreamHuman, a method to generate realistic animatable 3D human avatar models solely from textual descriptions. Recent text-to-3D methods have made considerable strides in generation, but are still lacking in important aspects. Control and often spatial resolution remain limited, existing methods produce fixed rather than animated 3D human models, and anthropometric consistency for complex structures like people remains a challenge. DreamHuman connects large text-to-image synthesis models, neural radiance fields, and statistical human body models in a novel modeling and optimization framework. This makes it possible to generate dynamic 3D human avatars with high-quality textures and learned, instance-specific, surface deformations. We demonstrate that our method is capable to generate a wide variety of animatable, realistic 3D human models from text. Our 3D models have diverse appearance, clothing, skin tones and body shapes, and significantly outperform both generic text-to-3D approaches and previous text-based 3D avatar generators in visual fidelity. For more results and animations please check our website at https://dream-human.github.io.
PhoMoH: Implicit Photorealistic 3D Models of Human Heads
Dec 14, 2022
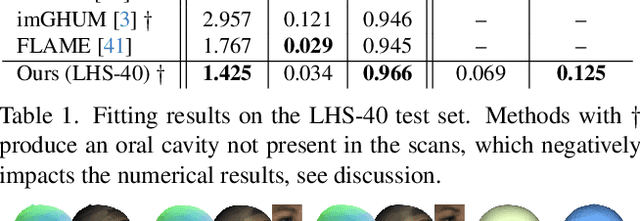


We present PhoMoH, a neural network methodology to construct generative models of photorealistic 3D geometry and appearance of human heads including hair, beards, clothing and accessories. In contrast to prior work, PhoMoH models the human head using neural fields, thus supporting complex topology. Instead of learning a head model from scratch, we propose to augment an existing expressive head model with new features. Concretely, we learn a highly detailed geometry network layered on top of a mid-resolution head model together with a detailed, local geometry-aware, and disentangled color field. Our proposed architecture allows us to learn photorealistic human head models from relatively little data. The learned generative geometry and appearance networks can be sampled individually and allow the creation of diverse and realistic human heads. Extensive experiments validate our method qualitatively and across different metrics.
Structured 3D Features for Reconstructing Relightable and Animatable Avatars
Dec 13, 2022



We introduce Structured 3D Features, a model based on a novel implicit 3D representation that pools pixel-aligned image features onto dense 3D points sampled from a parametric, statistical human mesh surface. The 3D points have associated semantics and can move freely in 3D space. This allows for optimal coverage of the person of interest, beyond just the body shape, which in turn, additionally helps modeling accessories, hair, and loose clothing. Owing to this, we present a complete 3D transformer-based attention framework which, given a single image of a person in an unconstrained pose, generates an animatable 3D reconstruction with albedo and illumination decomposition, as a result of a single end-to-end model, trained semi-supervised, and with no additional postprocessing. We show that our S3F model surpasses the previous state-of-the-art on various tasks, including monocular 3D reconstruction, as well as albedo and shading estimation. Moreover, we show that the proposed methodology allows novel view synthesis, relighting, and re-posing the reconstruction, and can naturally be extended to handle multiple input images (e.g. different views of a person, or the same view, in different poses, in video). Finally, we demonstrate the editing capabilities of our model for 3D virtual try-on applications.
