 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHFM: A Unified Video Foundation Model for 4D Human Perception and Beyond
Mar 26, 2026We present THFM, a unified video foundation model for human-centric perception that jointly addresses dense tasks (depth, normals, segmentation, dense pose) and sparse tasks (2d/3d keypoint estimation) within a single architecture. THFM is derived from a pretrained text-to-video diffusion model, repurposed as a single-forward-pass perception model and augmented with learnable tokens for sparse predictions. Modulated by the text prompt, our single unified model is capable of performing various perception tasks. Crucially, our model is on-par or surpassing state-of-the-art specialized models on a variety of benchmarks despite being trained exclusively on synthetic data (i.e.~without training on real-world or benchmark specific data). We further highlight intriguing emergent properties of our model, which we attribute to the underlying diffusion-based video representation. For example, our model trained on videos with a single human in the scene generalizes to multiple humans and other object classes such as anthropomorphic characters and animals -- a capability that hasn't been demonstrated in the past.
DiffHuman: Probabilistic Photorealistic 3D Reconstruction of Humans
Mar 30, 2024

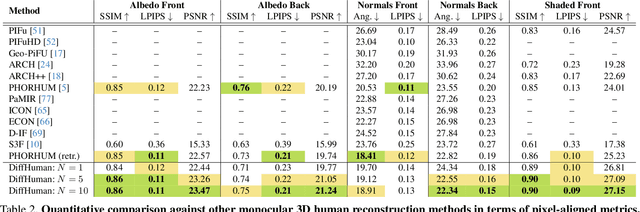

We present DiffHuman, a probabilistic method for photorealistic 3D human reconstruction from a single RGB image. Despite the ill-posed nature of this problem, most methods are deterministic and output a single solution, often resulting in a lack of geometric detail and blurriness in unseen or uncertain regions. In contrast, DiffHuman predicts a probability distribution over 3D reconstructions conditioned on an input 2D image, which allows us to sample multiple detailed 3D avatars that are consistent with the image. DiffHuman is implemented as a conditional diffusion model that denoises pixel-aligned 2D observations of an underlying 3D shape representation. During inference, we may sample 3D avatars by iteratively denoising 2D renders of the predicted 3D representation. Furthermore, we introduce a generator neural network that approximates rendering with considerably reduced runtime (55x speed up), resulting in a novel dual-branch diffusion framework. Our experiments show that DiffHuman can produce diverse and detailed reconstructions for the parts of the person that are unseen or uncertain in the input image, while remaining competitive with the state-of-the-art when reconstructing visible surfaces.
VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
Mar 13, 2024We propose VLOGGER, a method for audio-driven human video generation from a single input image of a person, which builds on the success of recent generative diffusion models. Our method consists of 1) a stochastic human-to-3d-motion diffusion model, and 2) a novel diffusion-based architecture that augments text-to-image models with both spatial and temporal controls. This supports the generation of high quality video of variable length, easily controllable through high-level representations of human faces and bodies. In contrast to previous work, our method does not require training for each person, does not rely on face detection and cropping, generates the complete image (not just the face or the lips), and considers a broad spectrum of scenarios (e.g. visible torso or diverse subject identities) that are critical to correctly synthesize humans who communicate. We also curate MENTOR, a new and diverse dataset with 3d pose and expression annotations, one order of magnitude larger than previous ones (800,000 identities) and with dynamic gestures, on which we train and ablate our main technical contributions. VLOGGER outperforms state-of-the-art methods in three public benchmarks, considering image quality, identity preservation and temporal consistency while also generating upper-body gestures. We analyze the performance of VLOGGER with respect to multiple diversity metrics, showing that our architectural choices and the use of MENTOR benefit training a fair and unbiased model at scale. Finally we show applications in video editing and personalization.
SPHEAR: Spherical Head Registration for Complete Statistical 3D Modeling
Nov 04, 2023



We present \emph{SPHEAR}, an accurate, differentiable parametric statistical 3D human head model, enabled by a novel 3D registration method based on spherical embeddings. We shift the paradigm away from the classical Non-Rigid Registration methods, which operate under various surface priors, increasing reconstruction fidelity and minimizing required human intervention. Additionally, SPHEAR is a \emph{complete} model that allows not only to sample diverse synthetic head shapes and facial expressions, but also gaze directions, high-resolution color textures, surface normal maps, and hair cuts represented in detail, as strands. SPHEAR can be used for automatic realistic visual data generation, semantic annotation, and general reconstruction tasks. Compared to state-of-the-art approaches, our components are fast and memory efficient, and experiments support the validity of our design choices and the accuracy of registration, reconstruction and generation techniques.
Blendshapes GHUM: Real-time Monocular Facial Blendshape Prediction
Sep 11, 2023We present Blendshapes GHUM, an on-device ML pipeline that predicts 52 facial blendshape coefficients at 30+ FPS on modern mobile phones, from a single monocular RGB image and enables facial motion capture applications like virtual avatars. Our main contributions are: i) an annotation-free offline method for obtaining blendshape coefficients from real-world human scans, ii) a lightweight real-time model that predicts blendshape coefficients based on facial landmarks.
DreamHuman: Animatable 3D Avatars from Text
Jun 15, 2023



We present DreamHuman, a method to generate realistic animatable 3D human avatar models solely from textual descriptions. Recent text-to-3D methods have made considerable strides in generation, but are still lacking in important aspects. Control and often spatial resolution remain limited, existing methods produce fixed rather than animated 3D human models, and anthropometric consistency for complex structures like people remains a challenge. DreamHuman connects large text-to-image synthesis models, neural radiance fields, and statistical human body models in a novel modeling and optimization framework. This makes it possible to generate dynamic 3D human avatars with high-quality textures and learned, instance-specific, surface deformations. We demonstrate that our method is capable to generate a wide variety of animatable, realistic 3D human models from text. Our 3D models have diverse appearance, clothing, skin tones and body shapes, and significantly outperform both generic text-to-3D approaches and previous text-based 3D avatar generators in visual fidelity. For more results and animations please check our website at https://dream-human.github.io.
HUM3DIL: Semi-supervised Multi-modal 3D Human Pose Estimation for Autonomous Driving
Dec 15, 2022Autonomous driving is an exciting new industry, posing important research questions. Within the perception module, 3D human pose estimation is an emerging technology, which can enable the autonomous vehicle to perceive and understand the subtle and complex behaviors of pedestrians. While hardware systems and sensors have dramatically improved over the decades -- with cars potentially boasting complex LiDAR and vision systems and with a growing expansion of the available body of dedicated datasets for this newly available information -- not much work has been done to harness these novel signals for the core problem of 3D human pose estimation. Our method, which we coin HUM3DIL (HUMan 3D from Images and LiDAR), efficiently makes use of these complementary signals, in a semi-supervised fashion and outperforms existing methods with a large margin. It is a fast and compact model for onboard deployment. Specifically, we embed LiDAR points into pixel-aligned multi-modal features, which we pass through a sequence of Transformer refinement stages. Quantitative experiments on the Waymo Open Dataset support these claims, where we achieve state-of-the-art results on the task of 3D pose estimation.
Structured 3D Features for Reconstructing Relightable and Animatable Avatars
Dec 13, 2022