Photorealistic Monocular 3D Reconstruction of Humans Wearing Clothing
Apr 19, 2022
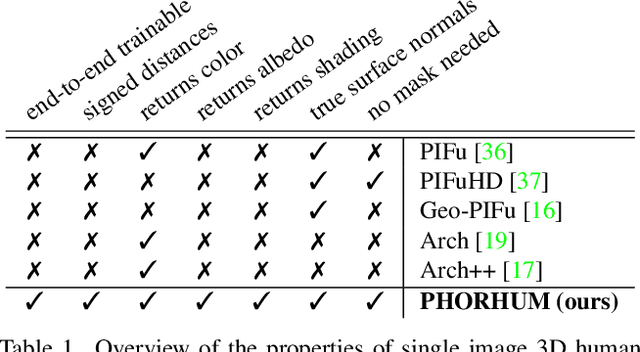
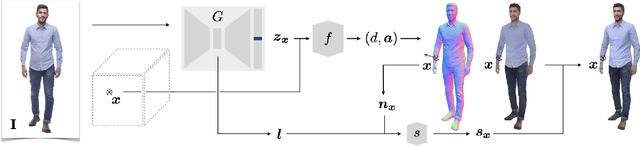
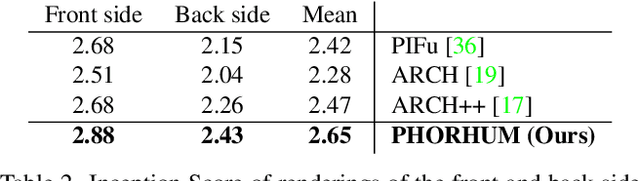
We present PHORHUM, a novel, end-to-end trainable, deep neural network methodology for photorealistic 3D human reconstruction given just a monocular RGB image. Our pixel-aligned method estimates detailed 3D geometry and, for the first time, the unshaded surface color together with the scene illumination. Observing that 3D supervision alone is not sufficient for high fidelity color reconstruction, we introduce patch-based rendering losses that enable reliable color reconstruction on visible parts of the human, and detailed and plausible color estimation for the non-visible parts. Moreover, our method specifically addresses methodological and practical limitations of prior work in terms of representing geometry, albedo, and illumination effects, in an end-to-end model where factors can be effectively disentangled. In extensive experiments, we demonstrate the versatility and robustness of our approach. Our state-of-the-art results validate the method qualitatively and for different metrics, for both geometric and color reconstruction.
H-NeRF: Neural Radiance Fields for Rendering and Temporal Reconstruction of Humans in Motion
Nov 02, 2021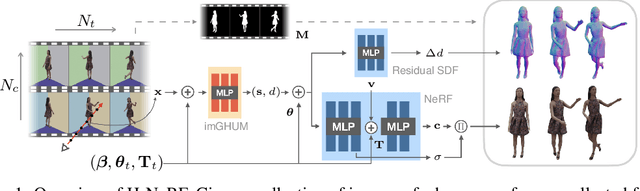
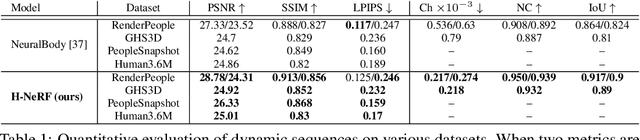
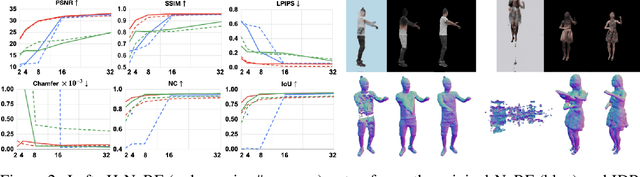
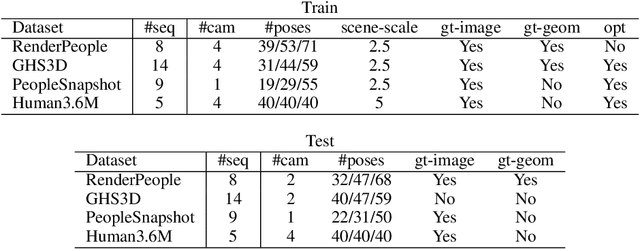
We present neural radiance fields for rendering and temporal (4D) reconstruction of humans in motion (H-NeRF), as captured by a sparse set of cameras or even from a monocular video. Our approach combines ideas from neural scene representation, novel-view synthesis, and implicit statistical geometric human representations, coupled using novel loss functions. Instead of learning a radiance field with a uniform occupancy prior, we constrain it by a structured implicit human body model, represented using signed distance functions. This allows us to robustly fuse information from sparse views and generalize well beyond the poses or views observed in training. Moreover, we apply geometric constraints to co-learn the structure of the observed subject -- including both body and clothing -- and to regularize the radiance field to geometrically plausible solutions. Extensive experiments on multiple datasets demonstrate the robustness and the accuracy of our approach, its generalization capabilities significantly outside a small training set of poses and views, and statistical extrapolation beyond the observed shape.