We introduce Structured 3D Features, a model based on a novel implicit 3D representation that pools pixel-aligned image features onto dense 3D points sampled from a parametric, statistical human mesh surface. The 3D points have associated semantics and can move freely in 3D space. This allows for optimal coverage of the person of interest, beyond just the body shape, which in turn, additionally helps modeling accessories, hair, and loose clothing. Owing to this, we present a complete 3D transformer-based attention framework which, given a single image of a person in an unconstrained pose, generates an animatable 3D reconstruction with albedo and illumination decomposition, as a result of a single end-to-end model, trained semi-supervised, and with no additional postprocessing. We show that our S3F model surpasses the previous state-of-the-art on various tasks, including monocular 3D reconstruction, as well as albedo and shading estimation. Moreover, we show that the proposed methodology allows novel view synthesis, relighting, and re-posing the reconstruction, and can naturally be extended to handle multiple input images (e.g. different views of a person, or the same view, in different poses, in video). Finally, we demonstrate the editing capabilities of our model for 3D virtual try-on applications.
BlazePose GHUM Holistic: Real-time 3D Human Landmarks and Pose Estimation
Jun 23, 2022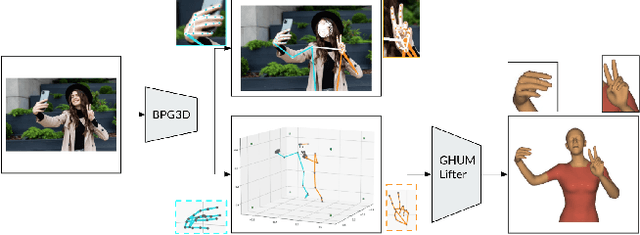
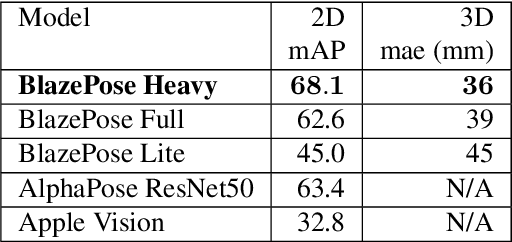
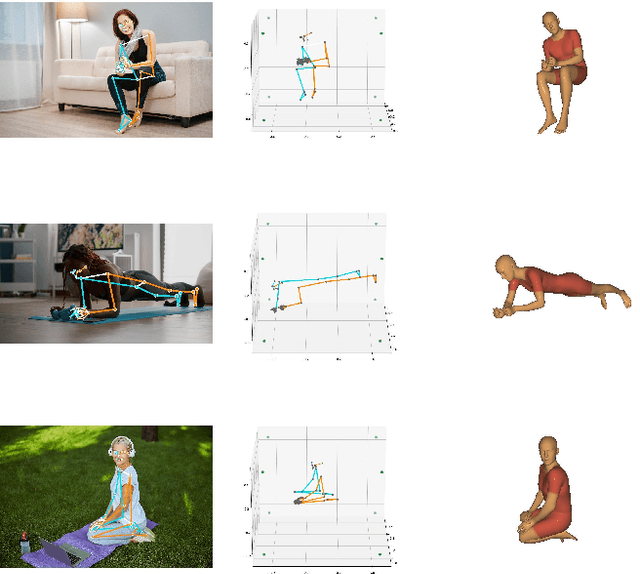
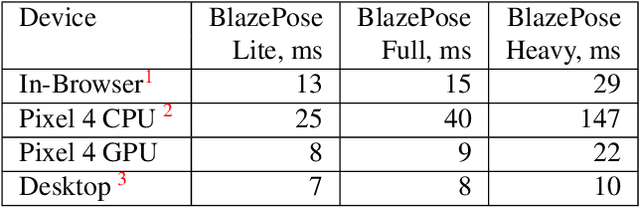
We present BlazePose GHUM Holistic, a lightweight neural network pipeline for 3D human body landmarks and pose estimation, specifically tailored to real-time on-device inference. BlazePose GHUM Holistic enables motion capture from a single RGB image including avatar control, fitness tracking and AR/VR effects. Our main contributions include i) a novel method for 3D ground truth data acquisition, ii) updated 3D body tracking with additional hand landmarks and iii) full body pose estimation from a monocular image.
HSPACE: Synthetic Parametric Humans Animated in Complex Environments
Jan 06, 2022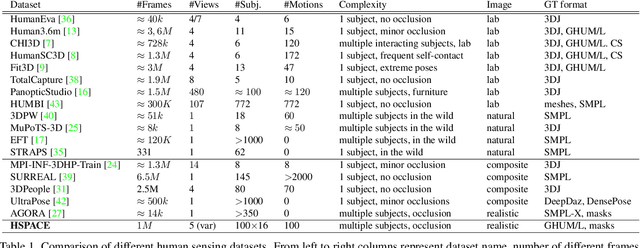
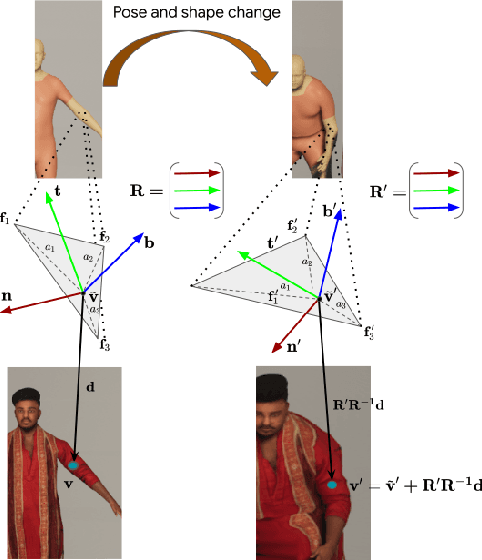
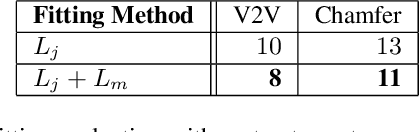
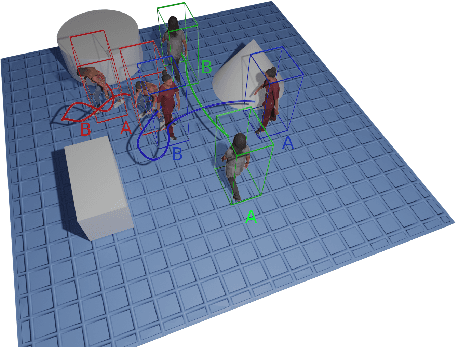
Advances in the state of the art for 3d human sensing are currently limited by the lack of visual datasets with 3d ground truth, including multiple people, in motion, operating in real-world environments, with complex illumination or occlusion, and potentially observed by a moving camera. Sophisticated scene understanding would require estimating human pose and shape as well as gestures, towards representations that ultimately combine useful metric and behavioral signals with free-viewpoint photo-realistic visualisation capabilities. To sustain progress, we build a large-scale photo-realistic dataset, Human-SPACE (HSPACE), of animated humans placed in complex synthetic indoor and outdoor environments. We combine a hundred diverse individuals of varying ages, gender, proportions, and ethnicity, with hundreds of motions and scenes, as well as parametric variations in body shape (for a total of 1,600 different humans), in order to generate an initial dataset of over 1 million frames. Human animations are obtained by fitting an expressive human body model, GHUM, to single scans of people, followed by novel re-targeting and positioning procedures that support the realistic animation of dressed humans, statistical variation of body proportions, and jointly consistent scene placement of multiple moving people. Assets are generated automatically, at scale, and are compatible with existing real time rendering and game engines. The dataset with evaluation server will be made available for research. Our large-scale analysis of the impact of synthetic data, in connection with real data and weak supervision, underlines the considerable potential for continuing quality improvements and limiting the sim-to-real gap, in this practical setting, in connection with increased model capacity.